
Vous avez suivi les rumeurs et ignoré le battage médiatique; vous avez attendu les examens et examiné tous les points de repère. Enfin, vous avez dépensé de l'argent et récupéré l'une des dernières cartes graphiques d'AMD ou de Nvidia. À l'intérieur, se trouve un grand processeur graphique, doté de milliards de transistors, fonctionnant à une vitesse d'horloge impensable il y a une décennie.
Vous êtes vraiment content de votre achat et les jeux n'ont jamais été aussi beaux et mieux joués. Mais vous vous demandez peut-être ce qui alimente votre toute nouvelle Radeon RX 5700 et quelle est sa différence avec la puce d’une GeForce RTX.
Bienvenue dans notre comparaison architecturale et fonctionnelle des nouveaux processeurs graphiques d'AMD et de Nvidia: Navi vs Turing.
Anatomie d'un GPU moderne
Avant de commencer notre analyse détaillée de la structure et des systèmes de la puce, examinons le format de base suivi par tous les GPU modernes. Pour la plupart, ces processeurs ne sont que des calculatrices à virgule flottante (FP); autrement dit, ils effectuent des opérations mathématiques sur des valeurs décimales / fractionnaires. Donc, à tout le moins, un GPU doit avoir une unité logique dédiée à ces tâches et on les appelle généralement ALU FP (unités logiques arithmétiques en virgule flottante) ou FPU pour faire court. Tous les calculs effectués par les GPU ne portent pas sur des valeurs de données de PF, il y aura donc également une ALU pour un nombre entier (entier) opérations mathématiques ou il peut même s'agir de la même unité, qui gère uniquement les deux types de données.
Maintenant, ces unités logiques vont avoir besoin de quelque chose pour les organiser, en décodant et en donnant des instructions pour les garder occupées, et cela se présentera sous la forme d'au moins un groupe dédié d'unités logiques. Contrairement aux ALU, elles ne seront pas programmables par l'utilisateur final; Au lieu de cela, le fournisseur de matériel s'assurera que ce processus est entièrement géré par le GPU et ses pilotes.
Pour stocker ces instructions et les données à traiter, il doit également exister une sorte de structure de mémoire. Au niveau le plus simple, il se présentera sous deux formes: cache et une tache de mémoire locale. Le premier sera intégré au GPU lui-même et sera SRAM. Ce type de mémoire est rapide mais occupe une quantité relativement importante de la structure du processeur. La mémoire locale sera DRACHME, qui est un peu plus lent que la SRAM et ne sera normalement pas inséré dans le GPU lui-même. La plupart des cartes graphiques que nous voyons aujourd’hui ont une mémoire locale sous forme de GDDR Modules de DRAM.
Enfin, le rendu graphique 3D implique des tâches supplémentaires, telles que la formation de triangles à partir de sommets, la pixellisation d'une image 3D, l'échantillonnage et le mélange de textures, etc. Comme les unités d’instruction et de contrôle, elles sont fonction fixe dans la nature. Ce qu’ils font et comment ils fonctionnent est complètement transparent pour les utilisateurs qui programment et utilisent le GPU.
Mettons cela ensemble et faisons un GPU:
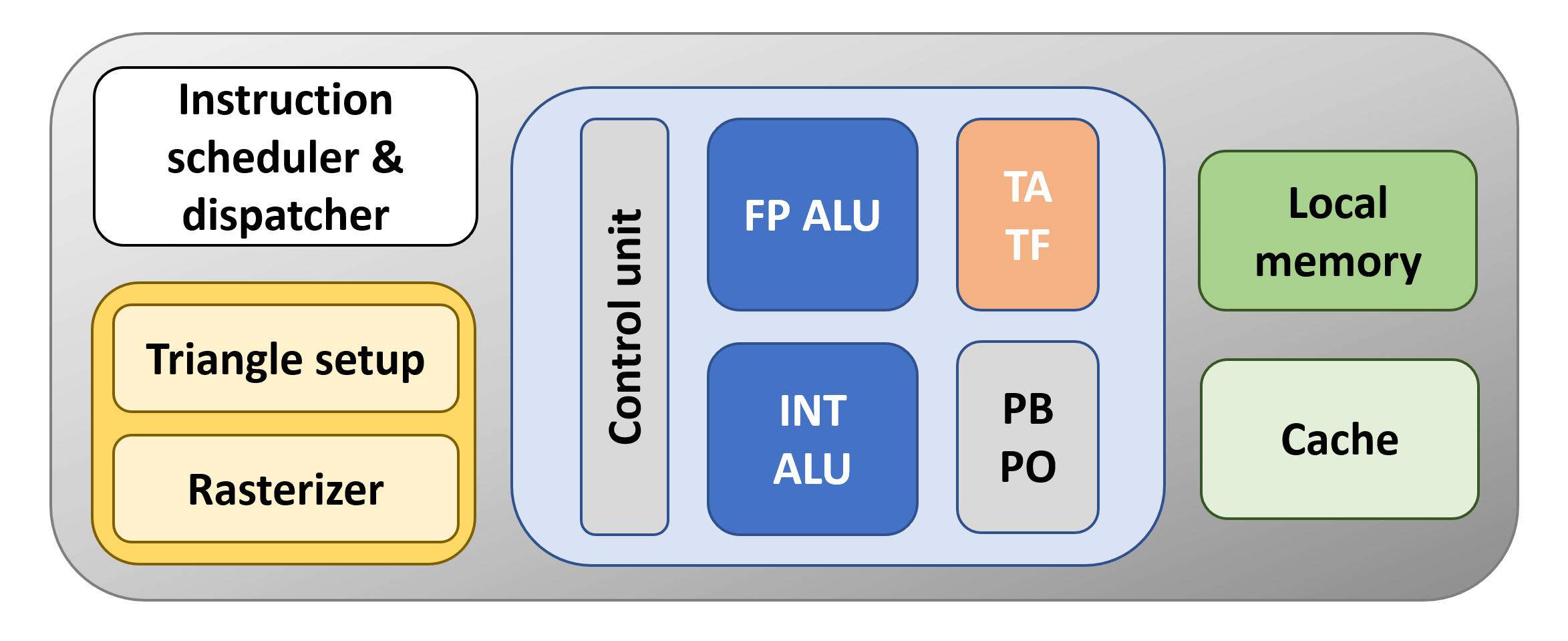
Le bloc orange est l’unité qui gère les textures en utilisant ce que l’on appelle unités de cartographie de texture (TMUs) – TA est le adressage de texture unité – crée les emplacements de mémoire pour le cache et la mémoire locale à utiliser – et TF est le texture chercher unité qui collecte les valeurs de texture de la mémoire et les mélange. De nos jours, les TMU sont à peu près les mêmes pour tous les fournisseurs, en ce sens qu'ils peuvent adresser, échantillonner et mélanger plusieurs valeurs de texture par cycle d'horloge du GPU.
Le bloc situé en dessous écrit les valeurs de couleur des pixels de la trame, les rééchantille (PO) et les mélange (PB); Ce bloc effectue également des opérations utilisées lorsque l'anti-aliasing est utilisé. Le nom de ce bloc est rendre l'unité de sortie ou rendre backend (ROP / RB pour faire court). Comme le TMU, ils sont maintenant assez standardisés, chacun gérant facilement plusieurs pixels par cycle d'horloge.
Notre GPU de base serait affreux, même selon les normes d'il y a 13 ans. Pourquoi?
Il n'y a qu'un FPU, un TMU et un ROP. Les processeurs graphiques en 2006, tels que la GeForce 8800 GTX de Nvidia, en possédaient respectivement 128, 32 et 24. Alors commençons à faire quelque chose à ce sujet …
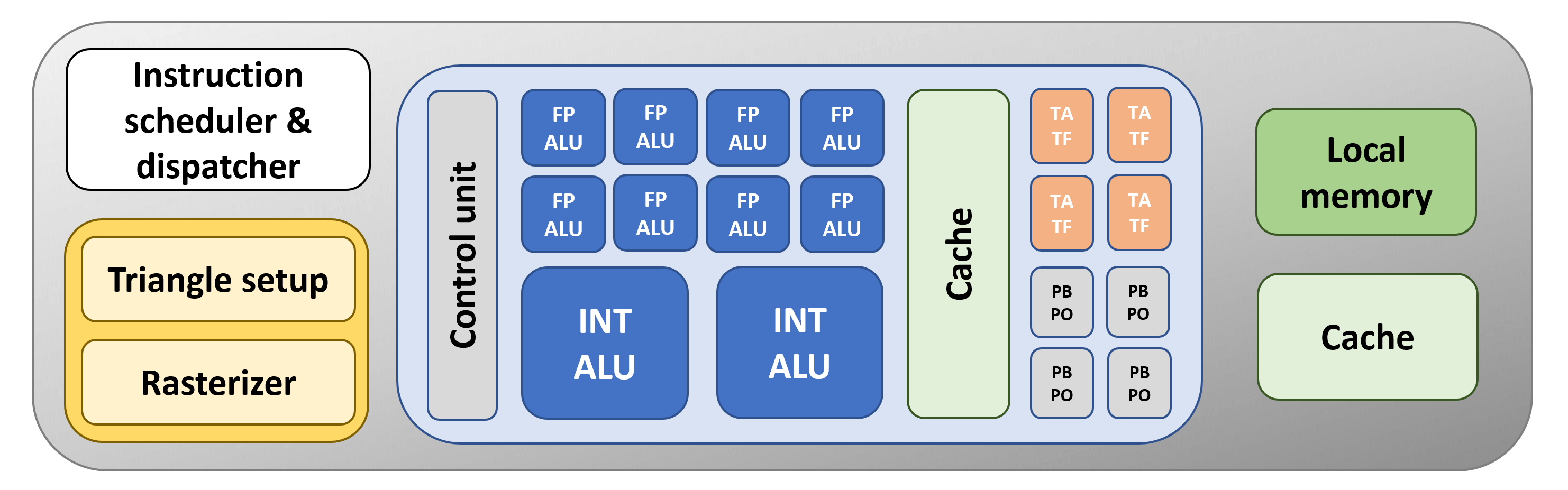
Comme tout bon fabricant de processeurs, nous avons mis à jour notre GPU en ajoutant quelques unités supplémentaires. Cela signifie que la puce pourra traiter plusieurs instructions simultanément. Pour vous aider, nous avons également ajouté un peu plus de cache, mais cette fois-ci, juste à côté des unités logiques. Plus le cache est proche d'une structure de calculatrice, plus vite elle pourra se lancer dans les opérations qui lui sont données.
Le problème avec notre nouvelle conception est qu’il n’ya toujours qu’une seule unité de contrôle pour gérer nos ALU supplémentaires. Ce serait mieux si nous avions plus de blocs d'unités, tous gérés par leur propre contrôleur, car cela signifierait que nous pourrions avoir des opérations très différentes en même temps.
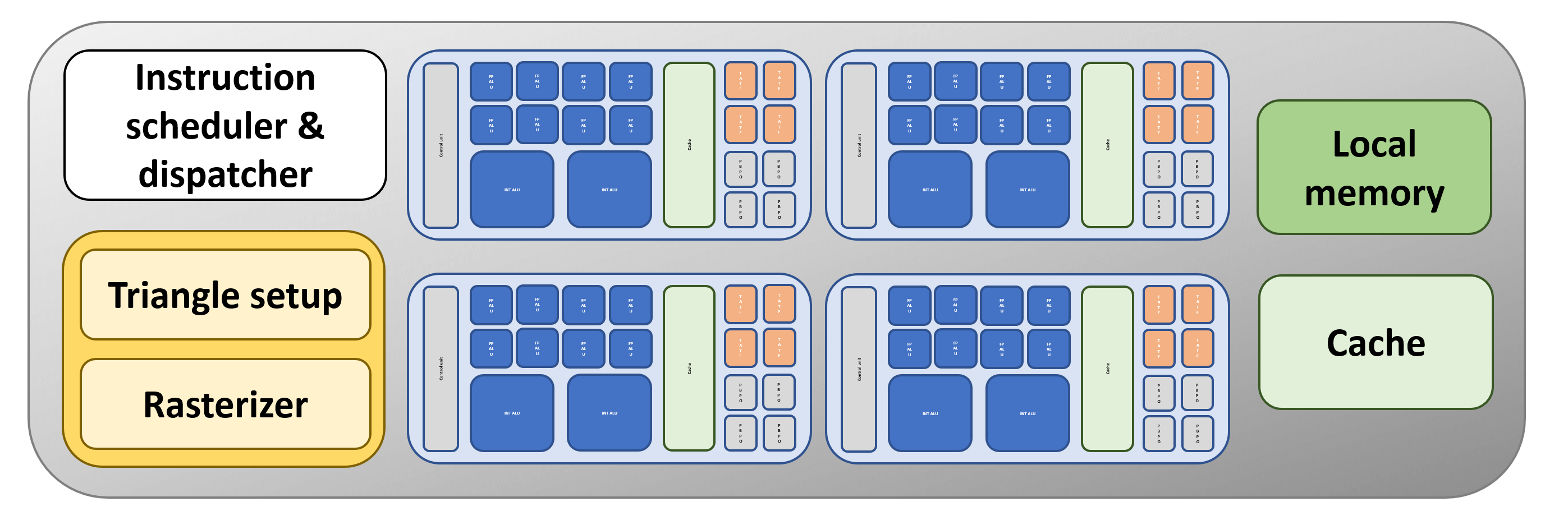
Maintenant, c'est plus comme ça! Blocs ALU séparés, contenant leurs propres TMU et ROP, et pris en charge par des tranches dédiées de mémoire cache savoureuse et rapide. Il n'y a toujours qu'un seul élément parmi d'autres, mais la structure de base n'est pas éloignée du processeur graphique utilisé actuellement sur les ordinateurs de bureau et les consoles.
Navi et Turing: GPU Godzilla
Maintenant que nous avons décrit la structure de base d’une puce graphique, commençons notre comparaison Navi contre Turing avec certaines images des puces réelles, bien qu’elles soient légèrement agrandies et traitées pour mettre en évidence les différentes structures.
À gauche, le processeur le plus récent d'AMD. La conception générale de la puce s'appelle Navi (certains l'appellent Navi 10) et l'architecture graphique s'appelle RDNA. À côté, à droite, se trouve le processeur TU102 de taille réelle de Nvidia, doté de la dernière architecture de Turing. Il est important de noter que ces images ne sont pas à l'échelle: la matrice Navi a une surface de 251 mm2, tandis que la TU102 mesure 752 mm2. Le processeur Nvidia est gros, mais il n’est pas 8 fois plus grand que l’offre AMD!

Ils emballent tous les deux un gargantuesque nombre de transistors (10,3 vs 18,6 milliards) mais le TU102 a une moyenne de ~ 25 millions de transistors par mm carré par rapport à 41 millions de Navi par mm carré.
En effet, bien que les deux puces soient fabriquées par TSMC, elles sont fabriquées sur différents nœuds de processus: Turing de Nvidia fait partie de la chaîne de fabrication mature à 12 nm, tandis que la Navi d’AMD est fabriquée sur le nouveau nœud à 7 nm.
Le simple fait de regarder les images des puces ne nous en dit pas beaucoup sur les architectures, jetons donc un coup d'œil aux schémas de principe GPU produits par les deux sociétés.
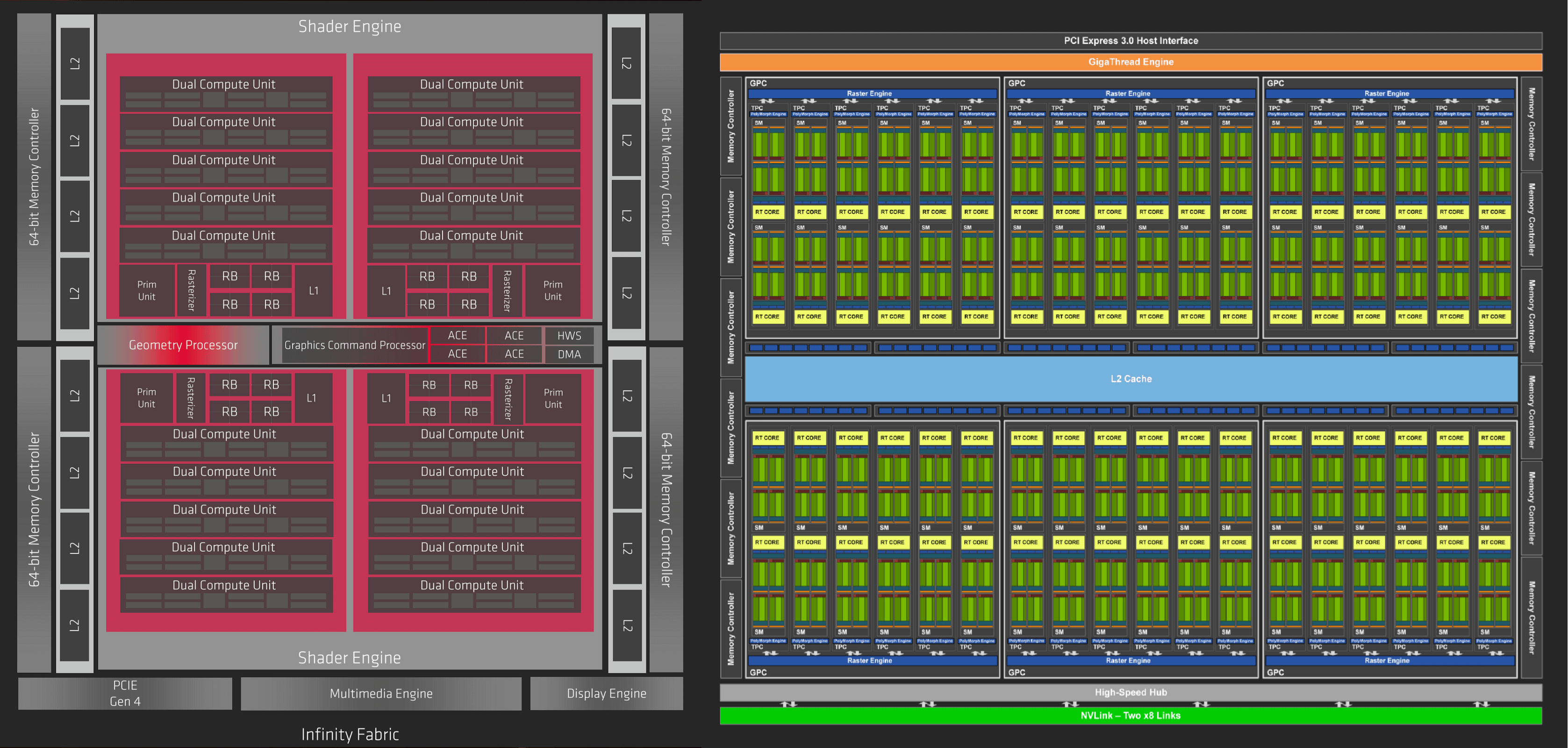
Les diagrammes ne sont pas censés être une représentation 100% réaliste des dispositions réelles, mais si vous les faites pivoter de 90 degrés, les différents blocs et la bande centrale qui apparaissent dans les deux peuvent être identifiés. Pour commencer, nous pouvons voir que les deux GPU ont une structure globale comme la nôtre (mais avec plus de tout!).
Les deux conceptions suivent une approche hiérarchisée de la manière dont tout est organisé et groupé – pour commencer avec Navi, le GPU est construit à partir de 2 blocs appelés par AMD. Moteurs Shader (SE), qui sont chacun divisés en 2 autres blocs appelés Asynchrone Calculer les moteurs (ACE). Chacun de ceux-ci comprend 5 blocs, intitulés Processeurs de groupe de travail (WGP), qui se composent de 2 Unités de calcul (UC)
Pour la conception de Turing, les noms et les numéros sont différents, mais la hiérarchie est très similaire: 6 Grappes de traitement graphique (GPC), chacun avec 6 Grappes de traitement de texture (TPC), chacun de ceux-ci étant constitué de 2 Streaming multiprocesseur (SM) des blocs.
Si vous imaginez un processeur graphique comme une grande usine, où différentes sections fabriquent des produits différents, en utilisant les mêmes matières premières, cette organisation commence à avoir un sens. Le PDG de l'usine envoie à l'entreprise tous les détails opérationnels, qui sont ensuite divisés en diverses tâches et charges de travail. En ayant plusieurs, indépendant sections à l'usine, l'efficacité de la main-d'œuvre est améliorée. Pour les GPU, ce n'est pas différent et le mot clé magique est ordonnancement.
Front and Center, Soldier – Calendrier et expédition
Lorsque nous avons examiné le fonctionnement du rendu de jeu en 3D, nous avons constaté qu'un processeur graphique n'était en réalité qu'une calculatrice ultra-rapide, effectuant toute une gamme d'opérations mathématiques sur des millions de données. Navi et Turing sont classés comme Instruction unique Données multiples Processeurs (SIMD), même si une meilleure description serait Single Instruction Multiple Les fils (SIMT).
Un jeu 3D moderne génère des centaines de threads, parfois des milliers, car le nombre de sommets et de pixels à traiter est énorme. Pour que toutes les opérations soient terminées en quelques microsecondes, il est important que le plus grand nombre d'unités logiques soit aussi occupé que possible, sans que tout ne bouge, car les données nécessaires ne sont pas au bon endroit ou il n'y a pas assez de ressources pour fonctionner. dans.
Lorsque nous avons examiné le fonctionnement du rendu de jeu en 3D, nous avons constaté qu'un processeur graphique n'était en réalité qu'une calculatrice ultra-rapide, effectuant toute une gamme d'opérations mathématiques sur des millions de données. Navi et Turing sont classés dans la catégorie des processeurs SIMD (Single Instruction Multiple Data), mais une description plus précise serait SIMT (Single Instruction Multiple Threads).
Navi et Turing fonctionnent de la même manière: une unité centrale prend en charge tous les fils, puis commence à les planifier et à les émettre. Dans la puce AMD, ce rôle est assumé par le Processeur de commande graphique; chez Nvidia, c'est le Moteur GigaThread. Les threads sont organisés de manière à ce que ceux ayant les mêmes instructions soient regroupés, en particulier dans une collection de 32 threads.
AMD appelle cette collection un vague, alors que Nvidia l’appelle un chaîne. Pour Navi, une unité de calcul peut gérer 2 vagues (ou une vague de 64 threads, mais cela prend deux fois plus de temps), et à Turing, un multiprocesseur de streaming fonctionne sur 4 chaînes. Dans les deux conceptions, les ondes / chaînes sont indépendantes, c’est-à-dire qu’elles n’ont pas besoin des autres avant de pouvoir commencer.
Jusqu'à présent, il n'y a pas beaucoup de différence entre Navi et Turing: ils sont tous deux conçus pour gérer un grand nombre de threads, pour le rendu et le calcul des charges de travail. Nous devons examiner quels processus traitent ces threads pour voir où les deux géants du GPU se séparent dans la conception.
Une différence d'exécution – ARNr vs CUDA
AMD et Nvidia adoptent une approche très différente de leurs unités de shader unifiées, même si une grande partie de la terminologie utilisée semble être la même. Les unités d'exécution de Nvidia (CUDA noyaux) sont scalaire en nature – cela signifie qu'une unité effectue une opération mathématique sur un composant de données; en revanche, les unités d’AMD (Processeurs de flux) travailler sur vecteurs – une opération sur plusieurs composants de données. Pour les opérations scalaires, ils ont une seule unité dédiée.
Avant d'examiner de plus près les unités d'exécution, examinons les modifications apportées par AMD aux leurs. Depuis 7 ans, les cartes graphiques Radeon suivent une architecture appelée Graphics Core Next (GCN). Chaque nouvelle puce a révisé divers aspects de la conception, mais ils ont tous été fondamentalement les mêmes.
AMD a fourni un historique (très) bref de leur architecture GPU:
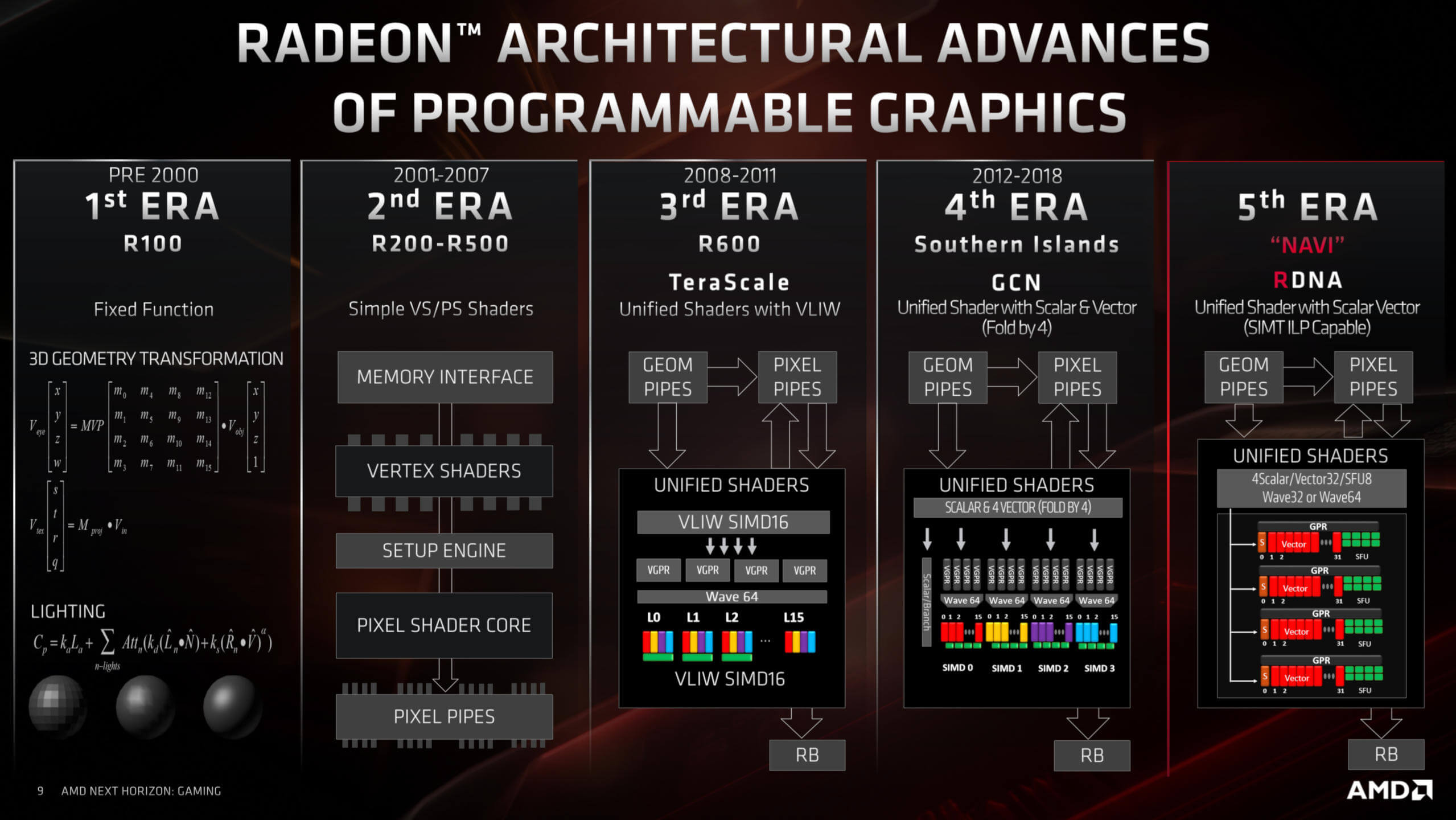
GCN était une évolution de TeraScale, une conception qui permettait de traiter les grandes vagues en même temps. Le problème principal avec TeraScale était qu’il n’était tout simplement pas très amical envers les programmeurs et qu’il nécessitait des routines très spécifiques pour en tirer le meilleur parti. GCN a résolu ce problème et fourni une plate-forme beaucoup plus accessible.
Les UC de Navi ont été considérablement révisées par rapport à GCN dans le cadre du processus d'amélioration d'AMD. Chaque UC contient deux ensembles de:
- 32 SP (ALU vectorielles IEE754 FP32 et INT32)
- 1 SFU
- 1 ALU scalaire INT32
- 1 unité de planification et d'expédition
Parallèlement à cela, chaque CU contient 4 unités de texture. Il y a d'autres unités à l'intérieur, pour gérer les données en lecture / écriture à partir du cache, mais elles ne sont pas montrées dans l'image ci-dessous:
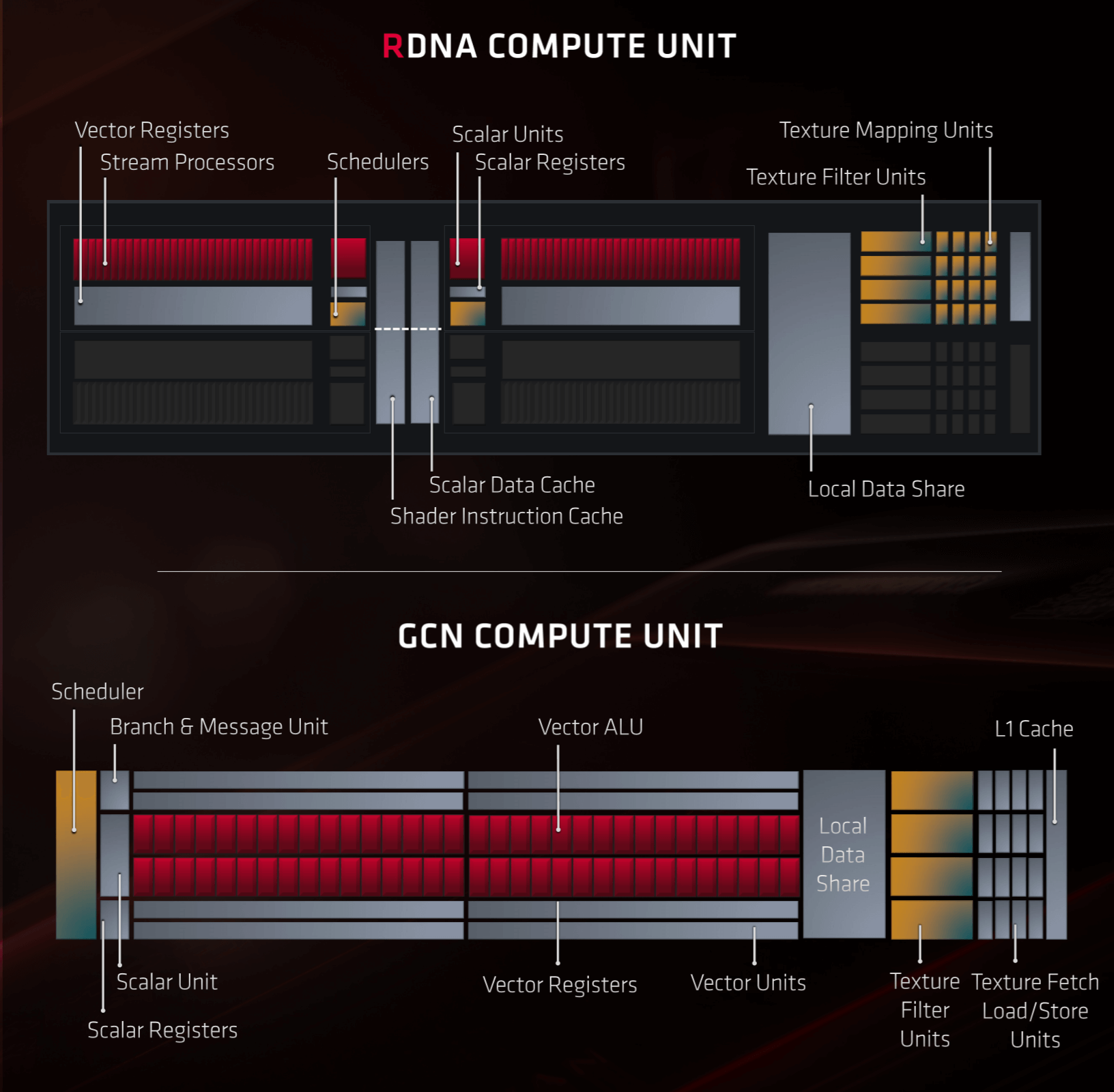
Par rapport à GCN, la configuration d’une unité RDNA CU peut ne pas sembler très différente, mais c’est la façon dont tout a été organisé et organisé qui est importante ici. Pour commencer, chaque ensemble de 32 SP a sa propre unité d’instruction dédiée, alors que GCN n’avait qu’une planification pour 4 ensembles de 16 SP.

Il s'agit d'un changement important car cela signifie qu'une onde de 32 threads peut être émise par cycle d'horloge pour chaque ensemble de SP. L’architecture RDNA permet également aux unités vectorielles de gérer des vagues de 16 threads deux fois plus rapidement et des vagues de 64 threads deux fois moins vite. Par conséquent, le code écrit pour toutes les cartes graphiques Radeon précédentes est toujours pris en charge.
Pour les développeurs de jeux, ces modifications vont devenir très populaires.
Pour les opérations scalaires, il y a maintenant deux fois plus d'unités pour les gérer. la seule réduction du nombre de composants est sous la forme de SFU – ceux-ci sont fonction spéciale des unités, qui effectuent des opérations mathématiques très spécifiques, par exemple trigonométrique (sinus, tangente), réciproque (1 divisé par un nombre) et racines carrées. Ils sont moins présents dans le RDNA que dans GCN, mais ils peuvent désormais fonctionner avec des ensembles de données deux fois plus volumineux qu’auparavant.
Pour les développeurs de jeux, ces modifications vont devenir très populaires. Les anciennes cartes graphiques Radeon offraient de nombreuses performances potentielles, mais il était notoirement difficile de les exploiter. Maintenant, AMD a fait un grand pas en avant dans la réduction du temps de latence dans les instructions de traitement et a également retenu des fonctionnalités permettant une compatibilité avec les versions antérieures de tous les programmes conçus pour l’architecture GCN.
Mais qu'en est-il du marché du graphisme professionnel ou du calcul? Ces changements sont-ils bénéfiques pour eux aussi?
La réponse courte serait oui (Probablement). Bien que la version actuelle de la puce Navi, comme celle de la Radeon RX 5700 XT, comporte moins de processeurs de flux que la précédente conception de Vega, nous avons constaté qu'elle surpassait assez facilement une Radeon RX Vega 56 de la génération précédente:
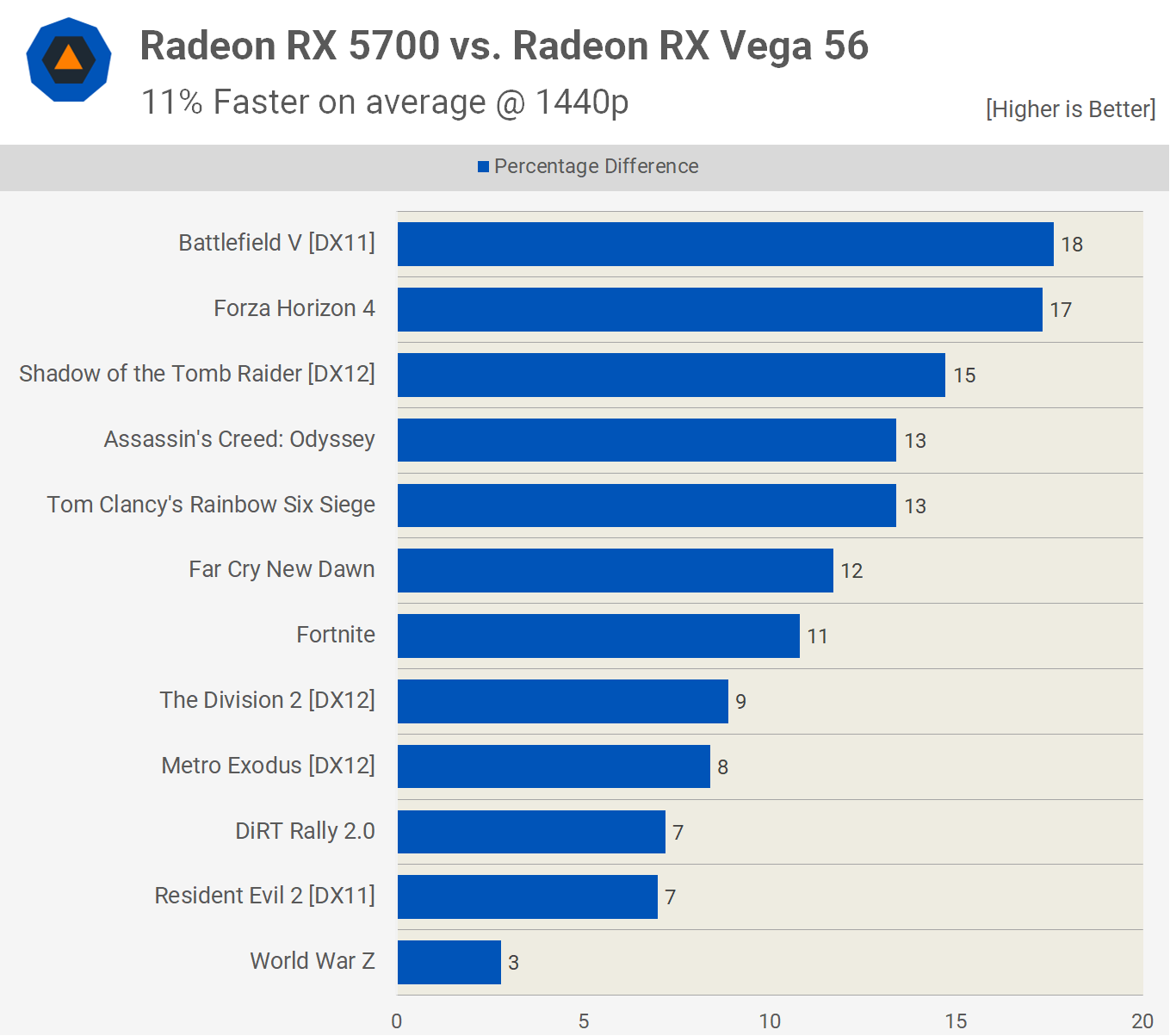
Une partie de ce gain de performance proviendra du taux d’horloge plus élevé du RX 5700 XT que celui du RX Vega 56 (pour qu’il puisse écrire plus de pixels par seconde dans la mémoire locale), mais les performances de pointe en nombre entier et en virgule flottante peuvent atteindre 15%. ; et pourtant, nous avons vu la puce Navi surpasser la Vega jusqu'à 18%.
Les programmes de rendu professionnels et les scientifiques qui exécutent des algorithmes complexes ne vont pas exploser quelques tours de Battlefield V dans leur travail (enfin, peut être…), mais si les opérations scalaires, vectorielles et matricielles effectuées dans un moteur de jeu sont traitées plus rapidement, cela se produit. devrait traduire sur le marché du calcul. À l'heure actuelle, nous ne savons pas quels sont les projets d'AMD concernant le marché professionnel. Ils pourraient bien continuer avec l'architecture Vega et continuer à affiner la conception, afin d'aider à la fabrication, mais étant donné les améliorations apportées à Navi, il est logique que l'entreprise déplacez tout sur la nouvelle architecture.
Le design du processeur graphique de Nvidia a connu une évolution similaire depuis le lancement de la série GeForce 8 en 2006, avec toutefois moins de changements radicaux qu’AMD. Ce GPU arborait l’architecture Tesla, l’un des premiers à utiliser une approche unifiée du shader pour l’architecture d’exécution. Ci-dessous, vous pouvez voir les modifications apportées aux blocs SM depuis le successeur de Tesla (Fermi) jusqu'au prédécesseur de Turing (Volta):

Comme mentionné précédemment dans cet article, les cœurs CUDA sont: scalaire. Ils peuvent exécuter une instruction flottante et une instruction entière par cycle d'horloge sur un composant de données (il faut noter que l'instruction elle-même peut prendre plusieurs cycles d'horloge), mais les unités de planification les organisent en groupes de telle sorte que, pour un programmeur, ils peuvent effectuer des opérations vectorielles. Le changement le plus important au cours des années, mis à part le nombre accru d'unités, concerne la manière dont elles sont organisées et divisées.
Dans la conception Kepler, la puce complète comportait 6 CPG, chacun contenant deux blocs SM; au moment de l'apparition de Volta, les CPG étaient divisés en sections distinctes (TPC) avec deux SM par TPC. Tout comme avec le design Navi. cette fragmentation est importante car elle permet au GPU global d'être utilisé au maximum. plusieurs groupes d'instructions indépendantes peuvent être traités en parallèle, augmentant ainsi les performances d'ombrage et de calcul du processeur.
Jetons un coup d'œil à l'équivalent de Turing à l'unité de calcul RDNA:

Un SM contient 4 blocs de traitement, chacun contenant:
- 1 unité de planification et de distribution des instructions
- 16 ALU scalaires IEE754 FP32
- 16 ALU scalaires INT32
- 2 noyaux de tenseur
- 4 SFU
- 4 unités de chargement / stockage (qui gèrent la lecture / écriture en cache)
Il existe également 2 unités FP64 par SM, mais Nvidia ne les affiche plus dans leurs diagrammes. Chaque SM contient 4 unités de texture (contenant des systèmes d’adressage et de filtrage de texturation) et 1 cœur RT (Ray Tracing).
Les ALU FP32 et INT32 peuvent fonctionner simultanément et en parallèle. Il s'agit d'une fonctionnalité importante car, même si les moteurs de rendu 3D nécessitent principalement des calculs en virgule flottante, il reste encore un nombre raisonnable d'opérations entières simples (par exemple, calculs d'adresse de données) à effectuer. Les unités SM de Turing offrent beaucoup plus de capacité pour les opérations INT32 scalaires que Navi. En effet, les unités CU de cette dernière ne possèdent qu'une seule unité INT32 scalaire, mais pour les opérations vectorielles FP32, plusieurs ALU doivent faire la même chose qu'un SP unique.
Les cœurs de tenseurs sont des ALU spécialisées qui gèrent les opérations de la matrice. Les matrices sont des matrices de données «carrées» et les cœurs Tensor fonctionnent sur des matrices 4 x 4. Ils sont conçus pour gérer les composants de données FP16, INT8 ou INT4 de telle sorte qu’au cours d’un cycle d’horloge, jusqu’à 64 opérations de flottement FMA (fusionné multiplication-puis-addition) se produisent. Ce type de calcul est couramment utilisé dans ce qu'on appelle les réseaux de neurones et l'inférence – pas vraiment très courante dans les jeux 3D, mais très utilisée par des goûts tels que Facebook pour leurs algorithmes d'analyse des médias sociaux ou dans des voitures équipées de systèmes d'auto-conduite. Navi est également capable de faire des calculs matriciels mais nécessite un grand nombre de SP pour le faire. Dans le système de Turing, les opérations de la matrice peuvent être effectuées pendant que les cœurs CUDA effectuent d'autres calculs.
Le RT Core est une autre unité spéciale, unique à l’architecture Turing, qui exécute des algorithmes mathématiques très spécifiques utilisés pour le système de traçage de rayons de Nvidia. Une analyse complète de cela dépasse le cadre de cet article, mais le RT Core est essentiellement constitué de deux systèmes fonctionnant séparément du reste du SM. Il peut donc toujours fonctionner sur des vertex ou des pixel shaders, alors que le RT Core est occupé à effectuer des calculs. pour lancer de rayons.
Sur un niveau fondamental, Navi et Turing ont des unités d’exécution offrant un ensemble de fonctionnalités raisonnablement similaires (nécessité née de la nécessité de se conformer aux exigences de Direct3D, OpenGL, etc.) mais …
Sur un niveau fondamental, Navi et Turing ont des unités d’exécution qui offrent un ensemble de fonctionnalités raisonnablement similaires (nécessité née de la nécessité de se conformer aux exigences de Direct3D, OpenGL, etc.), mais elles adoptent une approche très différente de la manière dont ces fonctionnalités sont. traité. En ce qui concerne la conception qui convient le mieux, tout dépend de la manière dont ils sont utilisés: un programme qui génère un grand nombre de threads effectuant des calculs vectoriels FP32 et qui ne semble guère favoriser Navi, alors qu'un programme avec une variété de calculs entiers, flottants, scalaires et vectoriels favoriserait la flexibilité de Turing, et ainsi de suite.
La hiérarchie de la mémoire
Les GPU modernes sont des processeurs de streaming, c'est-à-dire qu'ils sont conçus pour effectuer un ensemble d'opérations sur chaque élément d'un flux de données. Cela les rend moins flexibles qu'un processeur à usage général et exige également que la hiérarchie de la mémoire de la puce soit optimisée pour transmettre les données et les instructions aux ALU aussi rapidement que possible et sous autant de flux que possible. Cela signifie que les GPU auront moins de cache que de processeur, car une plus grande partie de la puce doit être dédiée à l'accès au cache, plutôt que la quantité de cache elle-même.
AMD et Nvidia recourent tous deux à l’utilisation de plusieurs niveaux de cache dans les puces, jetons donc un coup d’œil à ce que Navi emballe en premier.

À partir du niveau le plus bas dans la hiérarchie, les deux blocs de processeurs de flux utilisent un total de 256 kiB de registres vectoriels à usage général (généralement appelés registres). fichier de registre), soit le même montant que dans Vega, mais sur 4 blocs de SP; manquer de registres tout en essayant de traiter un grand nombre de threads nuit vraiment aux performances, c'est donc définitivement une "bonne chose". AMD a également considérablement augmenté le fichier de registre scalaire. Là où il n’était auparavant que de 4 Ko, il est maintenant de 32 Ko par unité scalaire.
Deux unités de calcul partagent alors un cache L0 d’instructions de 32 Ko et un cache de données scalaires de 16 Ko, mais chaque UC dispose de son propre cache L0 de vecteur de 32 Ko; La connexion de toute cette mémoire aux ALU est un partage de données local de 128 Ko.

Dans Navi, deux moteurs de calcul forment un processeur de groupe de travail, et cinq d'entre eux forment un moteur de calcul asynchrone (ACE). Chaque ACE a accès à son propre cache L1 de 128 Ko. L'ensemble du GPU est également pris en charge par 4 Mo de cache L2, interconnectés aux caches L1 et à d'autres sections du processeur.
Il s’agit presque certainement d’une forme d’architecture d’interconnexion Infinity Fabric d’AMD, le système étant définitivement utilisé pour gérer les 16 contrôleurs de mémoire GDDR6. Pour optimiser la bande passante de la mémoire, Navi utilise également une compression de couleur sans perte entre L1, L2 et la mémoire GDDR6 locale.

Encore une fois, tout cela est le bienvenu, surtout par rapport aux puces AMD précédentes qui ne disposaient pas d’un cache de bas niveau suffisant pour le nombre d’unités de shader qu’ils contenaient. En bref, plus de cache équivaut à plus de bande passante interne, moins d’instructions bloquées (car elles doivent extraire les données de la mémoire plus loin), etc. Et cela équivaut simplement à de meilleures performances.
En ce qui concerne la hiérarchie de Turing, force est de constater que Nvidia est timide lorsqu'il s'agit de fournir des informations détaillées dans ce domaine. Plus tôt dans cet article, nous avons vu que chaque SM était divisé en 4 blocs de traitement – chacun de ceux-ci avait un fichier de registre de 64 Ko, ce qui est plus petit que celui trouvé dans Navi, mais n'oubliez pas que les ALU de Turing sont scalaires et non vectorielles. , unités.

Ensuite, 96 Ko de mémoire partagée, pour chaque SM, pouvant être utilisés en tant que cache de données L1 de 64 Ko et mémoire cache de texture de 32 Ko ou espace de registre supplémentaire. En «mode de calcul», la mémoire partagée peut être partitionnée différemment, telle qu'une mémoire partagée de 32 Ko et un cache L1 de 64 Ko, mais elle est toujours effectuée sous forme de division 64 + 32.

Le manque de détails sur le système de mémoire Turning nous a donné envie d'en savoir plus. Nous nous sommes donc tournés vers une équipe de recherche GPU, travaillant pour Citadel Enterprise Americas. Récemment, ils ont publié deux articles analysant les aspects les plus subtils des architectures Volta et Turing; L'image ci-dessus représente la répartition de la hiérarchie de la mémoire dans la puce TU104 (la mémoire complète du cache TU102 avec 6144 Ko de mémoire cache N2).
L’équipe a confirmé que le débit du cache L1 est de 64 bits par cycle et a noté que, lors des tests, l’efficacité du cache L1 de Turing est le meilleur de tous les GPU Nvidia. Ceci est comparable à Navi, bien que la puce d’AMD ait un taux de lecture plus élevé dans le magasin de données local, mais un taux plus faible pour les caches d’instruction / constantes.
Les deux GPU utilisent GDDR6 pour la mémoire locale – il s’agit de la version la plus récente de la DDR SDRAM Graphics – et utilisent des connexions 32 bits aux modules de mémoire, de sorte qu’une Radeon RX 5700 XT dispose de 8 puces de mémoire, offrant une bande passante maximale de 256 Go / s et 8 Go d’espace. Une GeForce RTX 2080 Ti avec une puce TU102 fonctionne avec 11 modules de ce type pour une bande passante de 352 Gb / s et une capacité de stockage de 11 Gb.
Les documents d'AMD peuvent parfois sembler déroutants: dans le premier diagramme que nous avons vu de Navi, il montre quatre contrôleurs de mémoire 64 bits, alors qu'une image ultérieure suggère qu'il y a 16 contrôleurs. Étant donné que Samsung ne propose que des modules de mémoire GDDR6 32 bits, il semblerait que la deuxième image indique simplement le nombre de connexions entre le système Infinity Fabric et les contrôleurs de mémoire. Il n'y a probablement que 4 contrôleurs de mémoire et chacun gère deux modules.
Donc dans l’ensemble, il ne semble pas y avoir de différence énorme entre Navi et Turing en ce qui concerne leurs caches et leur mémoire locale. Navi a un peu plus que Turing plus près du côté exécution, avec des caches plus importants pour les instructions / constantes et L1, mais ils sont tous deux pleins de choses, ils utilisent tous les deux la compression de couleur autant que possible, et ont beaucoup de die dédiés GPU espace pour maximiser l'accès à la mémoire et la bande passante.
Triangles, Textures et Pixels
Il y a quinze ans, les fabricants de GPU accordaient beaucoup d'importance au nombre de triangles que leurs puces pouvaient traiter, au nombre d'éléments de texture pouvant être filtrés à chaque cycle et aux capacités des unités de rendu (ROP). Ces aspects sont toujours importants aujourd'hui, mais comme les technologies de rendu 3D nécessitent des performances de calcul bien meilleures que jamais, l'accent est mis davantage sur l'exécution.
Toutefois, les unités de texture et les POR sont toujours dignes d’être explorées, ne serait-ce que pour noter qu’il n’ya pas de différence immédiatement perceptible entre Navi et Turing dans ces régions. Dans les deux architectures, les unités de texture peuvent adresser et extraire 4 éléments de texture, les filtrer de manière bilinéaire en un seul élément et l'écrire dans le cache en un seul cycle d'horloge (sans tenir compte des cycles d'horloge supplémentaires utilisés pour extraire les données de la mémoire locale).
La disposition des ROP / RB est légèrement différente entre Navi et Turing, mais pas beaucoup: la puce AMD a 4 RB par ACE et chacune d’elles peut générer 4 pixels mélangés par cycle d’horloge; à Turing, chaque GPC a deux RB, chacun donnant 8 pixels par horloge. Le nombre de ROP d'un GPU est en réalité une mesure de ce débit de sortie en pixels. Ainsi, une puce Navi complète donne 64 pixels par horloge et le TU102 total en donne 96 (mais n'oubliez pas qu'il s'agit d'une puce beaucoup plus grande).

Du côté du triangle, il y a moins d'informations immédiates. Ce que nous savons, c’est que Navi génère toujours un maximum de 4 primitives par cycle d’horloge (1 par ACE), mais il n’existe pas encore de solution pour savoir si AMD a résolu le problème lié à leur Shaders primitifs. Il s’agissait là d’une fonctionnalité très prisé de Vega, qui permettait aux programmeurs d’avoir beaucoup plus de contrôle sur les primitives, ce qui pourrait potentiellement multiplier par 4 le débit des primitives. Toutefois, la fonctionnalité a été supprimée des pilotes peu de temps après le produit. lancement, et est resté dormant depuis.
Pendant que nous attendons toujours plus d'informations sur Navi, il ne serait pas sage de spéculer davantage. Turing traite également 1 primitive par horloge par GPC (donc jusqu'à 6 pour le GPU TU102 complet) dans les moteurs raster, mais elle propose également un système appelé Mesh Shaders, qui offre le même type de fonctionnalité que les Primitive Shaders d’AMD; ce n'est pas un ensemble de fonctionnalités de Direct3D, OpenGL ou Vulkan, mais peut être utilisé via des extensions API.
Cela semblerait donner l'avantage à Turing sur Navi, en termes de traitement des triangles et des primitives, mais il n'y a pas assez d'informations dans le domaine public pour le moment.
Tout ne concerne pas les unités d'exécution
Il est intéressant de comparer d'autres aspects de Navi et de Turing. Pour commencer, les deux GPU ont des moteurs d'affichage et de médias hautement développés. Le premier gère la sortie vers le moniteur, le second code et décode les flux vidéo.

Comme on pouvait s'y attendre d'une nouvelle conception de GPU 2019, le moteur d'affichage de Navi offre des résolutions très élevées, à des taux de rafraîchissement élevés, et prend en charge le HDR. Afficher la compression du flux (DSC) est un algorithme de compression rapide avec perte qui permet de transmettre des résolutions de type 4K + à des fréquences de rafraîchissement supérieures à 60 Hz sur une connexion DisplayPort 1.4; heureusement, la dégradation de la qualité de l’image est minime, presque au point que l’on considère DSC pratiquement sans perte.

Turing prend également en charge les connexions DisplayPort avec DSC, bien que la combinaison de résolution élevée et de taux de rafraîchissement prise en charge soit légèrement meilleure que dans Navi: 4K HDR est à 144 Hz – mais le reste est identique.

Le moteur multimédia de Navi est tout aussi moderne que son moteur d'affichage, offrant une prise en charge du codage vidéo avancé (H.264) et du codage vidéo à haute efficacité (H.265), toujours avec des résolutions et des débits élevés.

Le moteur vidéo de Turing est à peu près le même que celui de Navi, mais la prise en charge du codage HDR 8K30 peut faire pencher la balance en faveur de Turing pour certaines personnes.
Il y a d'autres aspects à comparer (l'interface PCI Express 4.0 de Navi ou le lien NV de Turing, par exemple), mais ce ne sont en réalité que de très petites parties de l'architecture globale, quel que soit leur habillement et leur commercialisation. En effet, pour la grande majorité des utilisateurs potentiels, ces fonctionnalités uniques n’auront aucune importance.
Comparer les données comparables
Cet article est une observation de la conception architecturale, des caractéristiques et des fonctionnalités, mais une comparaison directe des performances serait un bon moyen de compléter une telle analyse. Cependant, associer la puce Navi d'une Radeon RX 5700 XT au processeur Turing TU102 d'une GeForce RTX 2080 Ti serait par exemple tout à fait injuste, dans la mesure où cette dernière possède presque deux fois plus d'unités de shader unifiées. Cependant, il existe une version de la puce Turing qui peut être utilisée à des fins de comparaison et c'est celle de la GeForce RTX 2070 Super.
| Radeon RX 5700 XT | GeForce RTX 2070 Super | |
| GPU | Architecture | Navi 10 | ARNR | TU104 | Turing |
| Processus | TSMC 7 nm | TSMC 12 nm |
| Surface de la matrice (mm2) | 251 | 545 |
| Transistors (milliards) | 10.3 | 13.6 |
| Profil de bloc | 2 SE | 4 ACE | 40 CU | 6 GPC | 24 TPC | 48 SM |
| Noyaux de shader unifiés | 2560 SP | 2560 CUDA |
| TMUs | 160 | 160 |
| ROPs | 64 | 64 |
| Horloge de base | 1605 MHz | 1605 MHz |
| Horloge de jeu | 1755 MHz | N / A |
| Boost Clock | 1905 MHz | 1770 MHz |
| Mémoire | GDDR6 8 Go 256 bits | GDDR6 8 Go 256 bits |
| Bande passante mémoire | 448 Go / s | 448 Go / s |
| Puissance de conception thermique (TDP) | 225 W | 215 W |
Il convient de noter que le RTX 2070 Super n’est pas une puce TU104 «complète» (l’un des GPC est désactivé), de sorte que tous les transistors 13.6 ne sont pas actifs, ce qui signifie que les puces sont à peu près identiques en termes de nombre de transistors. À première vue, les deux GPU semblent très similaires, en particulier si l’on prend uniquement en compte le nombre d’unités de shader, les unités de traitement, les ROP et les systèmes de mémoire principaux.
Dans le processeur AMD, une CU peut gérer deux vagues de 32 threads. Ce GPU peut donc fonctionner à 2560 threads; Le TU104, avec ses 48 unités SM capables de gérer quatre chaînes de 32 fils, peut accueillir jusqu'à 6144 fils. Cela semblerait donner à Turing un avantage considérable sur Navi, mais n'oubliez pas que les shaders d'AMD sont très différents de ceux de Nvidia.
Cela aura un impact sur le fonctionnement des différents jeux car le code d'un moteur 3D privilégiera une structure mieux que l'autre, en fonction des types d'instructions envoyées régulièrement au GPU. Cela était évident lorsque nous avons testé les deux cartes graphiques:

Tous les jeux utilisés dans le test ont été programmés pour l'architecture GCN d'AMD, que ce soit directement pour les PC équipés de Radeon ou via les GPU GCN que l'on trouve sur les modèles PlayStation 4 ou Xbox One. Il est possible que certaines des publications les plus récentes aient été préparées pour les modifications RDNA, mais les différences observées dans les résultats des tests de performance sont plus probablement dues aux moteurs de rendu et à la manière dont les instructions et les données sont traitées.
Alors que veut dire tout cela? Une architecture est-elle vraiment meilleure que l'autre? Turing offre certes plus de fonctionnalités que Navi grâce à ses Tensor et RT Cores, mais ce dernier est certainement compétitif en termes de performances de rendu 3D. Les différences observées dans un échantillon de 12 parties ne sont tout simplement pas assez concluantes pour permettre un jugement définitif.
Et c'est une bonne nouvelle pour nous.
Mots finaux
Les plans Navi d'AMD ont été annoncés en 2016 et, même s'ils ne disaient pas grand-chose à l'époque, ils visaient un lancement en 2018. À partir de cette date, la feuille de route a été modifiée en 2019, mais il était clair que Navi serait fabriqué sur un nœud de processus 7 nm et que la conception se concentrerait sur l'amélioration des performances.
That has certainly been the case and as we've seen in this article, AMD made architectural changes to allow it to compete alongside equivalent offerings from Nvidia. The new design benefits more than just PC users, as we know that Sony and Microsoft are going to use a variant of the chip in the forthcoming PlayStation 5 and next Xbox.
If you go back towards the start of this article and look again at the structural design of the Shader Engines, as well as the overall die size and transistor count, there is clearly scope for a 'big Navi' chip to go in a top-end graphics card; AMD have pretty much confirmed that this is part of their current plans, as well as aiming for a refinement of the architecture and fabrication process within the next two years.

But what about Nvidia, what are their plans for Turing and its successor? Surprisingly, very little has been confirmed by the company. Back in 2014, Nvidia updated their GPU roadmap to schedule the Pascal architecture for a 2016 launch (and met that target). In 2017, they announced the Tesla V100, using their Volta architecture, and it was this design that spawned Turing in 2018.
Since then, things have been rather quiet, and we've had to rely on rumors and news snippets, which are all generally saying the same thing: Nvidia's next architecture will be called Ampere, it will be fabricated by Samsung using their 7nm process node, and it's planned for 2020. Other than that, there's nothing else to go on. It's highly unlikely that the new chip will break tradition with the focus on scalar execution units, nor is it likely to drop aspects such as the Tensor Cores, as this would cause significant backwards compatibility issues.
We can make some reasoned guesses about what the next Nvidia GPU will be like, though. The company has invested a notable amount of time and money into their ray tracing technology, and the support for it in games is only going to increase; so we can expect to see an improvement with the RT cores, either in terms of their capability or number per SM. If we assume that the rumor about using a 7 nm process node is true, then Nvidia will probably aim for a power reduction rather than outright clock speed increase, so that they can increase the number of GPCs. It's also possible that 7 nm is skipped, and Nvidia heads straight for 5 nm to gain an edge over AMD.
And it looks like AMD and Nvidia will be facing new competition in the discrete graphics card market from Intel, as we know they're planning to re-enter this sector, after a 20 year hiatus. Whether this new product (currently named Xe) will able to compete at the same level as Navi and Turing remains to be seen. Meanwhile Intel has stayed alive in the GPU market throughout those 2 decades by making integrated graphics for their CPUs. Intel's latest GPU, the Gen 11, is more like AMD's architecture than Nvidia's as it uses vector ALUs that can process FP32 and INT32 data, but we don't know if the new graphics cards will be a direct evolution of this design.
What is certain is that the next few years are going to be very interesting, as long as the three giants of silicon structures continue to battle for our wallets. New GPU designs and architectures are going to push transistor counts, cache sizes, and shader capabilities; Navi and RDNA are the newest of them all, and have shown that every step forward, however small, can make a huge difference.