
Intel développe des GPU discrets pour les joueurs, les professionnels et les serveurs, et leur sortie est prévue pour cette année ou en 2021. Les cartes Intel seront soit les sauveurs tant attendus d'un marché stagnant, soit elles sous-performeront et floperont misérablement (aucune pression, personne Intel PR lisant ceci). Personnellement, je suis heureux de toute façon: nous obtenons de bons GPU, ou nous avons de bonnes choses à nous moquer.
Il s'agit de notre deuxième série d'enquêtes sur Xe, comme cela s'est passablement passé au cours des derniers mois. Pour récapituler rapidement la chronologie des principales annonces d'Intel depuis le moment où elles ont rendu public le développement de Xe:
- 8 novembre 2017: Raja Koduri quitte son emploi à la tête du département GPU d'AMD et rejoint Intel, devenant leur vice-président senior du cœur et de l'informatique visuelle. Son premier acte est d'embaucher une demi-douzaine de vieux copains dans les rangs d'AMD.
- 12 juin 2018: Le PDG de l'époque, Brain Krzanich, révèle aux investisseurs d'Intel qu'ils ont conçu un Arctic Sound architecture GPU discrète pendant des années, et ils prévoient de la publier en 2020.
- 8 janvier 2019: Gregory Bryant, vice-président senior de l'informatique cliente, confirme au CES que la première série de GPU d'Intel arrivera sur le nœud 10 nm.
- 1er mai 2019: Jim Jeffers, ingénieur principal et directeur de l’équipe de rendu et de visualisation, annonce la capacité de lancer de rayons de Xe au FMX19.
- 17 novembre 2019: Raja Koduri révèle que Xe sera disponible en trois versions: calcul haute performance, basse puissance et haute performance. Il dit que le premier GPU dans cette dernière catégorie sera Ponte Vecchio, à venir en 2021 sur le nœud 7 nm.
- 9 janvier 2019: Les premières images du véhicule de développement logiciel Graphics One discret (DG1 SDV) sont publiées, montrant une petite carte RVB aidant les développeurs à optimiser leurs logiciels pour l'architecture Xe.
Etc…
- 17 mars 2020: Antoine Cohade, ingénieur principal des relations avec les développeurs, "effectuera une visite détaillée de l'architecture matérielle" et des "implications en termes de performances" de Xe chez GDC.
Le récit officiel fait tourner une histoire d'Intel à l'œuvre pour créer de mystérieux GPU infusés de nombreuses fonctionnalités souhaitables; meilleurs nœuds, lancer de rayons, nouvelles techniques d'emballage. Mais vous et moi savons tous les deux que ce ne sont pas les gadgets qui font un GPU, mais la puissance et l'argent en jeu. Voilà de quoi parle cet article.
Architecture
Une bonne architecture commence par une brique, tout comme les GPU… sauf pour Intel. Les cœurs AMD et Nvidia effectuent une opération par horloge, mais Intel unités d'exécution (UE) en ont huit. Malgré les inexactitudes techniques, nous allons décrire un UE comme équivalent à huit cœurs à des fins de comparaison.
Outre le besoin d'Intel de construire avec huit briques à la fois, leurs techniques de construction sont simples. Ils peuvent jeter quelques briques ensemble et faire un mur. Quelques murs et vous obtenez une chambre, jetez-en deux ensemble et vous pouvez faire un appartement.
Sautant les étapes intermédiaires, la plus grande unité autonome de Xe (l'appartement) est appelée tranche et chacun contient 512 ou 768 cœurs, pour des tranches hautes performances et basse puissance, respectivement. Un seul appartement est tout ce dont vous avez besoin, donc les cartes basse consommation n'utilisent qu'une seule tranche. Mais si vous ne voulez pas vous y installer, Intel construit des GPU passionnés de style gratte-ciel composés de nombreuses tranches.
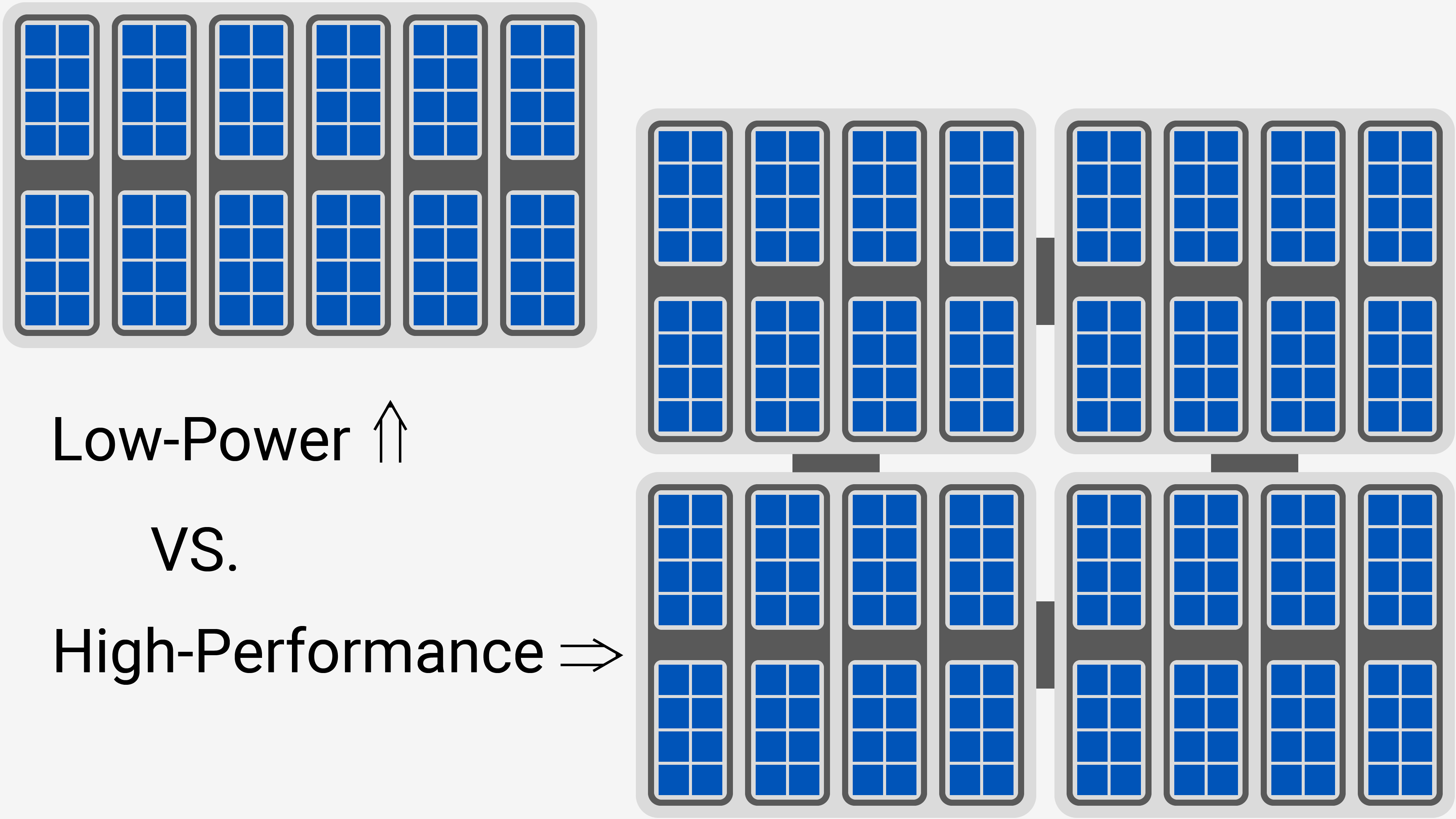
C'est tout ce que vous devez savoir sur l'architecture Xe pour comprendre ce qui se passe, mais si vous pouvez parler de technobabble et de chiffres similaires, ne sautez pas ce bit suivant.
Dans Gen11, les GPU intégrés d'Intel avaient un tranche composé de huit sous-tranches, qui à son tour avait huit unités d'exécution chaque. Ils ont légèrement modifié cela pour Gen12 (première génération de Xe) et incluent unités de calcul (UC) ainsi que les modifications apportées au backend de rendu.
En septembre, le code a été accidentellement téléchargé sur GitHub fuite les configurations de DG1, Ponte Vecchio et une variante DG2. Cette fuite est fiable, car sa prédiction contre-intuitive que Ponte Vecchio aura deux tranches s'est avérée correcte. Sa prédiction selon laquelle la DG1 comptera six sous-tranches par tranche et donc 96 UE a également été plus ou moins confirmée par un Dépôt CEE cela donne le même nombre.
La fuite révèle que dans tous leurs modèles Gen12, Intel a 16 EU par sous-tranche, et à Ponte Vecchio en particulier, quatre sous-tranches par tranche. Koduri a révélé plus tard que Ponte Vecchio avait deux tranches et seize UC.
C'est assez d'informations pour dire que Ponte Vecchio fonctionne probablement comme ceci: huit EU sont combinés en une CU (64 cœurs), qui sont couplés en une sous-tranche (128 cœurs / 16 EU), dont quatre font une tranche (512 cœurs / 64 UE). Avec deux tranches, cela signifie que Ponte Vecchio a 128 EU, 1024 cœurs. Notez que la configuration à deux tranches peut être réservée aux prototypes.
La configuration de base des tranches de Ponte Vecchio devrait également être utilisée sur les modèles hautes performances et basse consommation.
DG2: haute performance
La microarchitecture hautes performances, baptisée Discrete Graphics Two (DG2), enveloppe les marchés GPU milieu de gamme et passionnés. Ce sont ces cartes qui auront le ray tracing et le RGB bling, mais ce qui est le plus excitant, c'est le potentiel d'Intel pour contester la mainmise de Nvidia sur la gamme premium de 600 $ +.
"Xe HP … serait facilement le plus grand silicium conçu en Inde et parmi les plus grands du monde." – Raja Koduri
En juillet dernier, Intel a accidentellement publié un pilote (merci!) Qui contenait trois noms de code DG2, iDG2HP128, iDG2HP256, et iDG2HP512. En faisant l'hypothèse raisonnable que les trois chiffres à la fin indiquent le nombre d'EU de la carte, ils auront respectivement 1024, 2048 et 4096 cœurs. C’est deux, quatre et huit tranches.
Peu de temps après, cependant, nous avons vu preuve d'un GPU à trois tranches avec 1536 cœurs en cours de développement. Étant donné qu'il serait illogique pour Intel de développer une quatrième carte conçue de manière similaire aux modèles existants, il est sûr de supposer qu'il s'agit d'un iDG2HP256 avec une tranche désactivée. Cela soutient les soupçons répandus selon lesquels Intel prend les trois modèles fondamentaux et désactive une ou plusieurs tranches pour ajouter des quatrième, cinquième, sixième ou même septième modèles à leur gamme.
| # de tranches | 1 | 2 | 3 | 4 | 5 | 6 | sept | 8 |
| Nombre de cœurs | 768 * | 1024 | 1536 | 2048 | 2560 | 3072 | 3584 | 4096 |
| Nom de code | iDG1LPDEV | iDG2HP128 | iDG2HP256 | iDG2HP512 |
DG2 sera également plus que des GPU de jeu. Ils ne seront pas en mesure de gérer des charges de travail scientifiques comme Ponte Vecchio, mais s'ils ont une bonne valeur à la sortie, ils pourraient certainement être commercialisés avec des pilotes professionnels comme matériel de montage vidéo ou de modélisation 3D, comme les cartes Quadro de Nvidia.
DG1: Basse puissance
Le segment de faible puissance est défini comme cela, de 5W à 50W. 5W à 20W pour les GPU intégrés et 20W à 50W pour les GPU discrets.
Intel nous a déjà présenté le premier membre de la famille LP. Le DG1 SDV a été mis en évidence au CES 2020, exécutant Destiny 2 et Warframe avec RVB et tout. Mais c'est seulement une carte de jeu. Le DG1 SDV est une édition réservée aux développeurs, conçue pour faciliter la transition des logiciels et des pilotes vers la plate-forme Xe.
Cependant, cela ne signifie pas que vous ne pourrez pas finalement acheter quelque chose d'assez similaire – Intel l'a déjà montré fonctionnant sur un ordinateur portable.

Les formes intégrées du GPU LP auraient entre 64 et 768 cœurs, tandis que les GPU LP discrets utiliseraient exclusivement les 768 cœurs complets. C'est un nombre comparable de cœurs au meilleur matériel intégré d'AMD et aux GPU discrets les plus bas de Nvidia. Mais là où Xe LP pourrait les éclipser, c'est dans les vitesses d'horloge.
Une fuite Geekbench run d'un processeur mobile Rocket Lake a montré un GPU LP 768 core intégré fonctionnant à 1,5 GHz, ce qui lui donne 2,3 TFLOP. C'est la même quantité de performances qu'une GTX 1650. Même en supposant le pire, que le 1,5 GHz utilise le TDP complet de 20 W et Intel ne pourra pas pousser des vitesses encore 1 MHz plus haut avant sa sortie, c'est impressionnant.
Imaginez à quel point ce processeur doit être efficace. La GTX 1650 a un peu moins de TFLOP et un TDP de 75 W: presque quatre fois plus. Un GPU LP poussé à 50W augmentera les vitesses d'horloge plus haut et pourrait entrer dans la même fourchette de performances qu'un GTX 1660.
Mais les bonnes choses ne s'arrêtent pas là. Les mises à jour du noyau Linux montrent qu'Intel envisage un moyen d'exécuter des graphiques intégrés et discrets simultanément et potentiellement conjointement. Si cela se prolonge, la pleine puissance d'un iGPU pourrait être associée à la puissance du GPU discret pour créer un GPU combo à 1536 cœurs qui est peu encombrant et rentable. C'est un excellent moyen d'extraire plus de performances du même silicium.
Ponte Vecchio: calcul de données
Quand j'ai dit dans l'introduction que seule la puissance brute d'un GPU était importante, j'ai menti intro clickbait confirmé. Ce n'est le cas pour aucun GPU de centre de données, et Ponte Vecchio en particulier. Ponte Vecchio est tout au sujet des tours et des techniques qui maximisent l'efficacité.
Fait amusant:
Koduri a nommé Ponte Vecchio d'après le pont de Florence parce qu'il aime le gelato là-bas.
Ponte Vecchio a été créé spécifiquement avec le supercalculateur Aurora à l'esprit, ce qui devrait vous donner une indication du type de charges de travail pour lesquelles il sera optimisé.
S'il ne vous a pas donné d'indication, je vais vous l'expliquer: double précision. C'est essentiellement la première chose sur la liste pour chaque GPU de centre de données, et Koduri a passé beaucoup de temps à en discuter pendant la révélation. Malheureusement, cependant, le seul chiffre qu'il y mettrait est la performance théorique du FP64 par UE du Ponte Vecchio, qui est environ 40 fois supérieure à celle du Gen11.
En faisant un peu de maths sur une serviette, cela représente environ 20 TFLOP à FP64 par 1024 cartes de base. Ne considérez pas cela comme un évangile, car il n'y a pas suffisamment de chiffres significatifs dans le calcul pour donner des résultats significatifs.
Après les charges de travail de haute précision, vient naturellement le travail de très faible précision. Ponte Vecchio prend en charge INT8, BF16 et les FP8 et FP16 habituels pour le traitement des réseaux de neurones AI. Chaque UE est équipée d'un moteur matriciel (comme un noyau Nvidia Tensor) 32 fois plus rapide qu'une UE standard pour le traitement matriciel.
Cependant, rien de tout cela n'est particulièrement nouveau. La véritable force de Ponte Vecchio réside dans son sous-système de mémoire, qui permet au GPU de résoudre les problèmes de nouvelles façons.
Pour ce faire, Ponte Vecchio s'appuie sur les nouvelles technologies d'interconnexion pivots d'Intel, Foveros et EMIB (pont d'interconnexion multi-puce intégré). Foveros utilise des vias traversants en silicium pour empiler plusieurs puces au-dessus d'une puce d'interposition active, ce qui leur donne des vitesses similaires à celles de la puce, mais une connectivité hors puce. En comparaison, EMIB est une connexion «stupide» entre deux puces qui utilise une puce inactive mais offre une bande passante élevée à moindre coût.
EMIB et Foveros
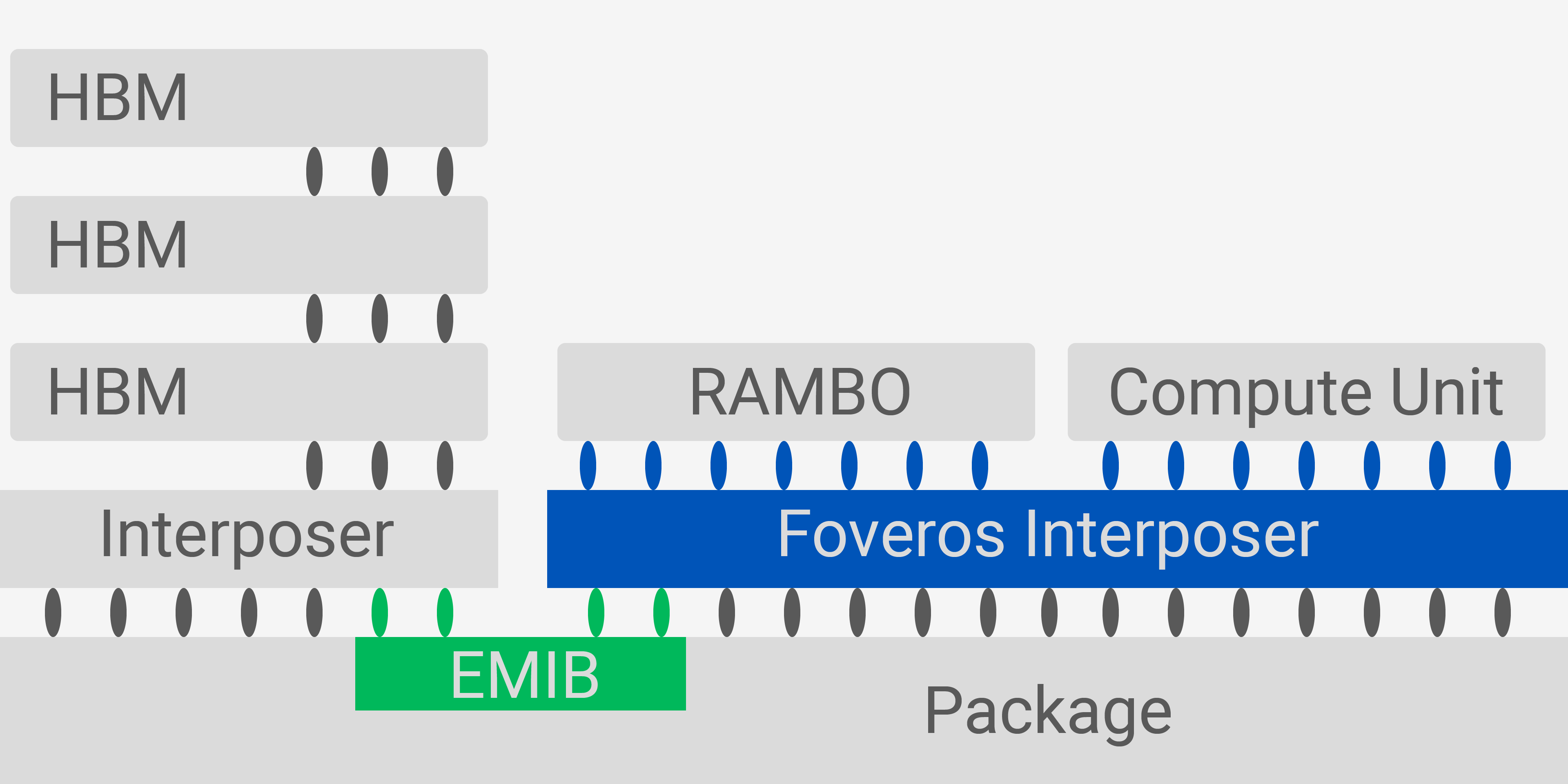
EMIB est utilisé pour connecter le matériel de calcul du GPU directement au HBM, créant une bande passante mémoire spectaculaire pour Ponte Vecchio. Foveros est utilisé pour connecter les deux UC sur une sous-tranche à un chiplet de cache RAMBO, le nouveau super cache d'Intel. Grâce à Foveros, RAMBO n'a aucune limitation imposée à sa capacité ou à son encombrement, et il peut contourner les UC lors de l'envoi / réception de données du HBM ou d'autres sous-tranches.
Avoir un cache gigantesque – et par gigantesque je veux dire gigantesque, les diagrammes d'Intel montrent un chiplet RAMBO comme étant de la même taille qu'un CU – est évidemment très cher, mais il déverrouille quelques options astucieuses. Dans le traitement des réseaux de neurones, par exemple, RAMBO peut stocker des matrices d'un ordre de grandeur plus grand que les autres caches GPU. D'autres GPU perdent leurs performances à mesure que les matrices s'agrandissent et que le niveau de précision augmente, mais Ponte Vecchio est capable de maintenir des performances de pointe.
Ponte Vecchio
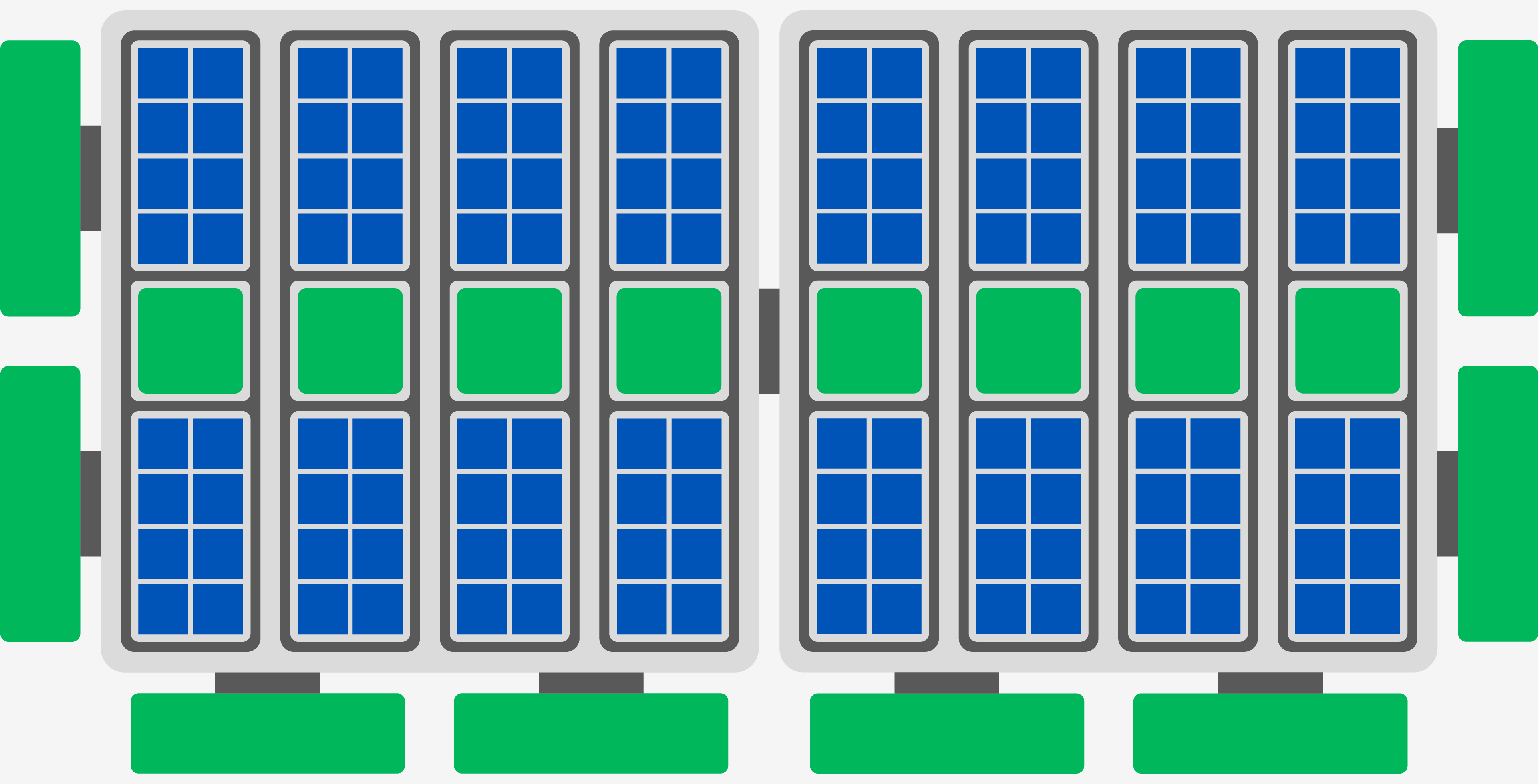
Le cache RAMBO alimente également le Xe Memory Fabric, une toile d'araignée de connexions et de technologies qui regroupe les ressources de chaque GPU et CPU dans un nœud de serveur. Le cache RAMBO de chaque GPU est combiné en une banque disponible pour tout, la connexion la plus lente étant celle des CPU à 63 Go / s sur PCIe 5.0.
Lors de leur récente réunion annuelle des investisseurs sur les bénéfices, Intel a confirmé que Ponte Vecchio commencerait à être commercialisé au cours du quatrième trimestre de 2021. Il n'est pas clair si cela fait référence à une version complète ou à un lancement anticipé exclusif du supercalculateur Aurora.
Logiciel
Le matériel est bon et tout, mais complètement inutile sans un support logiciel adéquat. Et le seuil est assez élevé: même si 1% des jeux ne sont pas correctement pris en charge, des millions de joueurs sont aliénés. La bonne nouvelle, c'est qu'Intel semble faire de son mieux.
Intel redessine son plus bas niveau de logiciel, l'architecture du jeu d'instructions (ISA), pour les applications modernes à hautes performances. «Gen12 devrait inclure l'une des retouches les plus approfondies d'Intel EU ISA depuis l'i965 d'origine. L'encodage de presque tous les champs d'instructions, opcode matériel et type de registre doit être mis à jour. »
Au niveau des pilotes, Intel a un long chemin à parcourir mais progresse. Leurs pilotes de GPU intégrés ne sont pas mis à jour aussi souvent que leurs concurrents, le délai moyen entre les dix dernières mises à jour étant de 26 jours pour Intel contre 14 jours pour Nvidia et 12 jours pour AMD. Mais leur stabilité et leur support se sont beaucoup améliorés en 2019, et 275 nouveaux titres ont été optimisés pour l'architecture d'Intel.
D'un autre côté, le logiciel Intel destiné aux consommateurs est superbe. Le centre de commande graphique récemment publié offre un contrôle beaucoup plus important que GeForce Experience de Nvidia, par exemple, et est plus facile à utiliser. Comme GeForce Experience, il peut optimiser les jeux pour des configurations matérielles particulières, mais il explique également ce que chaque paramètre fait et quel impact sur les performances il aura. Le contrôle du conducteur est agréablement simple.
Le Command Center est également unique en ce qu'il propose des commandes d'affichage avancées. Il offre une configuration multi-affichage indolore et un taux de rafraîchissement et une synchronisation de rotation, ainsi que des options complètes pour ajuster le style des couleurs. Je l'utilise personnellement pour contrôler mon système, malgré l'exécution du matériel Nvidia.
En prime, Intel prend également en charge le taux de rafraîchissement variable, les produits Xe prendront donc en charge les moniteurs FreeSync et G-Sync.
Libération
Alors qu'Intel est un peu timide à propos de ce qu'ils annonceront à GDC en mars, il y a de fortes chances que nous examinions une révélation complète. Si tel est le cas, nous pouvons nous attendre à une sortie dans les prochains mois. Le candidat le plus probable est juin.
En octobre dernier, Koduri a tweeté un discours pas si subtil allusion sous la forme d'une image de sa nouvelle plaque d'immatriculation. Il se lit "Think Xe" et a une date de juin 2020. Il refuse de commenter si la date a une signification ou non, ce qui suggère que c'est probablement le cas.

Et si ce n'est pas une voiture, mais un rendu Intel?  – Richart
– Richart
Un avantage de la fuite d'une date de cette manière est qu'elle indique à la communauté à quoi s'attendre, sans susciter tellement d'excitation que les fans se mettront en colère si les GPU arrivent à la place en juillet. Considérez-le donc comme une cible floue; Intel vise probablement une version de juin (à temps pour Computex), mais cela pourrait prendre un peu plus de temps selon la situation.
Intel fait allusion à des trucs assez cool et nous gardons espoir d'avoir un troisième acteur majeur dans le domaine graphique. Mais tant qu'il n'est pas temps, nous ne pouvons être que prudemment optimistes.