
La grande majorité des effets visuels que vous voyez dans les jeux aujourd'hui dépendent de l'utilisation intelligente de l'éclairage et des ombres – sans eux, les jeux seraient ternes et sans vie. Dans cette quatrième partie de notre regard approfondi sur le rendu de jeu 3D, nous nous concentrerons sur ce qui se passe dans un monde 3D à côté du traitement des sommets et de l'application de textures. Cela implique une fois de plus beaucoup de mathématiques et une bonne compréhension des principes fondamentaux de l'optique.
Nous allons plonger pour voir comment tout cela fonctionne. Si c'est la première fois que vous consultez notre série de rendus 3D, nous vous recommandons de commencer au début avec notre rendu de jeu 3D 101, qui est un guide de base sur la façon dont une image de qualité de jeu est créée. De là, nous avons travaillé tous les aspects du rendu dans les articles ci-dessous …
résumer
Jusqu'à présent dans la série, nous avons couvert les aspects clés de la façon dont les formes d'une scène sont déplacées et manipulées, transformées d'un espace tridimensionnel en une grille plate de pixels, et comment les textures sont appliquées à ces formes. Pendant de nombreuses années, c'était la majeure partie du processus de rendu, et nous pouvons le voir en remontant à 1993 et en lançant Doom d'id Software.
L'utilisation de la lumière et de l'ombre dans ce titre est très primitive par rapport aux normes modernes: aucune source de lumière n'est prise en compte, car chaque surface reçoit une vue d'ensemble, ou ambiant, valeur de couleur en utilisant les sommets. Toute sensation d'ombre vient simplement d'une utilisation intelligente des textures et du choix de la couleur ambiante par le concepteur.
Ce n'était pas parce que les programmeurs n'étaient pas à la hauteur: le matériel PC de cette époque était composé de CPU à 66 MHz (soit 0,066 GHz!), De disques durs de 40 Mo et de cartes graphiques de 512 ko avec des capacités 3D minimales. Avance rapide de 23 ans, et c'est une histoire très différente dans le redémarrage acclamé.

Il existe une multitude de technologies utilisées pour rendre ce cadre, proposant des phrases intéressantes telles que l'occlusion ambiante de l'écran, la cartographie de la profondeur avant le passage, les filtres de flou Bokeh, les opérateurs de cartographie des tons, etc. L'éclairage et l'ombrage de chaque surface sont dynamiques: en constante évolution avec les conditions environnementales et les actions du joueur.
Étant donné que tout ce qui concerne le rendu 3D implique des mathématiques (et beaucoup!), Nous ferions mieux de rester coincés dans ce qui se passe dans les coulisses de tout jeu moderne.
Les mathématiques de l'éclairage
Pour faire tout cela correctement, vous devez pouvoir modéliser avec précision le comportement de la lumière lorsqu'elle interagit avec différentes surfaces. Vous pourriez être surpris de savoir que ses origines remontent au 18ème siècle, et un homme appelé Johann Heinrich Lambert.
En 1760, le scientifique suisse a publié un livre intitulé Photometria – dans ce document, il a établi un ensemble de règles fondamentales sur le comportement de la lumière; le plus notable étant que les surfaces émettent de la lumière (par réflexion ou comme source de lumière elle-même) de telle manière que l'intensité de la lumière émise change avec le cosinus de l'angle, mesuré entre la normale de la surface et l'observateur de la lumière.
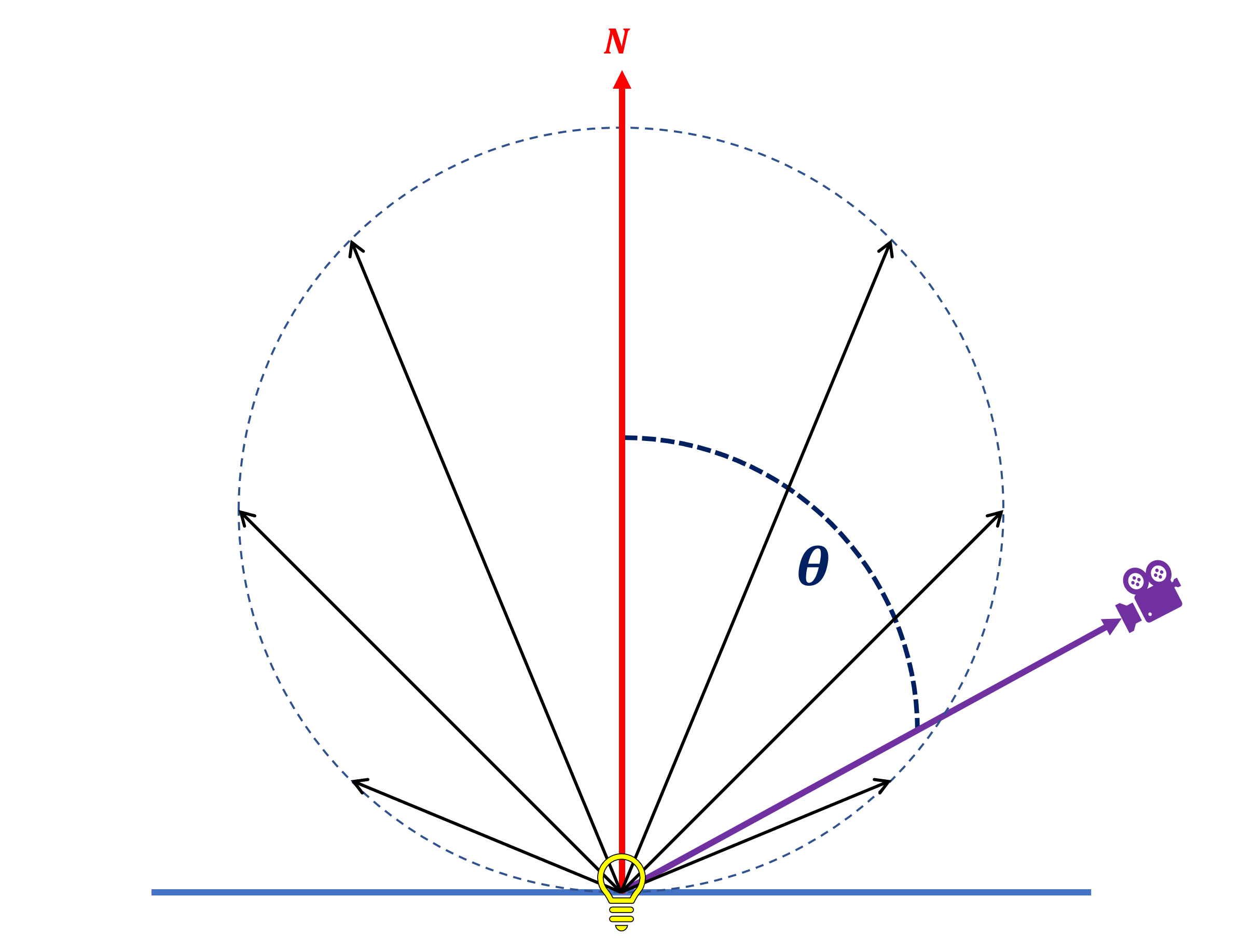
Cette règle simple constitue la base de ce qu'on appelle diffuser éclairage. Il s'agit d'un modèle mathématique utilisé pour calculer la couleur d'une surface en fonction de ses propriétés physiques (telles que sa couleur et la façon dont elle réfléchit la lumière) et la position de la source de lumière.
Pour le rendu 3D, cela nécessite beaucoup d'informations, et cela peut être mieux représenté avec un autre diagramme:
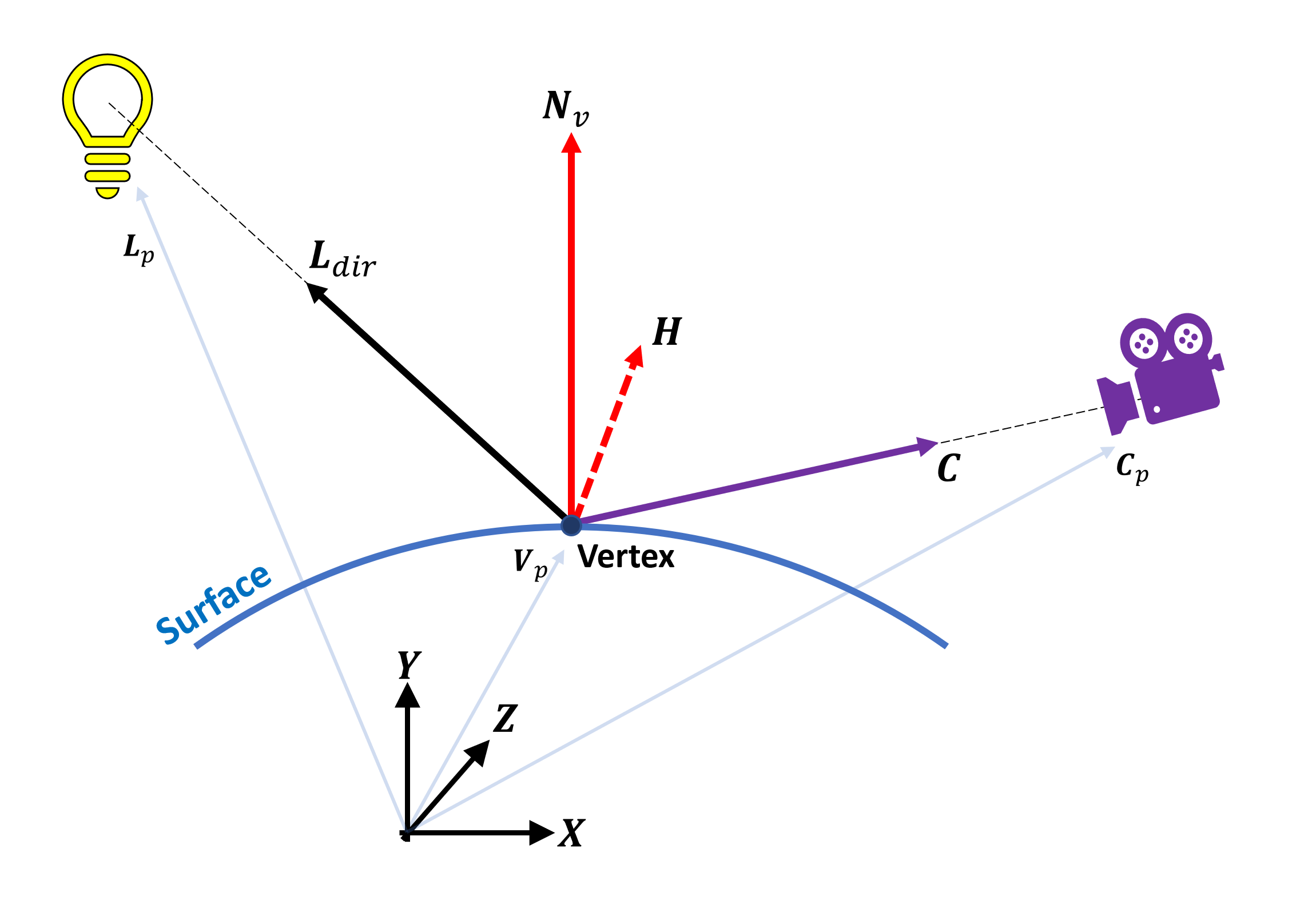
Vous pouvez voir beaucoup de flèches sur l'image – ce sont vecteurs et pour chaque sommet pour calculer la couleur, il y aura:
- 3 pour les positions du sommet, de la source lumineuse et de la caméra visionnant la scène
- 2 pour les directions de la source lumineuse et de la caméra, du point de vue du sommet
- 1 vecteur normal
- 1 demi-vecteur (il est toujours à mi-chemin entre les vecteurs de direction de la lumière et de la caméra)
Ceux-ci sont tous calculés pendant l'étape de traitement des sommets de la séquence de rendu, et l'équation (appelée le modèle lambertien) qui les relie tous ensemble est:
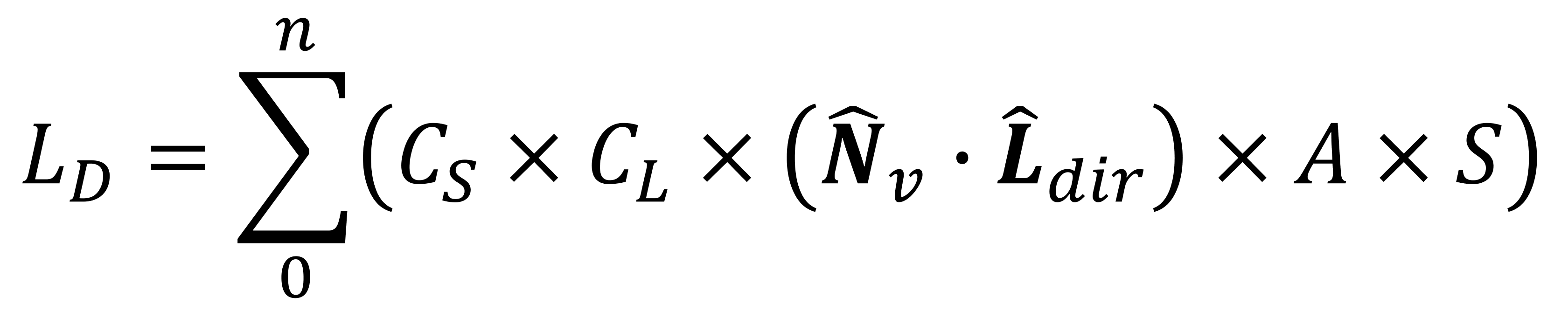
Ainsi, la couleur du sommet, grâce à un éclairage diffus, est calculée en multipliant la couleur de la surface, la couleur de la lumière et le produit scalaire des vecteurs de direction normale et légère du sommet, avec des facteurs d'atténuation et de projecteur. Cela se fait pour chaque source lumineuse de la scène, d'où la partie «sommation» au début de l'équation.
Les vecteurs de cette équation (et tout le reste que nous verrons) sont normalisés (comme indiqué par l'accent sur chaque vecteur). Un vecteur normalisé conserve sa direction d'origine, mais sa longueur est réduite à l'unité (c'est-à-dire qu'elle est exactement de 1 unité).
Les valeurs pour les couleurs de surface et de lumière sont des nombres RGBA standard (rouge, vert, bleu, transparence alpha) – ils peuvent être entiers (par exemple INT8 pour chaque canal de couleur) mais ils sont presque toujours un flottant (par exemple FP32). Le facteur d'atténuation détermine comment le niveau de lumière provenant de la source diminue avec la distance, et il est calculé avec une autre équation:
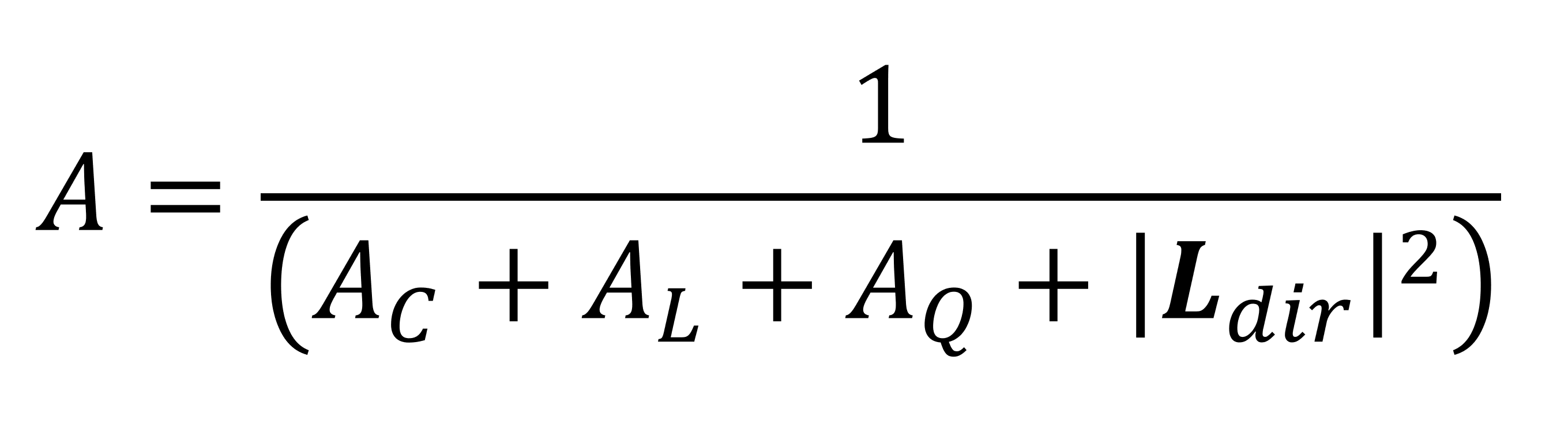
Les termes AC, UNELet AQ sont différents coefficients (constants, linéaires, quadratiques) pour décrire la façon dont le niveau de lumière est affecté par la distance – tous doivent être définis par les programmeurs lors de la création du moteur de rendu. Chaque API graphique a sa propre façon de procéder, mais les coefficients sont entrés lorsque le type de source lumineuse est codé.
Avant d'examiner le dernier facteur, celui des projecteurs, il convient de noter qu'en rendu 3D, il existe essentiellement 3 types de lumières: ponctuelles, directionnelles et ponctuelles.
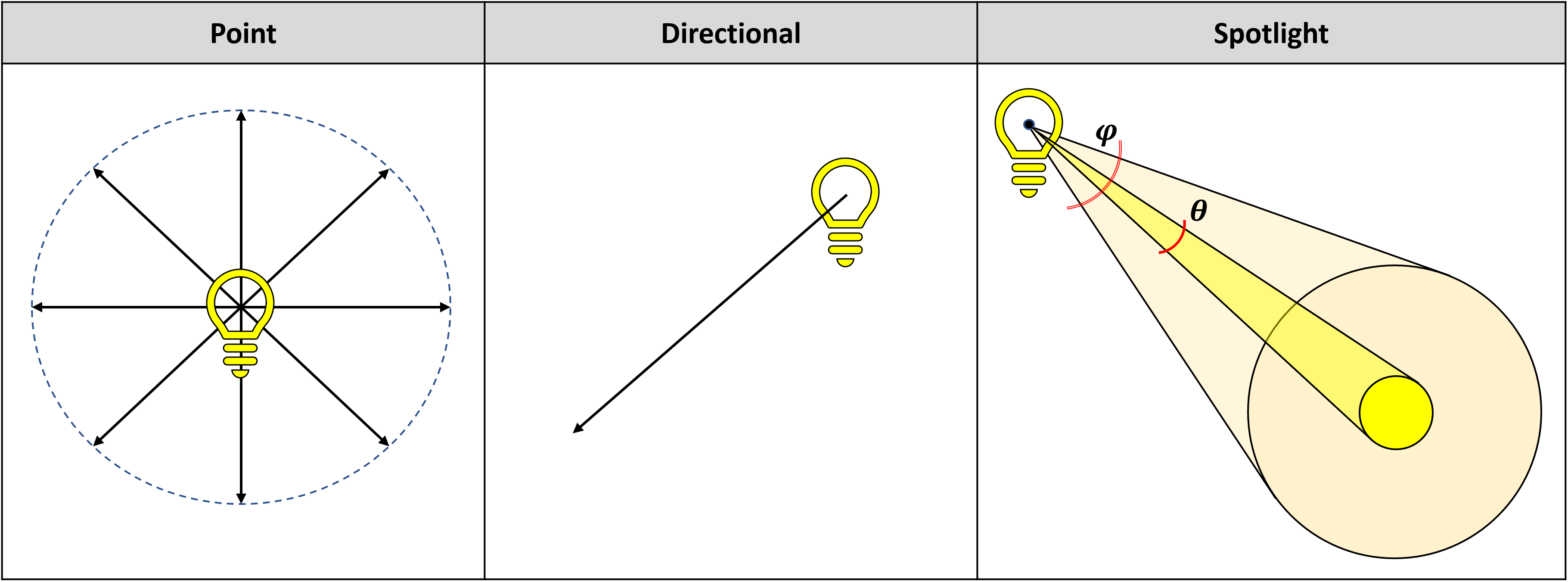
Les lumières ponctuelles émettent également dans toutes les directions, tandis qu'une lumière directionnelle ne projette la lumière que dans une seule direction (mathématiquement, c'est en fait une lumière ponctuelle à une distance infinie). Les projecteurs sont des sources directionnelles complexes, car ils émettent de la lumière en forme de cône. La façon dont la lumière varie à travers le corps du cône est déterminée par la taille des sections intérieure et extérieure du cône.
Et oui, il y a une autre équation pour le facteur spot:
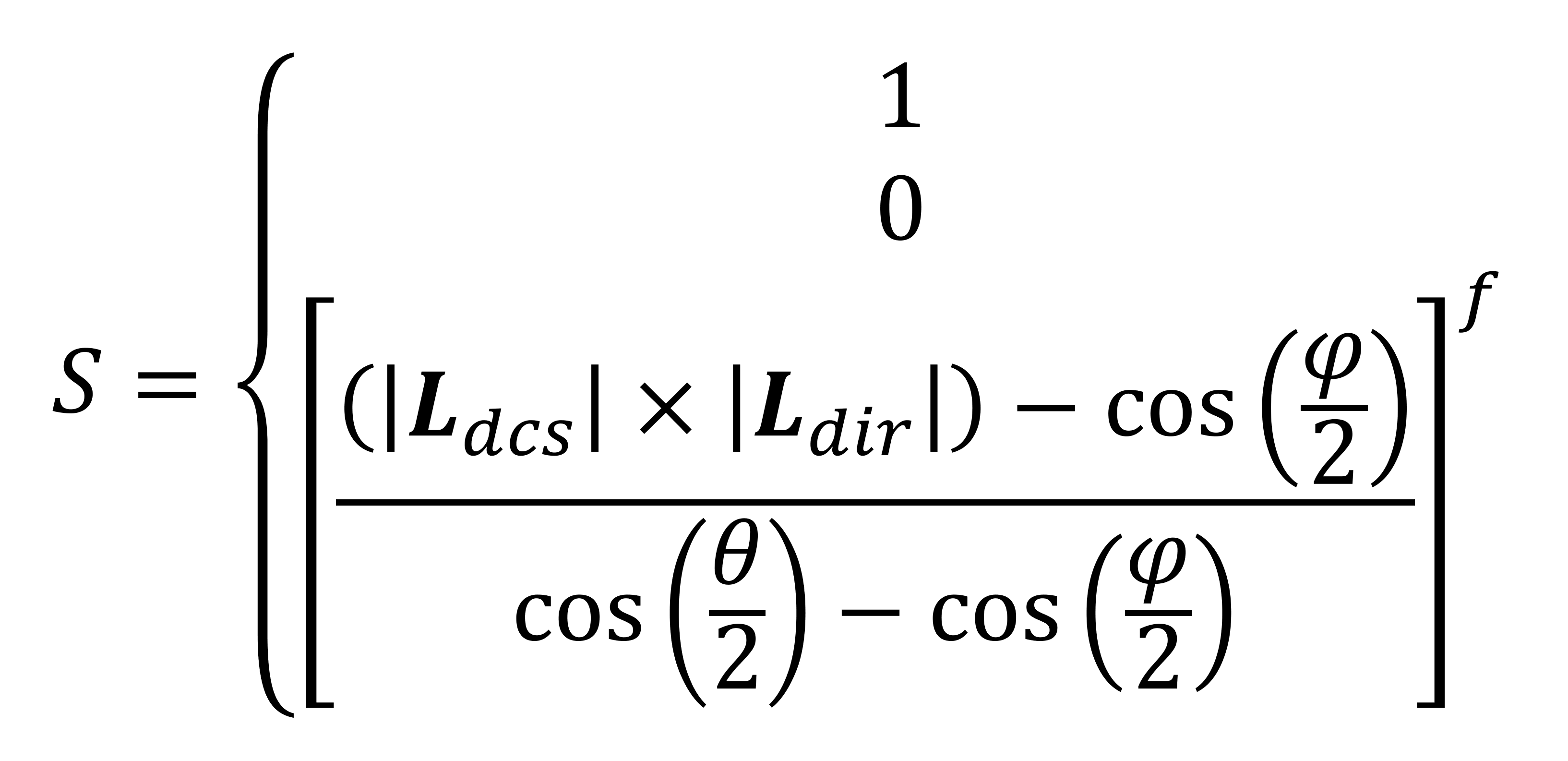
La valeur du facteur de projecteur est soit 1 (c'est-à-dire la lumière n'est pas un projecteur), 0 (si le sommet se situe en dehors de la direction du cône) ou une valeur calculée entre les deux. Les angles φ (phi) et θ (thêta) indique les tailles des sections intérieure / extérieure du cône du projecteur.
Les deux vecteurs, Ldcs et moidir, (l'inverse de la direction de la caméra et de la direction du projecteur, respectivement) sont utilisés pour déterminer si oui ou non le cône touchera réellement le sommet.
Rappelez-vous maintenant que c'est tout pour calculer la valeur d'éclairage diffus et que cela doit être fait pour chaque source de lumière dans la scène ou au moins, chaque lumière que le programmeur veut inclure. Un grand nombre de ces équations sont gérées par l'API graphique, mais elles peuvent être effectuées «manuellement» par des codeurs souhaitant un contrôle plus fin des éléments visuels.
Cependant, dans le monde réel, il existe essentiellement un infini nombre de sources lumineuses. En effet, chaque surface réfléchit la lumière et chacune contribuera ainsi à l'éclairage général d'une scène. Même la nuit, il y a toujours un éclairage de fond – qu'il s'agisse d'étoiles et de planètes lointaines, ou de la lumière diffusée à travers l'atmosphère.
Pour modéliser cela, une autre valeur lumineuse est calculée: celle appelée ambiant éclairage.
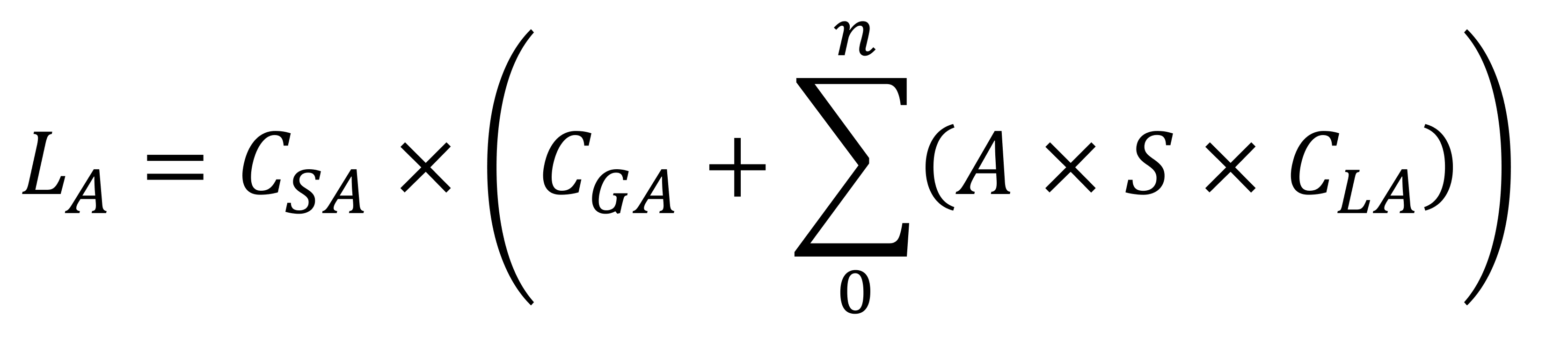
Cette équation est plus simple que celle diffuse, car aucune direction n'est impliquée. Il s'agit plutôt d'une simple multiplication de divers facteurs:
- CSA – la couleur ambiante de la surface
- CGéorgie – la couleur ambiante de la scène 3D globale
- CLA – la couleur ambiante de toutes les sources lumineuses de la scène
Notez à nouveau l'utilisation des facteurs d'atténuation et de projecteur, ainsi que la somme de toutes les lumières utilisées.
Nous avons donc un éclairage de fond et la façon dont la source de lumière se reflète de manière diffuse sur les différentes surfaces du monde 3D. Mais l'approche de Lambert ne fonctionne vraiment que pour les matériaux qui réfléchissent la lumière sur leur surface dans toutes les directions; les objets en verre ou en métal produiront un type de réflexion différent, ce que l'on appelle spéculaire et naturellement, il y a une équation pour ça aussi!
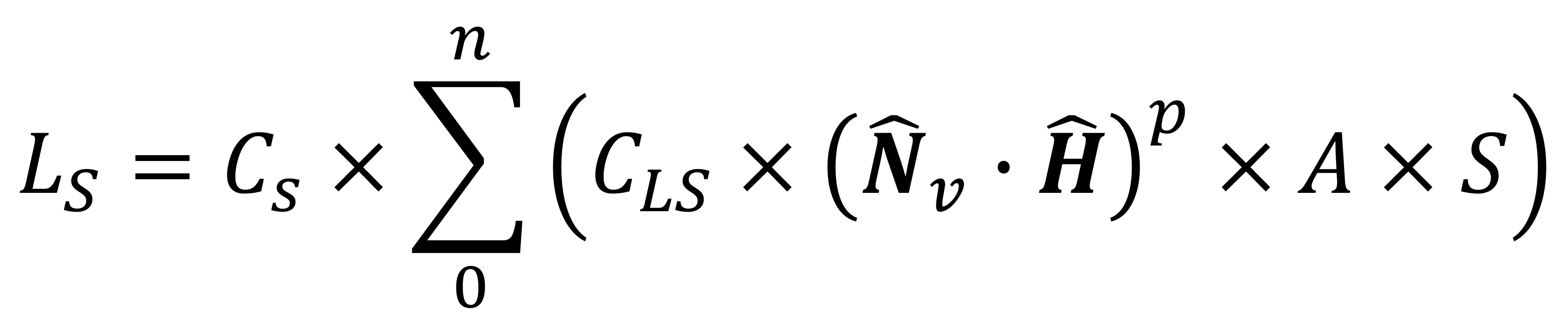
Les différents aspects de cette formule devraient maintenant être un peu familiers: nous avons deux valeurs de couleur spéculaire (une pour la surface, CS, et un pour la lumière, CLS), ainsi que les facteurs d'atténuation et de mise en lumière habituels.
La réflexion spéculaire étant hautement focalisée et directionnelle, deux vecteurs sont utilisés pour déterminer l'intensité de la lumière spéculaire: la normale du sommet et le demi-vecteur. Le coefficient p est appelé le pouvoir de réflexion spéculaire, et c'est un nombre qui ajuste la luminosité de la réflexion, en fonction des propriétés matérielles de la surface. Au fur et à mesure que la taille de p augmente, l'effet spéculaire devient plus brillant mais plus focalisé et plus petit.
Le dernier aspect d'éclairage à prendre en compte est le plus simple du lot, car ce n'est qu'un chiffre. C'est appelé émissif l'éclairage et est appliqué pour les objets qui sont une source directe de lumière – par exemple une flamme, une lampe de poche ou le soleil.
Cela signifie que nous avons maintenant 1 nombre et 3 ensembles d'équations pour calculer la couleur d'un sommet dans une surface, en tenant compte de l'éclairage de fond (ambiant) et de l'interaction entre diverses sources de lumière et les propriétés matérielles de la surface (diffuse et spéculaire). Les programmeurs peuvent choisir d'en utiliser un seul ou de les combiner en les ajoutant simplement ensemble.
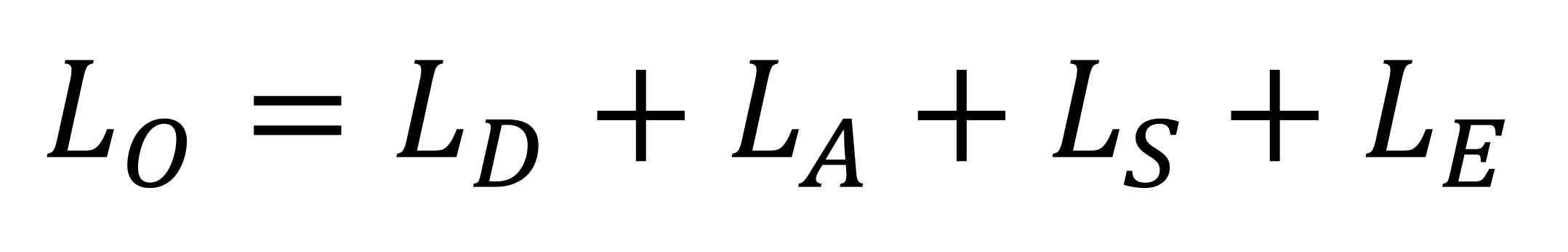
Visuellement, la combinaison prend une apparence comme celle-ci:

Les équations que nous avons examinées sont utilisées par les API graphiques, telles que Direct3D et OpenGL, lors de l'utilisation de leurs fonctions standard, mais il existe des algorithmes alternatifs pour chaque type d'éclairage. Par exemple, la diffusion peut être effectuée via le modèle Oren-Nayar qui convient à des surfaces très rugueuses entre celles du Lambertien.
L'équation spéculaire plus haut dans cet article peut être remplacée par des modèles qui tiennent compte du fait que les surfaces très lisses, telles que le verre et le métal, sont encore rugueuses mais à un niveau microscopique. Qualifiés d'algorithmes microfacets, ils offrent des images plus réalistes, au prix d'une complexité mathématique.
Quel que soit le modèle d'éclairage utilisé, ils sont tous considérablement améliorés en augmentant la fréquence à laquelle l'équation est appliquée dans la scène 3D.
Par sommet ou par pixel
Lorsque nous avons examiné le traitement et la pixellisation des sommets, nous avons vu que les résultats de tous les calculs d'éclairage fantaisistes, effectués sur chaque sommet, doivent être interpolés sur la surface entre les sommets. En effet, toutes les propriétés associées au matériau de la surface sont contenues dans les sommets; lorsque le monde 3D sera écrasé dans une grille 2D de pixels, il n'y aura qu'un seul pixel directement à l'endroit où se trouve le sommet.
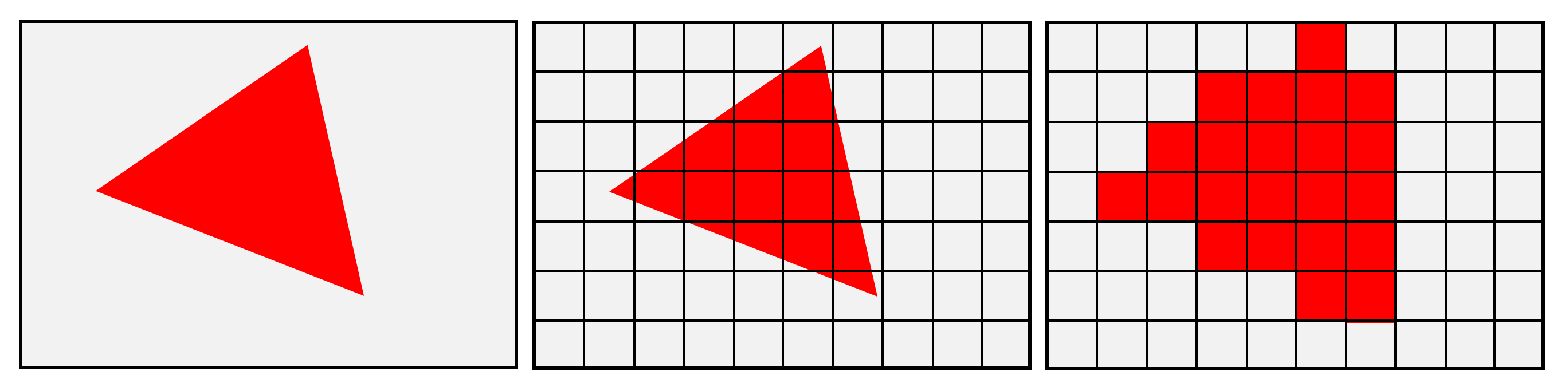
Les autres pixels devront recevoir les informations de couleur du sommet de telle manière que les couleurs se mélangent correctement sur la surface. En 1971, Henri Gouraud, un diplômé de l'Université de l'Utah à l'époque, a proposé une méthode pour ce faire, et il porte maintenant le nom de Ombrage Gouraud.
Sa méthode était rapide sur le plan informatique et de facto méthode de le faire pendant des années, mais ce n'est pas sans problèmes. Il a du mal à interpoler correctement l'éclairage spéculaire et si la forme est construite à partir d'un petit nombre de primitives, le mélange entre les primitives ne semble pas correct.
Une solution à ce problème a été proposée par Bui Tuong Phong, également de l'Université de l'Utah, en 1973 – dans son document de recherche, Phong a montré une méthode d'interpolation des sommets normaux sur des surfaces tramées. Cela signifiait que les modèles de réflexion diffuse et spéculaire fonctionneraient correctement sur chaque pixel, et nous pouvons le voir clairement en utilisant le manuel en ligne de David Eck sur l'infographie et WebGL.
Les grosses sphères sont colorées par le même modèle d'éclairage, mais celui de gauche effectue les calculs par sommet, puis utilise l'ombrage Gouraud pour l'interpoler sur la surface. La sphère de droite fait cela par pixel, et la différence est évidente.
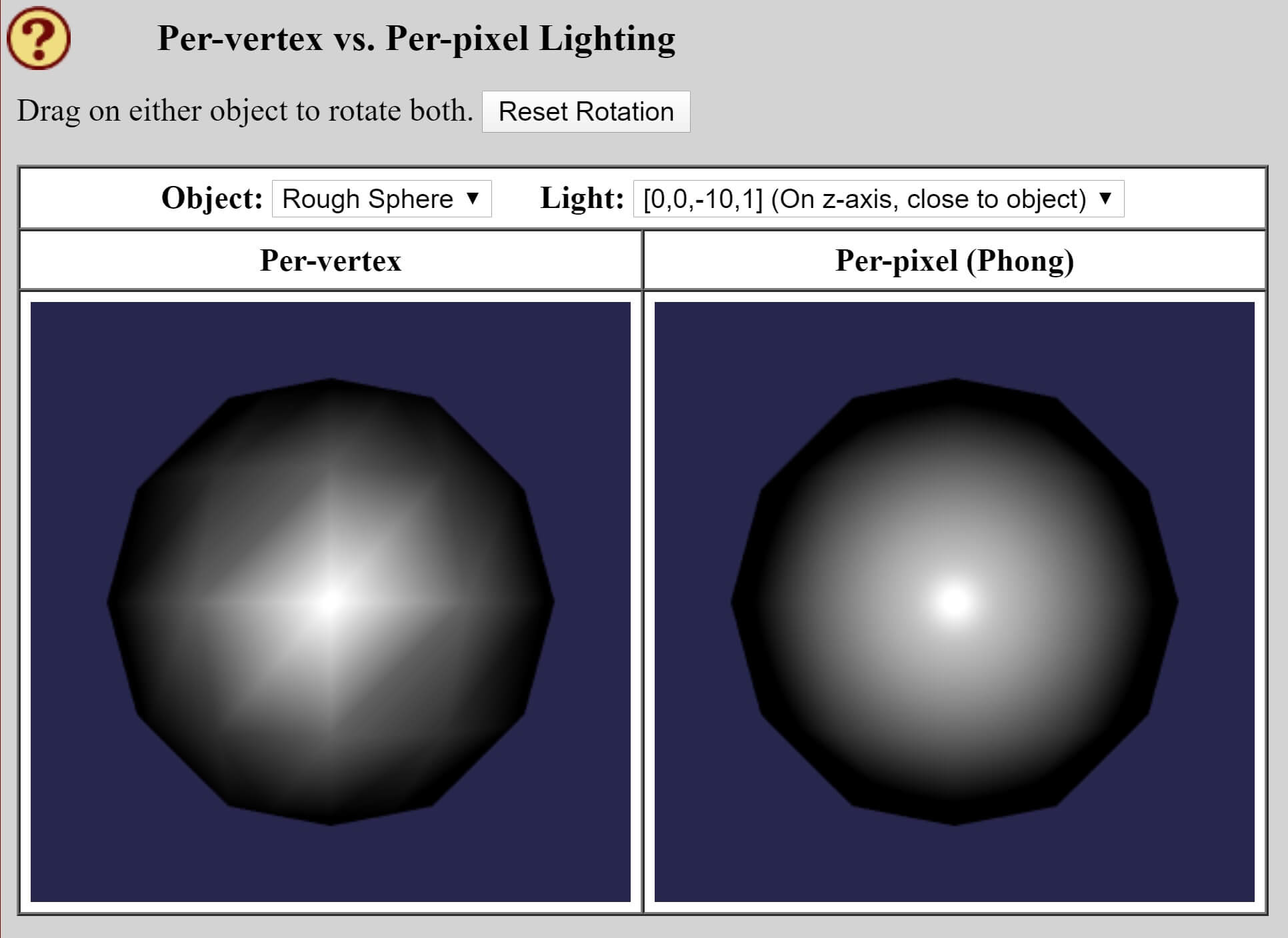
L'image fixe ne rend pas assez justice pour faire l'amélioration Ombrage Phong apporte, mais vous pouvez essayer la démo vous-même en utilisant la démo en ligne d'Eck, et la voir animée.
Phong ne s'est pas arrêté là, cependant, et quelques années plus tard, il a publié un autre document de recherche dans lequel il a montré comment les calculs séparés pour l'éclairage ambiant, diffus et spéculaire pouvaient tous être effectués dans une seule équation:
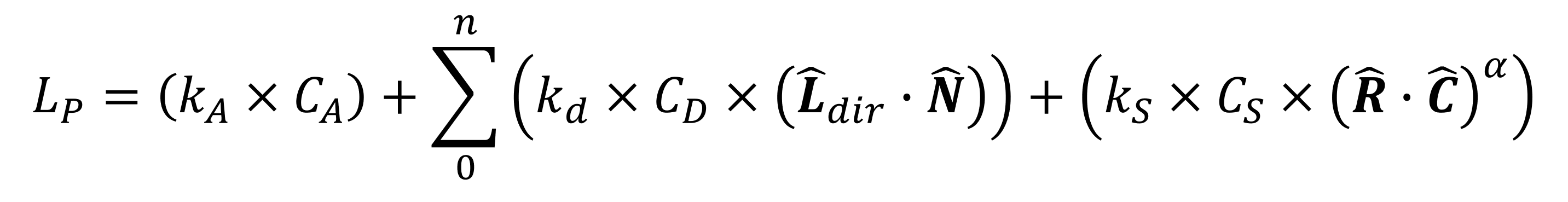
D'accord, donc beaucoup de choses à parcourir ici! Les valeurs indiquées par la lettre k sont des constantes de réflexion pour l'éclairage ambiant, diffus et spéculaire – chacune est le rapport de ce type particulier de lumière réfléchie à la quantité de lumière incidente; le C valeurs que nous avons vues dans les équations précédentes (les valeurs de couleur du matériau de surface, pour chaque type d'éclairage).
Le vecteur R est le vecteur de «réflexion parfaite» – la direction que prendrait la lumière réfléchie, si la surface était parfaitement lisse, et est calculé en utilisant la normale de la surface et le vecteur de lumière entrant. Le vecteur C est le vecteur de direction de la caméra; tous les deux R et C sont normalisés aussi.
Enfin, il y a une autre constante dans l'équation: la valeur de α détermine la brillance de la surface. Plus le matériau est lisse (c'est-à-dire plus il ressemble à du verre / métal), plus le nombre est élevé.
Cette équation est généralement appelée le modèle de réflexion de Phong, et au moment de la recherche originale, la proposition était radicale, car elle nécessitait une grande puissance de calcul. Une version simplifiée a été créée par Jim Blinn, qui a remplacé la section de la formule en utilisant R et C, avec H et N (vecteur à mi-chemin et surface normale). La valeur de R doit être calculé pour chaque lumière, pour chaque pixel dans un cadre, tandis que H ne doit être calculé qu'une seule fois par lumière, pour toute la scène.
Le modèle de réflexion Blinn-Phong est le système d'éclairage standard utilisé aujourd'hui, et est la méthode par défaut utilisée par Direct3D, OpenGL, Vulkan, etc.
Il existe de nombreux autres modèles mathématiques, surtout maintenant que les GPU peuvent traiter les pixels via des shaders vastes et complexes; ensemble, ces formules sont appelées fonctions de distribution de réflexion / transmission bidirectionnelle (BRDF / BTFD pour faire court) et ils forment la pierre angulaire de la coloration de chaque pixel que nous voyons sur nos moniteurs, lorsque nous jouons aux derniers jeux 3D.
Cependant, nous n'avons examiné que les surfaces reflétant la lumière: des matériaux translucides laisseront passer la lumière et, ce faisant, les rayons lumineux sont réfracté. Et certaines surfaces, comme l'eau, se refléteront et se transmettront dans chaque mesure.
Faire passer la lumière au niveau supérieur
Jetons un coup d'œil au titre d'Ubisoft 2018 Assassin's Creed: Odyssey – ce jeu vous oblige à passer beaucoup de temps à naviguer sur l'eau, que ce soit les rivières peu profondes et les régions côtières, ainsi que les mers profondes.

Pour rendre l'eau aussi réaliste que possible, mais aussi pour maintenir un niveau de performance approprié, les programmeurs d'Ubisoft ont utilisé une gamme d'astuces pour que tout fonctionne. La surface de l'eau est éclairée via le trio habituel de routines ambiantes, diffuses et spéculaires, mais il y a quelques ajouts soignés.
Le premier est couramment utilisé pour générer les propriétés réfléchissantes de l'eau: sréflexions de l'espace vert (SSR pour faire court). Cette technique fonctionne en rendant la scène mais avec les couleurs de pixel basées sur le profondeur de ce pixel – c'est-à-dire à quelle distance de l'appareil photo – et stocké dans ce qu'on appelle un tampon de profondeur. Ensuite, le cadre est à nouveau rendu, avec l'éclairage et la texture habituels, mais la scène est stockée en tant que texture de rendu, plutôt que le tampon final à envoyer au moniteur.
Après cela, une tache de Ray marchant est fait. Cela implique d'envoyer des rayons depuis la caméra, puis à des étapes définies le long du trajet du rayon, un code est exécuté pour vérifier la profondeur du rayon par rapport aux pixels dans le tampon de profondeur. Quand ils ont la même valeur, le code vérifie ensuite la normale du pixel pour voir s'il fait face à la caméra, et si c'est le cas, le moteur recherche ensuite le pixel pertinent à partir de la texture de rendu. Un autre ensemble d'instructions inverse ensuite la position du pixel, de sorte qu'il se reflète correctement dans la scène.

La lumière se diffusera également lorsqu'elle voyagera à travers les matériaux et pour l'eau et la peau, une autre astuce est utilisée – celle-ci est appelée diffusion sous la surface (SSS). Nous n'entrerons pas dans les détails de cette technique ici, mais vous pouvez en savoir plus sur la façon dont elle peut être utilisée pour produire des résultats étonnants, comme indiqué ci-dessous, dans une présentation de Nvidia en 2014.

Pour en revenir à l'eau dans Assassin's Creed, la mise en œuvre de SSS est très subtile, car elle n'est pas utilisée dans toute sa mesure pour des raisons de performances. Dans les titres AC précédents, Ubisoft employait de faux SSS mais dans la dernière version, son utilisation est plus complexe, mais toujours pas dans la même mesure que nous pouvons le voir dans la démo de Nvidia.
Des routines supplémentaires sont effectuées pour modifier les valeurs lumineuses à la surface de l'eau, afin de modéliser correctement les effets de la profondeur, en ajustant la transparence en fonction de la distance du rivage. Et lorsque la caméra regarde l'eau près du rivage, encore plus d'algorithmes sont traités pour tenir compte des caustiques et de la réfraction.
Le résultat est pour le moins impressionnant:

C'est couvert d'eau, mais qu'en est-il lorsque la lumière se déplace dans l'air? Les particules de poussière, l'humidité, etc. diffusent également la lumière. Cela se traduit par des rayons lumineux, comme nous les voyons, ayant le volume au lieu d'être juste une collection de rayons droits.
Le sujet de l'éclairage volumétrique pourrait facilement s'étendre à une douzaine d'articles supplémentaires, nous allons donc voir comment Rise of the Tomb Raider gère cela. Dans la vidéo ci-dessous, il y a 1 source de lumière principale: le Soleil, qui brille à travers une ouverture dans le bâtiment.
Pour créer le volume de lumière, le moteur de jeu prend le tronc de la caméra (voir ci-dessous) et le découpe exponentiellement en fonction de la profondeur en 64 sections. Chaque tranche est ensuite tramée en grilles de 160 x 94 éléments, le tout étant stocké dans une texture de rendu FP32 tridimensionnelle. Comme les textures sont normalement 2D, les «pixels» du volume du tronc sont appelés voxels.
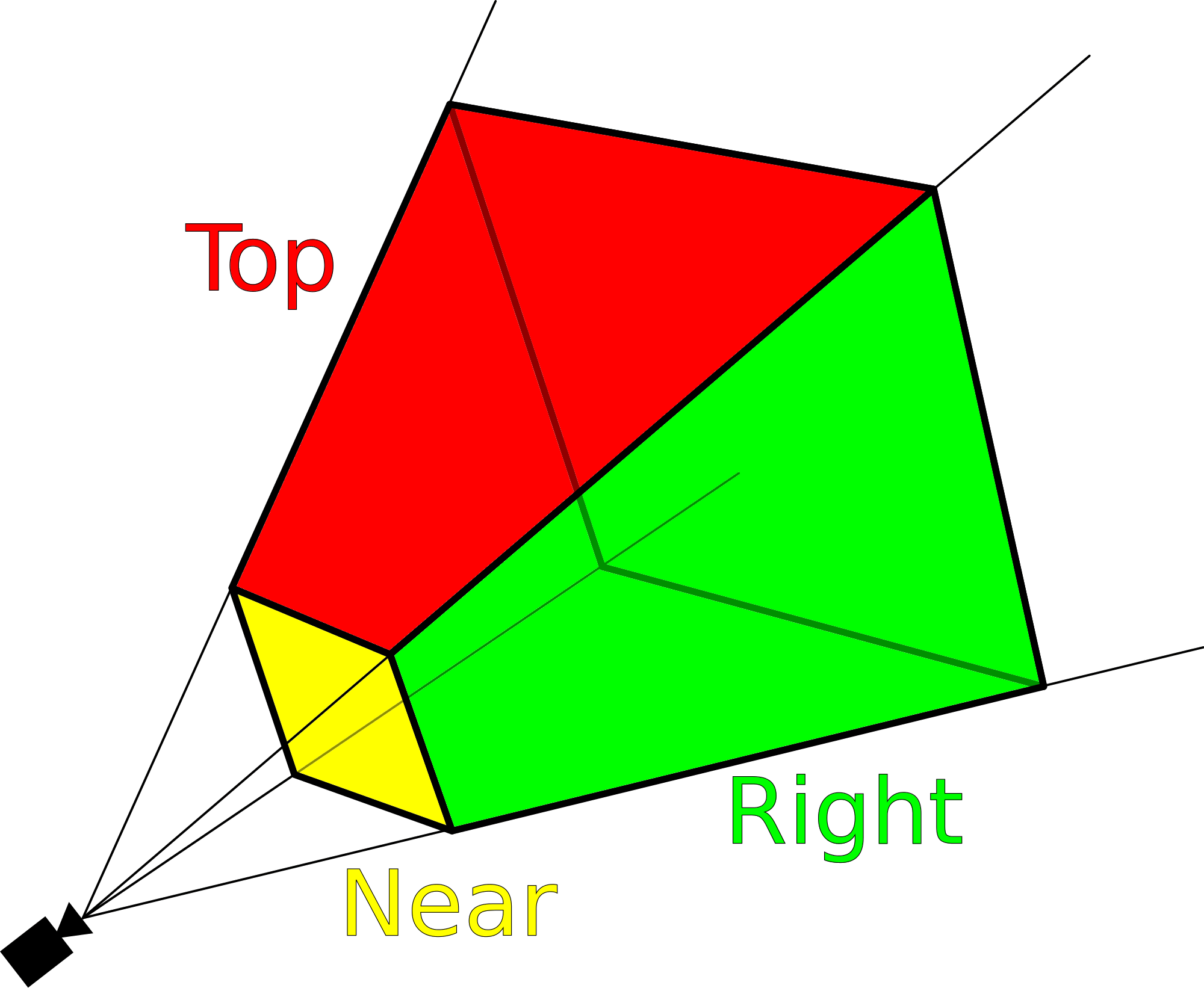
Pour un bloc de 4 x 4 x 4 voxels, les shaders de calcul déterminent quelles lumières actives affectent ce volume et écrivent ces informations dans une autre texture de rendu 3D. Une formule complexe, connue sous le nom de fonction de diffusion Henyey-Greenstein, est ensuite utilisée pour estimer la «densité» globale de la lumière dans le bloc de voxels.
Le moteur exécute ensuite quelques shaders supplémentaires pour nettoyer les données, avant que la marche des rayons ne soit effectuée à travers les tranches de tronc, accumulant les valeurs de densité lumineuse. Sur Xbox One, Eidos-Montréal déclare que tout cela peut se faire en environ 0,8 milliseconde!
Bien que ce ne soit pas la méthode utilisée par tous les jeux, l'éclairage volumétrique est désormais prévu dans presque tous les meilleurs titres 3D sortis aujourd'hui, en particulier les jeux de tir à la première personne et les aventures d'action.

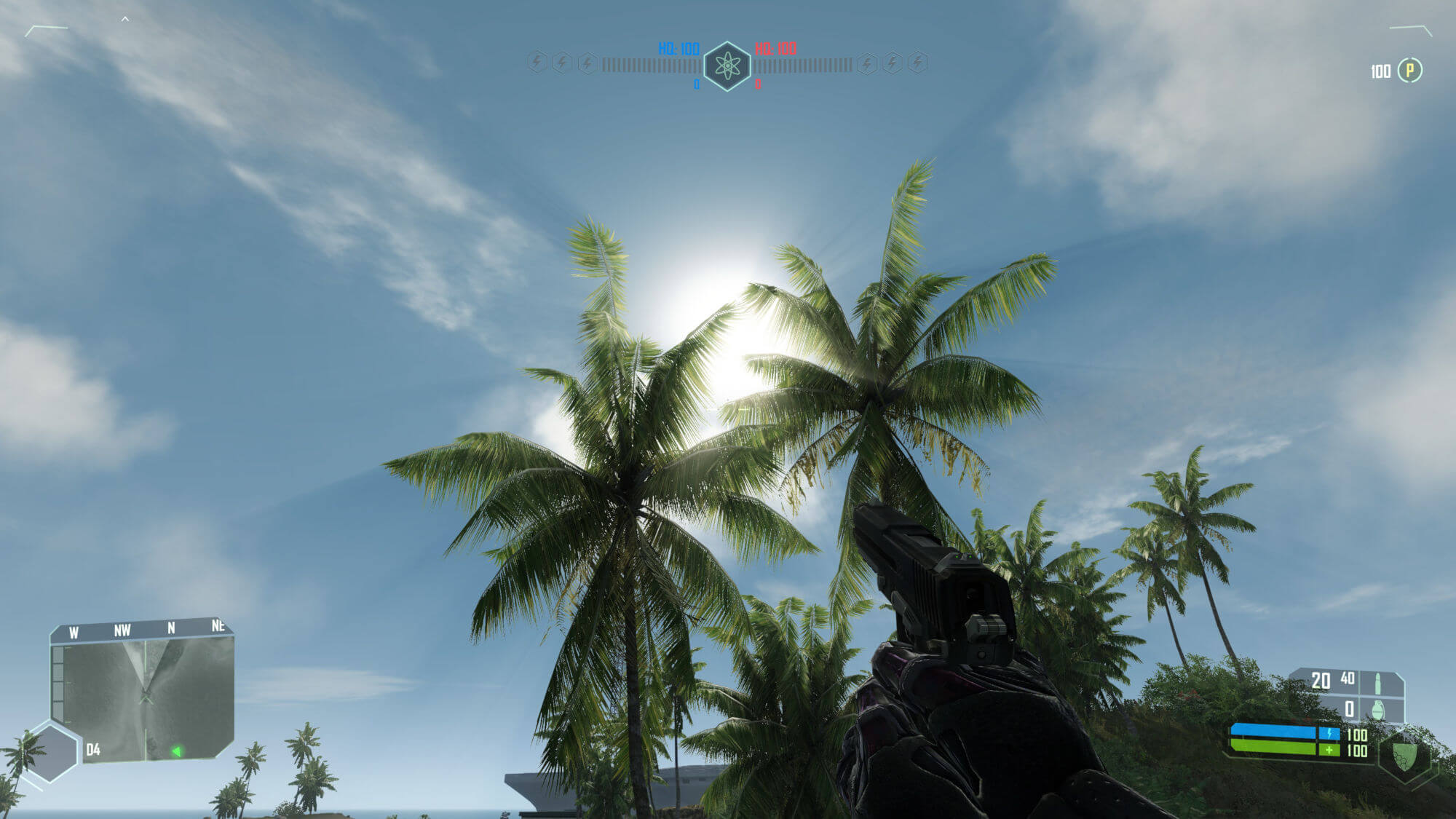
À l'origine, cette technique d'éclairage était appelée «rayons divins» – ou pour donner le terme scientifique correct, rayons crépusculaires – et l'un des premiers titres à l'utiliser, a été l'original Crysis de Crytek, en 2007.
Ce n'était pas vraiment un éclairage volumétrique, car le processus impliquait d'abord de rendre la scène comme un tampon de profondeur et de l'utiliser pour créer un masque – un autre tampon où les couleurs des pixels sont plus sombres plus elles sont proches de la caméra.
Ce tampon de masque est échantillonné plusieurs fois, avec un shader prenant les échantillons et les brouillant ensemble. Ce résultat est ensuite mélangé avec la scène finale, comme indiqué ci-dessous:
Le développement des cartes graphiques au cours des 12 dernières années a été colossal. Le GPU le plus puissant au moment du lancement de Crysis était le GeForce 8800 Ultra de Nvidia – le GPU le plus rapide d'aujourd'hui, le GeForce RTX 2080 Ti a plus de 30 fois plus de puissance de calcul, 14 fois plus de mémoire et 6 fois plus de bande passante.
Tirant parti de toute cette puissance de calcul, les jeux d'aujourd'hui peuvent faire un bien meilleur travail en termes de précision visuelle et de performances globales, malgré l'augmentation de la complexité du rendu.
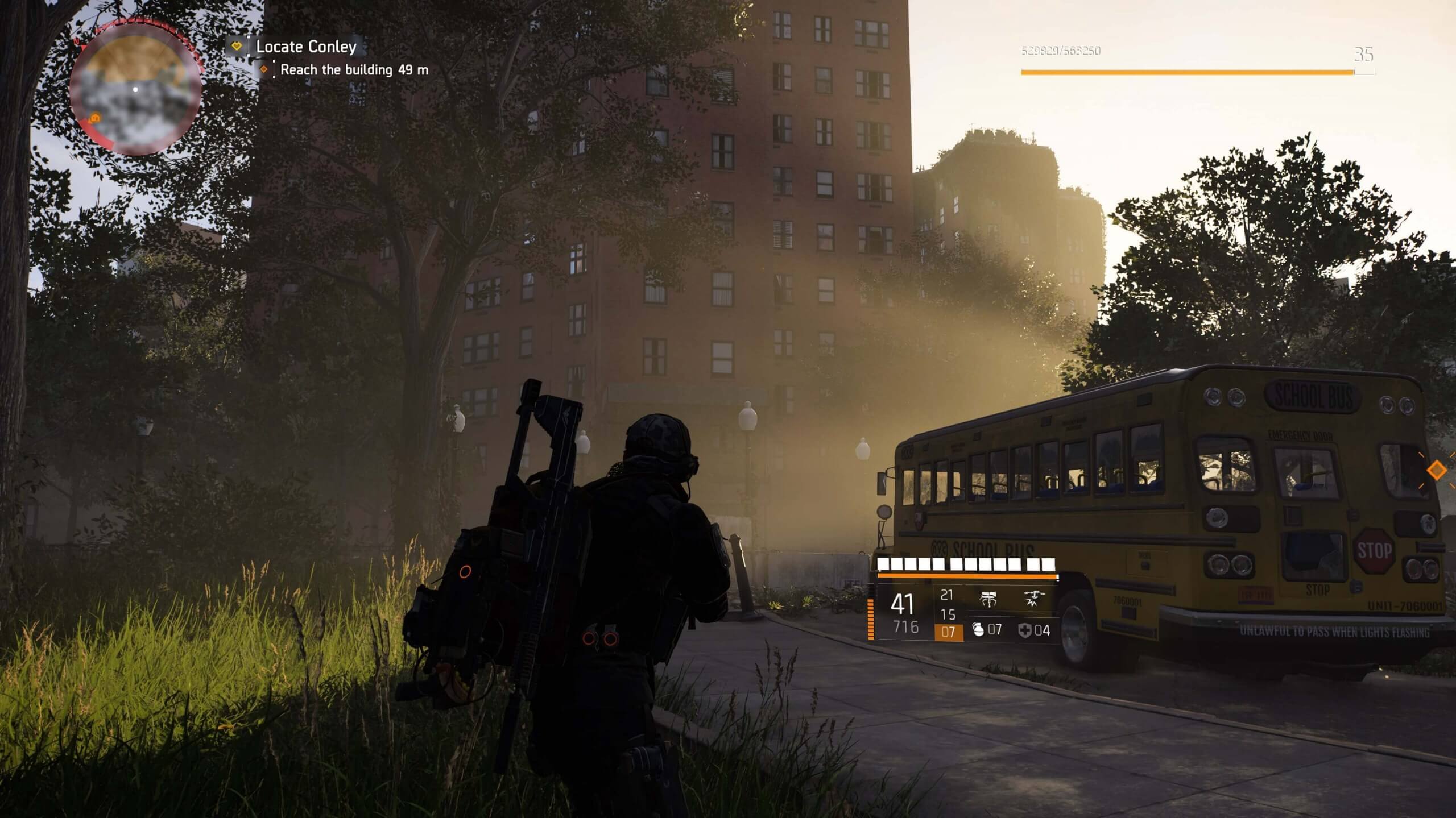
Mais ce que l’effet démontre vraiment, c’est que l’éclairage est aussi important que la précision visuelle, la absence c'est la lumière qui fait vraiment la différence.
L'essence d'une ombre
Utilisons l'Ombre du Tomb Raider pour commencer notre prochaine section de cet article. Dans l'image ci-dessous, tous les paramètres graphiques liés aux ombres ont été désactivés; à droite, ils sont tous allumés. Quelle différence, non?

Puisque les ombres se produisent naturellement autour de nous, tout jeu qui les fait mal n'aura jamais l'air bien. C'est parce que notre cerveau est réglé pour utiliser les ombres comme références visuelles, pour générer un sentiment de profondeur relative, d'emplacement et de mouvement. Mais faire cela dans un jeu 3D est étonnamment difficile, ou à tout le moins, difficile à faire correctement.
Commençons par un canard . Ici, elle se dandine dans un champ, et les rayons lumineux du Soleil atteignent notre canard et se bloquent comme prévu.
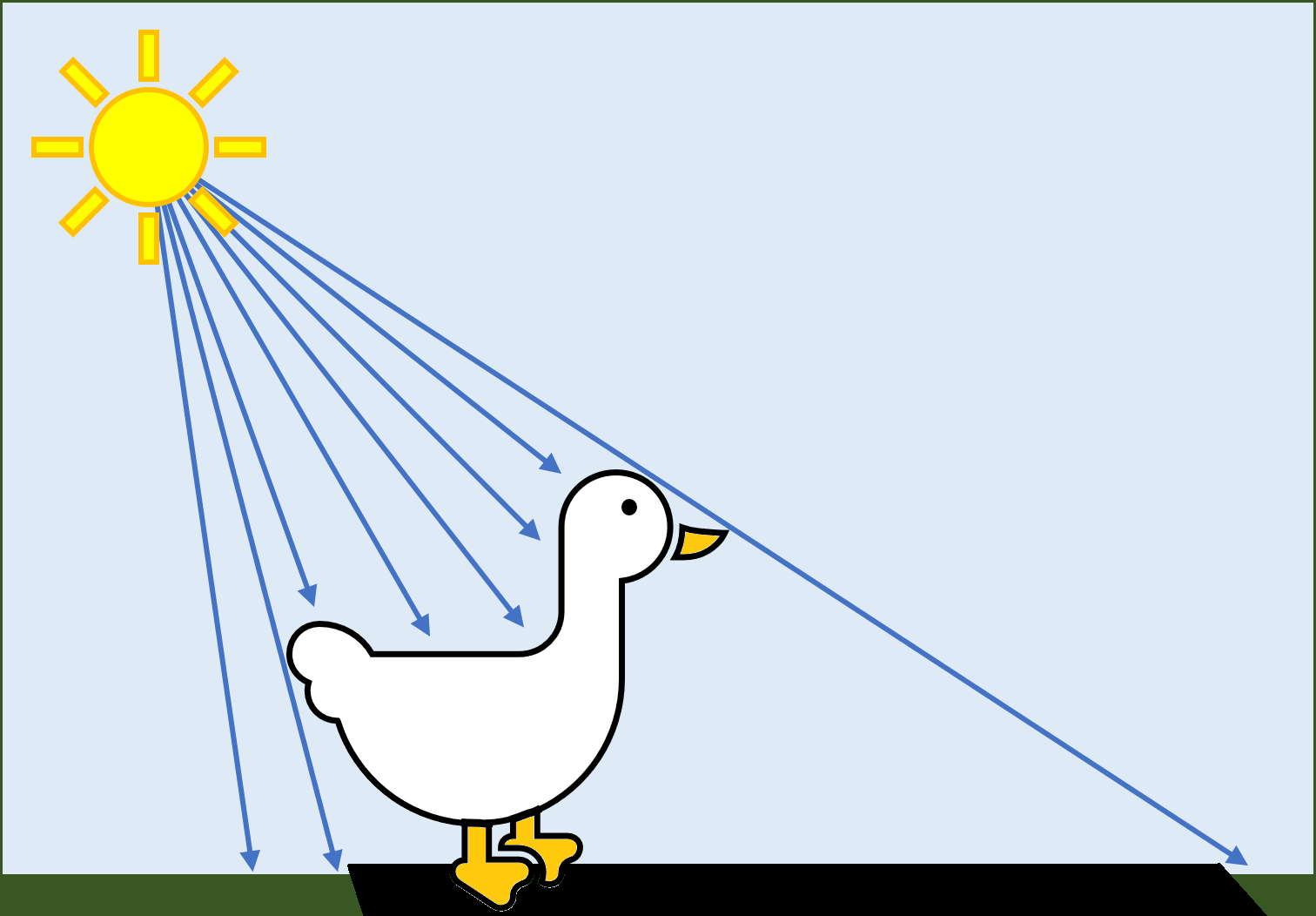
L'une des premières méthodes pour ajouter une ombre à une scène comme celle-ci consiste à ajouter une ombre «blob» sous le modèle. Ce n'est pas du tout réaliste, car la forme de l'ombre n'a rien à voir avec la forme de l'objet projetant l'ombre; cependant, ils sont rapides et simples à faire.
Les premiers jeux 3D, comme le jeu original Tomb Raider de 1996, utilisaient cette méthode comme matériel à l'époque – comme Sega Saturn et Sony PlayStation – n'avaient pas la capacité de faire beaucoup mieux. La technique consiste à dessiner une simple collection de primitives juste au-dessus de la surface sur laquelle le modèle se déplace, puis à ombrer le tout; une alternative à cela serait de dessiner une texture simple en dessous.

Une autre première méthode était projection d'ombre. Dans ce processus, la projection primitive de l'ombre est projetée sur le plan contenant le sol. Certains calculs ont été développés par Jim Blinn à la fin des années 80. C'est un processus simple, selon les normes d'aujourd'hui, et qui fonctionne mieux pour des objets simples et statiques.
Mais avec une certaine optimisation, la projection d'ombres a fourni les premières tentatives décentes d'ombres dynamiques, comme on le voit dans le titre Interplay de 1999, Kingpin: Life of Crime. Comme nous pouvons le voir ci-dessous, seuls les personnages animés (y compris les rats!) Ont des ombres, mais c'est mieux que de simples blobs.
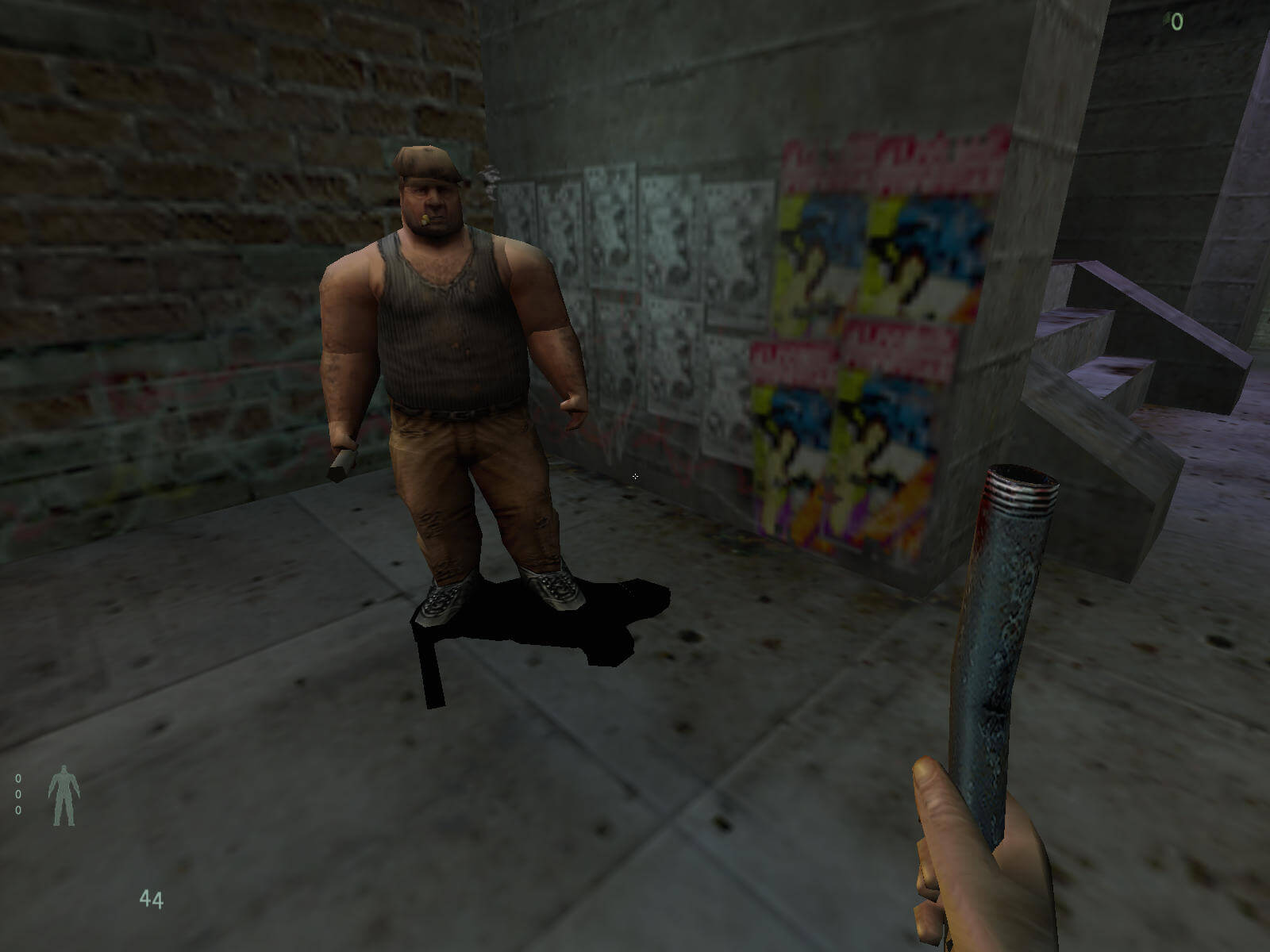
Les plus gros problèmes avec eux sont: (a) l'opacité totale de l'ombre réelle et (b) la méthode de projection repose sur la projection de l'ombre sur un seul plan plat (c'est-à-dire le sol).
Ces problèmes pourraient être résolus en appliquant un certain degré de transparence à la coloration de la primitive projetée et en effectuant plusieurs projets pour chaque personnage, mais les capacités matérielles des PC à la fin des années 90 n'étaient tout simplement pas à la hauteur des exigences du rendu supplémentaire.
La technologie moderne derrière une ombre
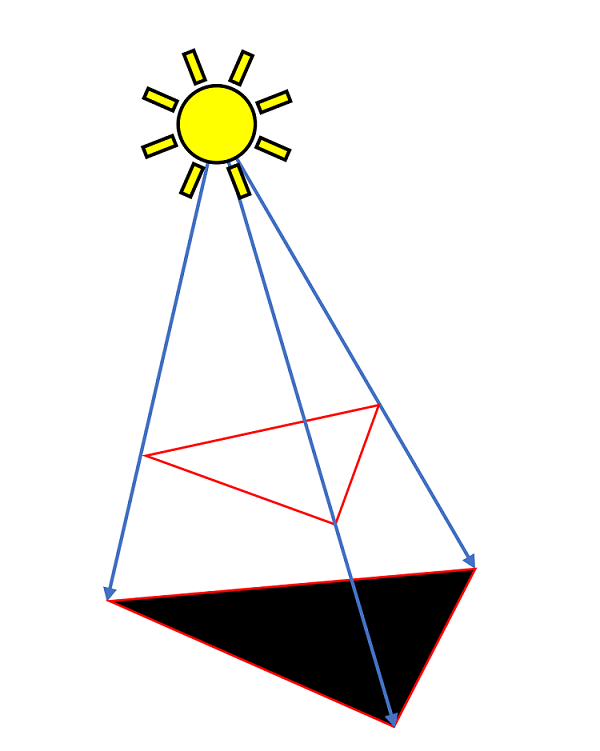
Une façon plus précise de faire des ombres a été proposée bien avant cela, en 1977. Tout en travaillant à l'Université d'Austin, au Texas, Franklin Crow a écrit un document de recherche dans lequel il proposait plusieurs techniques qui impliquaient toutes l'utilisation de l'ombre volumes.
Généralisé, le processus détermine quelles primitives font face à la source de lumière, et les bords de celles-ci sont étendus sont étendus sur un plan. Jusqu'à présent, cela ressemble beaucoup à la projection d'ombres, mais la principale différence est que le volume d'ombres créé est ensuite utilisé pour vérifier si un pixel est à l'intérieur / à l'extérieur du volume. À partir de ces informations, toutes les surfaces peuvent maintenant être projetées avec des ombres, et pas seulement avec le sol.
La technique a été améliorée par Tim Heidmann, tout en travaillant pour Silicon Graphics en 1991, plus loin encore par Mark Kilgard en 1999, et pour la méthode que nous allons examiner, John Carmack chez id Software en 2000 (bien que la méthode de Carmack était indépendante découvert 2 ans plus tôt par Bilodeau et Songy à Creative Labs, ce qui a amené Carmack à peaufiner son code pour éviter les tracas du procès).
L'approche nécessite que le cadre soit rendu plusieurs fois (appelé multipass le rendu — très exigeante pour le début des années 90, mais omniprésente maintenant) et quelque chose appelé tampon de pochoir.
Contrairement aux tampons de cadre et de profondeur, cela n'est pas créé par la scène 3D elle-même – au lieu de cela, le tampon est un tableau de valeurs, de dimensions égales (c'est-à-dire les mêmes X,y résolution) comme raster. Les valeurs stockées sont utilisées pour indiquer au moteur de rendu ce qu'il faut faire pour chaque pixel dans le tampon d'image.
L'utilisation la plus simple du tampon est comme masque:
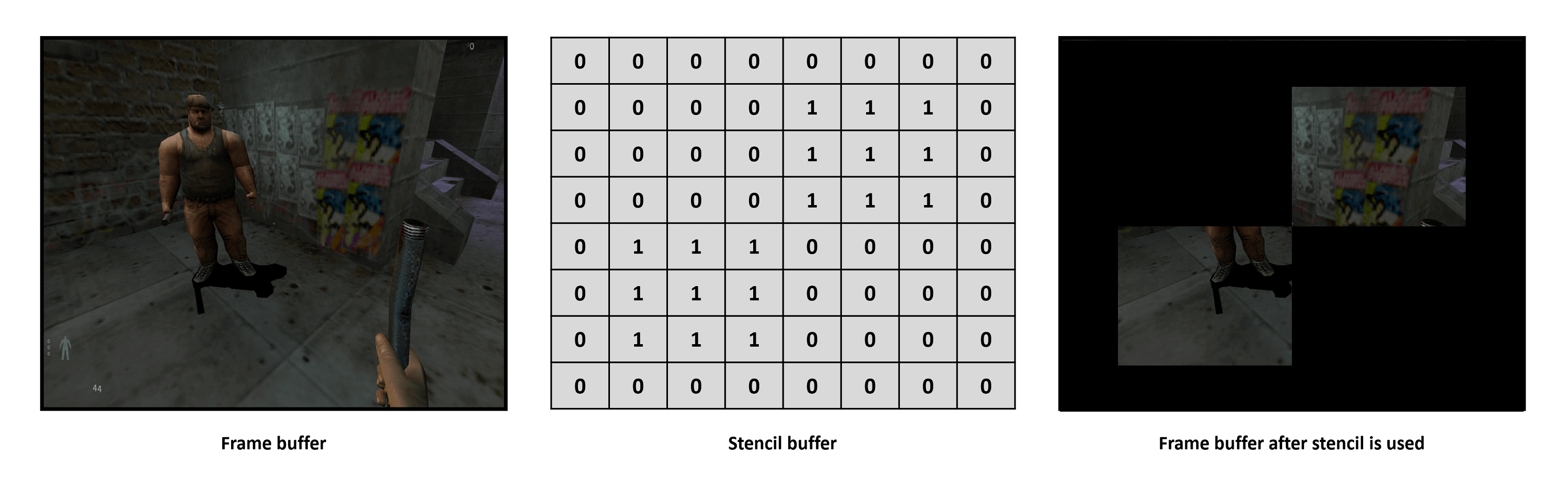
La méthode du volume fantôme ressemble à ceci:
- Rendez la scène dans un tampon d'image, mais utilisez simplement l'éclairage ambiant (incluez également toutes les valeurs d'émission si le pixel contient une source de lumière)
- Rendre la scène à nouveau, mais uniquement pour les surfaces faisant face à la caméra (aka abattage face arrière). Pour chaque source de lumière, calculez les volumes d'ombre (comme la méthode de projection) et vérifiez la profondeur de chaque pixel d'image par rapport aux dimensions du volume. Pour ceux à l'intérieur le volume d'ombre (c'est-à-dire que le test de profondeur a « échoué ''), augmentez la valeur dans le tampon de pochoir correspondant à ce pixel.
- Répétez les étapes ci-dessus, mais avec l'élimination de la face avant activée et les entrées du tampon de gabarit ont diminué si elles sont dans le volume.
- Rendez la scène entière à nouveau, mais cette fois avec tout l'éclairage activé, mais mélangez ensuite les tampons de trame finale et de pochoir ensemble.
Nous pouvons voir cette utilisation des tampons de stencil et des volumes d'ombre (communément appelés ombres de stencil) dans la version 2004 de Doom 3 d'id Software:

Remarquez comment le chemin sur lequel le personnage marche est toujours visible à travers l'ombre? Il s'agit de la première amélioration par rapport aux projections d'ombres – d'autres incluent la possibilité de tenir correctement compte de la distance de la source de lumière (ce qui entraîne des ombres plus faibles) et de projeter des ombres sur n'importe quelle surface (y compris le personnage lui-même).
Mais la technique présente de sérieux inconvénients, dont le plus notable est que les bords de l'ombre dépendent entièrement du nombre de primitives utilisées pour faire l'objet projetant l'ombre. Cela, et le fait que la nature multipasse implique beaucoup de lecture / écriture dans la mémoire locale, peut rendre l'utilisation des ombres de pochoir un peu moche et plutôt coûteuse en termes de performances.
Il y a aussi une limite au nombre de volumes fantômes qui peuvent être vérifiés avec le tampon de gabarit – c'est parce que toutes les API graphiques lui allouent un nombre relativement faible de bits (généralement seulement 8). Le coût de performance des ombres au pochoir empêche généralement ce problème d'apparaître.
Enfin, il y a le problème que les ombres elles-mêmes ne sont pas réalistes à distance. Pourquoi? Parce que toutes les sources de lumière, des lampes aux incendies, des lampes de poche au soleil, ne sont pas des points uniques dans l'espace – c'est-à-dire qu'elles émettent de la lumière sur une zone. Même si l'on prend cela à son niveau le plus simple, comme indiqué ci-dessous, les vraies ombres ont rarement un bord dur bien défini.
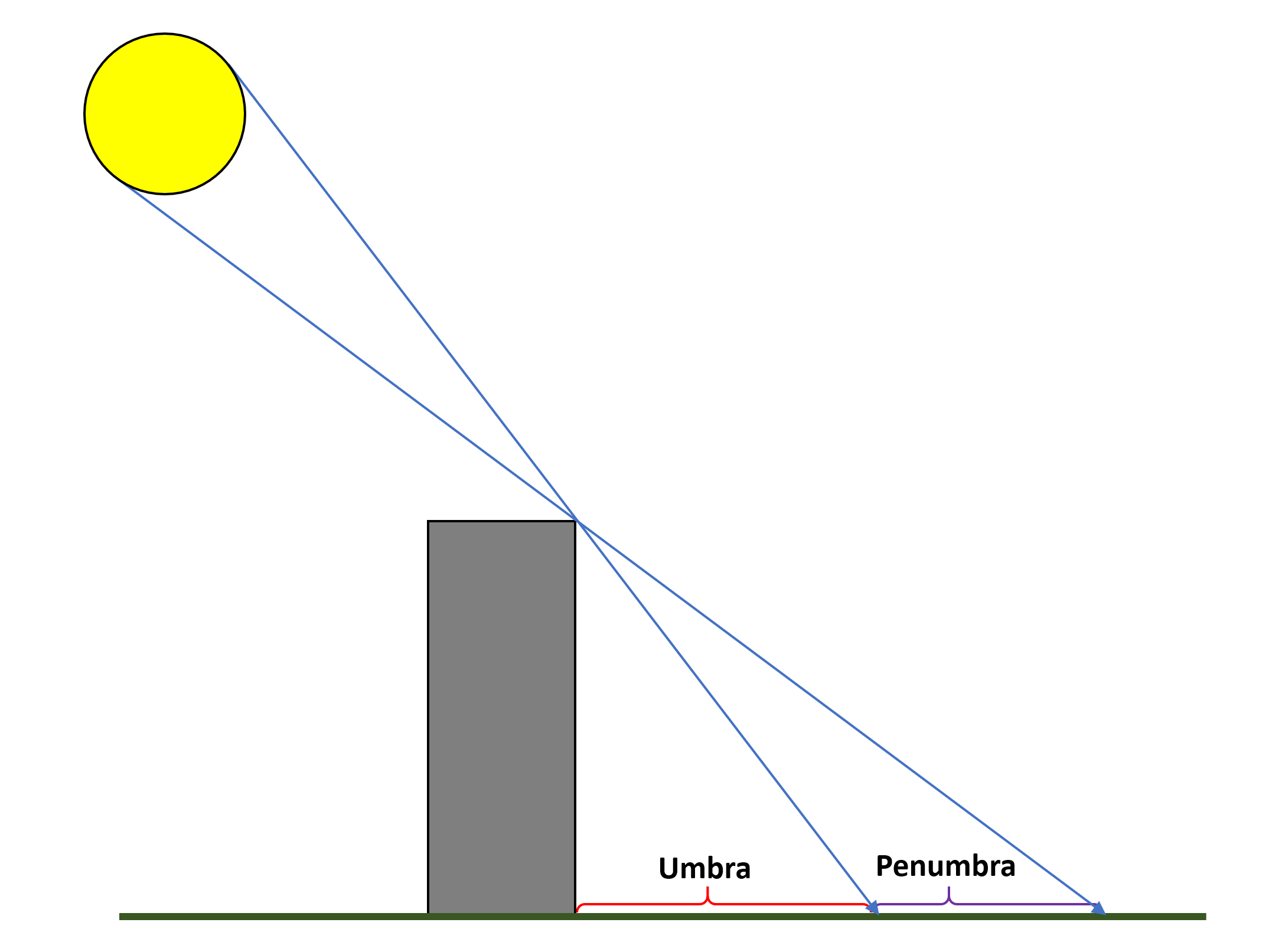
La zone la plus sombre de l'ombre s'appelle l'ombre; la pénombre est toujours une ombre plus claire, et la frontière entre les deux est souvent "floue" (en raison du fait qu'il y a beaucoup de sources de lumière). Cela ne peut pas être très bien modélisé à l'aide de tampons et de volumes de gabarit, car les ombres produites ne sont pas stockées de manière à pouvoir être traitées. Entrer cartographie des ombres à la rescousse!
La procédure de base a été développée par Lance Williams en 1978 et elle est relativement simple:
- Pour chaque source de lumière, restituez la scène du point de vue de la lumière, créant une texture de profondeur spéciale (donc pas de couleur, d'éclairage, de texturation, etc.). La résolution de ce tampon ne doit pas nécessairement être la même que celle de l'image finale, mais une valeur plus élevée est meilleure.
- Rendez ensuite la scène du point de vue de la caméra, mais une fois le cadre tramé, la position de chaque pixel (en termes de x, y et z) est transformée en utilisant une source de lumière comme origine du système de coordonnées.
- La profondeur du pixel transformé est comparée au pixel correspondant dans la texture de profondeur stockée: si elle est inférieure, le pixel sera une ombre et n'obtiendra pas la procédure d'éclairage complète.
Il s'agit évidemment d'une autre procédure multipasse, mais la dernière étape peut être effectuée à l'aide de pixel shaders de sorte que la vérification de la profondeur et les calculs d'éclairage ultérieurs soient tous roulés dans la même passe. Et parce que l'ensemble du processus d'observation est indépendant de la façon dont les primitives sont utilisées, il est beaucoup plus rapide que d'utiliser le tampon de gabarit et les volumes d'ombre.
Malheureusement, la méthode de base décrite ci-dessus génère toutes sortes d'artefacts visuels (tels que l'aliasing en perspective, l'acné fantôme, le « peter panning ''), dont la plupart tournent autour de la résolution et de la taille en bits de la texture de profondeur. Tous les GPU et API graphiques ont des limites à de telles textures, donc toute une série de techniques supplémentaires ont été créées pour résoudre les problèmes.
Un avantage de l'utilisation d'une texture pour les informations de profondeur est que les GPU ont la possibilité de les échantillonner et de les filtrer très rapidement et via un certain nombre de façons. En 2005, Nvidia a démontré une méthode pour échantillonner la texture afin que certains des problèmes visuels causés par la cartographie d'ombre standard soient résolus, et il a également fourni un certain degré de douceur aux bords de l'ombre; la technique est connue sous le nom de filtrage plus proche en pourcentage.
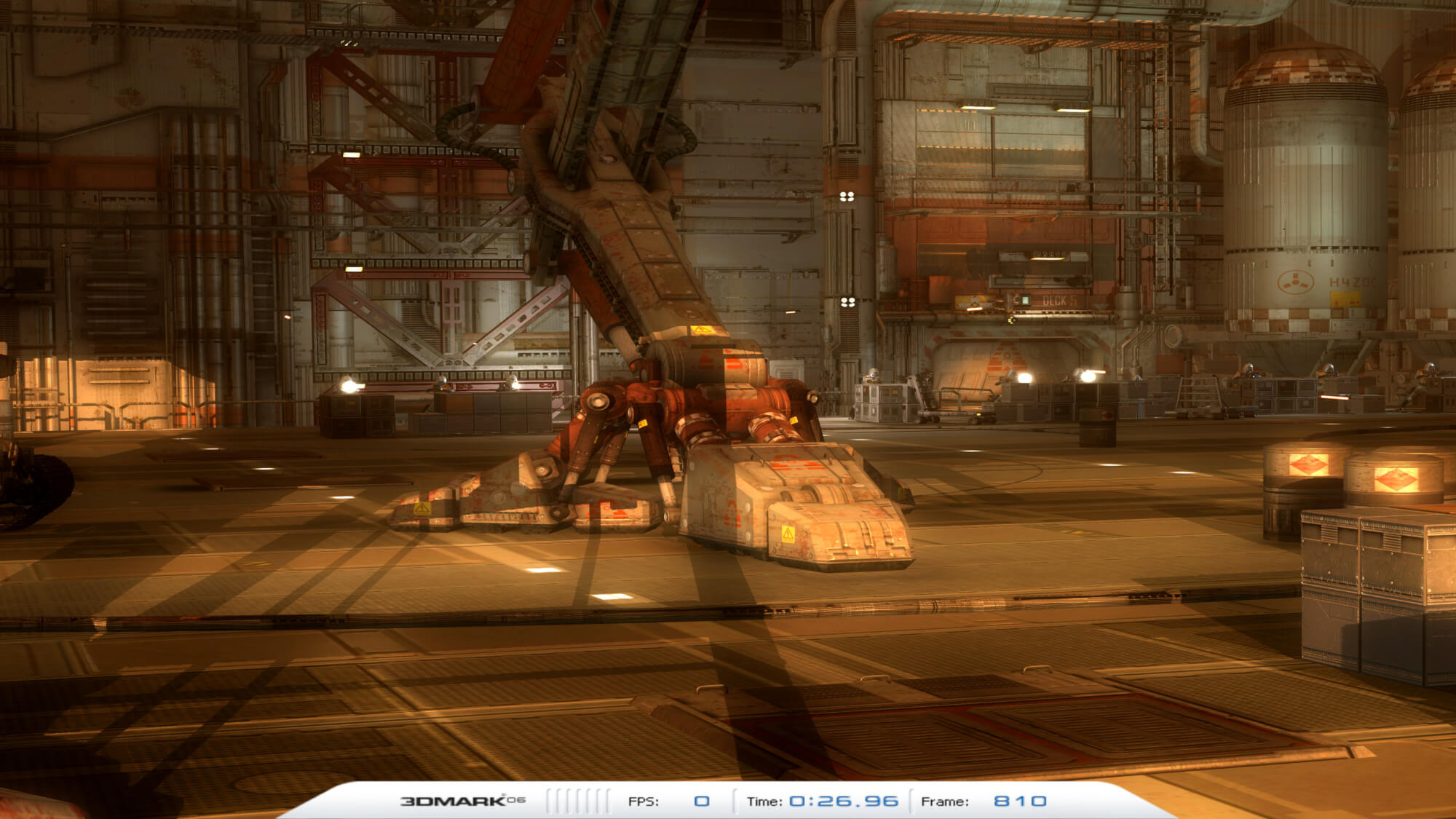
À peu près à la même époque, Futuremark a démontré l'utilisation de cartes d'ombres en cascade (CSM) dans 3DMark06, une technique où plusieurs textures de profondeur, de différentes résolutions, sont créées pour chaque source de lumière. Des textures de résolutions plus élevées sont utilisées plus près de la lumière, avec des textures détaillées plus faibles utilisées à de plus grandes distances de la lumière. Le résultat est une transition plus transparente, sans distorsion, des ombres à travers une scène.
La technique a été améliorée par Donnelly et Laurizten en 2006 avec leur routine de cartographie de l'ombre de la variance (VSM), et par Intel en 2010 avec leur algorithme de distribution d'échantillons (SDSM).

Les développeurs de jeux utilisent souvent une batterie de techniques d'observation pour améliorer les visuels, mais la cartographie des ombres dans son ensemble régit le perchoir. Cependant, il ne peut être appliqué qu'à un petit nombre de sources de lumière actives, car essayer de le modéliser sur chaque surface unique qui réfléchit ou émet de la lumière réduirait la fréquence d'images en poussière.
Heureusement, il existe une technique soignée qui fonctionne bien avec n'importe quel objet, donnant l'impression que la lumière atteignant l'objet est réduite (car lui-même ou d'autres objets le bloquent un peu). Le nom de cette fonctionnalité est occlusion ambiante et il en existe plusieurs versions. Certains ont été spécifiquement développés par des fournisseurs de matériel, par exemple AMD a créé HDAO (occlusion ambiante haute définition) et Nvidia possède HBAO + (occlusion ambiante basée sur l'horizon).
Quelle que soit la version utilisée, elle est appliquée après le rendu complet de la scène, elle est donc classée comme post-traitement effet, et pour chaque pixel, le code calcule essentiellement la visibilité de ce pixel dans la scène (voir plus sur comment cela se fait ici et ici), en comparant la valeur de profondeur du pixel avec les pixels environnants à l'emplacement correspondant dans le tampon de profondeur (qui est , encore une fois, stocké sous forme de texture).
L'échantillonnage du tampon de profondeur et le calcul ultérieur de la couleur finale des pixels jouent un rôle important dans la qualité de l'occlusion ambiante; et tout comme le mapping d'ombres, toutes les versions d'occlusion ambiante nécessitent que le programmeur ajuste et ajuste leur code, au cas par cas, pour s'assurer que l'effet fonctionne correctement.

Fait correctement, cependant, et l'impact de l'effet visuel est profond. Dans l'image ci-dessus, examinez de près les bras de l'homme, les ananas et les bananes, ainsi que l'herbe et le feuillage environnants. The changes in pixel color that the use of HBAO+ has produced are relatively minor, but all of the objects now look grounded (in the left, the man looks like he's floating above the soil).
Pick any of the recent games covered in this article, and their list of rendering techniques for handling light and shadow will be as long as this feature piece. And while not every latest 3D title will boast all of these, the fact that universal game engines, such as Unreal, offer them as options to be enabled, and toolkits from the likes of Nvidia provide code to be dropped right in, shows that they're not classed as highly specialized, cutting-edge methods — once the preserve of the very best programmers, almost anyone can utilize the technology.
We couldn't finish this article on lighting and shadowing in 3D rendering without talking about ray tracing. We've already covered the process in this series, but the current employment of the technology demands we accept low frame rates and an empty bank balance.
With next generation consoles from Microsoft and Sony supporting it though, that means that within a few years, its use will become another standard tool by developers around the world, looking to improve the visual quality of their games to cinematic standards. Just look at what Remedy managed with their latest title Control:
We've come a long way from fake shadows in textures and basic ambient lighting!
There's so much more to cover
In this article, we've tried to cover some of the fundamental math and techniques employed in 3D games to make them look as realistic as possible, looking at the technology behind the modelling of how light interacts with objects and materials. And this has been just a small taste of it all.
For example, we skipped things such as energy conservation lighting, lens flare, bloom, high dynamic rendering, radiance transfer, tonemapping, fogging, chromatic aberration, photon mapping, caustics, radiosity — the list goes on and on. It would take another 3 or 4 articles just to cover them, as briefly as we have with this feature's content.
We're sure that you've got some great stories to tell about games that have amazed you with their visual tricks, so when you're blasting your way through Call of Mario: Deathduty Battleyard or similar, spare a moment to look at those graphics and marvel at what's going on behind the scenes to make those images. Yes, it's nothing more than math and electricity, but the results are an optical smorgasbord. Any questions: fire them our way, too! Until the next one.