
En dépit d'améliorations continues et de mises à niveau progressives apportées à chaque nouvelle génération, les processeurs n'ont connu aucun progrès important dans l'industrie depuis longtemps. Le passage des tubes à vide aux transistors était énorme. Le passage de composants individuels à des circuits intégrés était énorme. Après cela, il n’ya pas eu d’autres changements de paradigme similaires à cette échelle.
Oui, les transistors sont devenus plus petits, les puces sont devenues plus rapides et les performances ont été multipliées par 100, mais nous commençons à constater des rendements décroissants …
Ceci est le quatrième et dernier volet de notre série de conception de CPU, vous donnant un aperçu de la conception et de la fabrication des processeurs informatiques. En commençant par le haut, nous avons examiné la manière dont le code informatique est compilé en langage assembleur et converti en instructions binaires interprétables par le processeur. Nous avons examiné l'architecture des processeurs et les instructions de processus. Ensuite, nous avons examiné les différentes structures qui constituent un processeur.
Pour aller un peu plus loin, nous avons vu comment ces structures sont construites et comment des milliards de transistors fonctionnent ensemble dans un processeur. Nous avons examiné la manière dont les processeurs sont physiquement fabriqués à partir de silicium brut. Nous avons appris les bases des semi-conducteurs et à quoi ressemble réellement l'intérieur d'une puce. Si vous avez oublié quelque chose, voici un index de la série:
Passons à la quatrième partie. Étant donné que les entreprises ne partagent pas leurs recherches ni les détails de leur technologie actuelle, il est difficile de savoir exactement ce que contient le processeur de votre ordinateur. Ce que nous pouvons faire, cependant, est d’examiner la recherche actuelle et la direction que prend l’industrie.
La loi de Moore est une représentation célèbre de l'industrie des processeurs. Ceci décrit comment le nombre de transistors dans une puce double environ tous les 18 mois. Cela a été vrai pendant très longtemps, mais commence à ralentir. Les transistors deviennent si petits que nous approchons de la limite de ce que la physique permettra. Sans une nouvelle technologie révolutionnaire, nous devrons explorer différentes pistes pour optimiser les performances futures.
La loi de Moore sur 120 ans
Une conséquence directe de cette ventilation est que les entreprises ont commencé à augmenter le nombre de leurs tâches principales plutôt que leur fréquence pour améliorer les performances. C’est la raison pour laquelle nous voyons des processeurs octa-core s’intégrer au marché central plutôt que des puces dual core 10 GHz. Il ne reste tout simplement plus beaucoup de place pour une croissance au-delà du simple ajout de cœurs.
Sur une note complètement différente, L'informatique quantique est un domaine qui promet beaucoup de possibilités de croissance à l’avenir. Je ne suis pas un expert en la matière et, comme la technologie est toujours en cours de création, il n’ya pas beaucoup de vrais "experts". Pour dissiper tous les mythes, l'informatique quantique n'est pas quelque chose qui vous rapportera 1 000 images par seconde dans un rendu réel ou similaire. Pour l'instant, le principal avantage des ordinateurs quantiques est qu'ils permettent l'utilisation d'algorithmes plus avancés qui n'étaient auparavant pas réalisables.

Un des prototypes IBM Quantum Computer
Dans un ordinateur traditionnel, un transistor est allumé ou éteint, ce qui représente un 0 ou un 1. Dans un ordinateur quantique, superposition est possible, ce qui signifie que le bit peut être à la fois égal à 0 et à 1. Avec cette nouvelle capacité, les informaticiens peuvent développer de nouvelles méthodes de calcul et seront capables de résoudre des problèmes pour lesquels nous ne disposons pas des capacités de calcul. Ce n’est pas tellement que les ordinateurs quantiques sont plus rapides, c’est un nouveau modèle de calcul qui nous permettra de résoudre différents types de problèmes.
La technologie pour cela est encore à une décennie ou deux du courant dominant, alors quelles sont les tendances que nous commençons à observer chez les vrais processeurs en ce moment? Il existe des dizaines de domaines de recherche actifs, mais je vais en aborder quelques-uns qui ont le plus d'impact à mon avis.
Une tendance croissante qui nous a touché est informatique hétérogène. Cette méthode consiste à inclure plusieurs éléments informatiques différents dans un même système. La plupart d’entre nous en bénéficient sous la forme d’un GPU dédié dans nos systèmes. Un processeur est très personnalisable et peut effectuer une grande variété de calculs à une vitesse raisonnable. Un GPU, en revanche, est spécialement conçu pour effectuer des calculs graphiques tels que la multiplication de matrices. Il est vraiment bon à cela et est des ordres de grandeur plus rapides qu'un processeur à ces types d'instructions. En déchargeant certains calculs graphiques de la CPU vers le GPU, nous pouvons accélérer la charge de travail. Il est facile pour tout programmeur d’optimiser un logiciel en modifiant un algorithme, mais l’optimisation matérielle est beaucoup plus difficile.
Mais les GPU ne sont pas le seul domaine où les accélérateurs deviennent courants. La plupart des smartphones ont des dizaines d'accélérateurs matériels conçus pour accélérer des tâches très spécifiques. Ce style informatique est connu sous le nom de Mer des accélérateurs Les exemples incluent les processeurs de cryptographie, les processeurs d’image, les accélérateurs d’apprentissage automatique, les encodeurs / décodeurs vidéo, les processeurs biométriques, etc.
À mesure que les charges de travail deviennent de plus en plus spécialisées, les concepteurs de matériel incluent de plus en plus d'accélérateurs dans leurs puces. Les fournisseurs d'informatique en nuage tels qu'AWS ont commencé à fournir des cartes FPGA aux développeurs pour accélérer leurs charges de travail dans le nuage. Alors que les éléments informatiques traditionnels tels que les CPU et les GPU ont une architecture interne fixe, un FPGA est flexible. C'est presque comme du matériel programmable qui peut être configuré pour répondre à tous vos besoins informatiques.
Si vous voulez faire la reconnaissance d'image, vous pouvez implémenter ces algorithmes dans le matériel. Si vous souhaitez simuler le fonctionnement d'une nouvelle conception matérielle, vous pouvez le tester sur le FPGA avant de le construire. Un FPGA offre plus de performances et d'efficacité énergétique que les GPU, mais reste inférieur à un ASIC (circuit intégré à application spécifique). D'autres sociétés telles que Google et Nvidia développent des ASIC dédiés à l'apprentissage automatique afin d'accélérer la reconnaissance et l'analyse des images.
Coups de poing montrant la composition de plusieurs processeurs mobiles courants

En regardant les coups de poing de processeurs assez récents, nous pouvons voir que la majeure partie de la zone de la CPU n'est pas réellement le noyau lui-même. Une quantité croissante est absorbée par des accélérateurs de tous types. Cela a permis d'accélérer des charges de travail très spécialisées, en plus des avantages liés aux énormes économies d'énergie.
Historiquement, si vous vouliez ajouter un traitement vidéo à un système, il vous suffisait d'ajouter une puce pour le faire. C'est extrêmement inefficace cependant. Chaque fois qu'un signal doit sortir d'une puce d'un fil physique vers une autre puce, une grande quantité d'énergie est requise par bit. À elle seule, une infime fraction de Joule peut ne pas sembler beaucoup, mais elle peut être 3 à 4 ordres de grandeur plus efficace pour communiquer au sein d'une même puce par rapport à une autre. Nous avons assisté à la croissance de puces à très faible consommation d'énergie grâce à l'intégration de ces accélérateurs dans les processeurs eux-mêmes.
Les accélérateurs ne sont cependant pas parfaits. Au fur et à mesure que nous en ajoutons de nouvelles dans nos conceptions, les puces deviennent moins flexibles et commencent à sacrifier les performances globales au profit de performances optimales pour certaines charges de travail. À un moment donné, la puce entière devient simplement une collection d'accélérateurs et ce n'est plus un processeur utile. Le compromis entre performance spécialisée et performance générale est toujours en train d'être peaufiné. Cette déconnexion entre le matériel généralisé et des charges de travail spécifiques est connue sous le nom de écart de spécialisation.
Certains pensent que nous sommes peut-être au sommet d'une bulle GPU / Machine Learning, mais nous pouvons probablement nous attendre à ce que davantage de calculs soient transférés à des accélérateurs spécialisés. Alors que le cloud et l'IA continuent à se développer, les GPU semblent être notre meilleure solution à ce jour pour atteindre les énormes quantités de calcul nécessaires.
La mémoire est un autre domaine dans lequel les concepteurs recherchent plus de performances. Traditionnellement, lire et écrire des valeurs a été l’un des plus gros goulots d’étranglement des transformateurs. Bien que les caches rapides volumineux puissent vous aider, la lecture de la RAM ou de votre disque SSD peut prendre des dizaines de milliers de cycles d'horloge. Pour cette raison, les ingénieurs considèrent souvent que l'accès à la mémoire est plus coûteux que le calcul lui-même. Si votre processeur souhaite ajouter deux nombres, il doit d’abord calculer les adresses de la mémoire où les nombres sont stockés, déterminer le niveau de hiérarchie de la mémoire contenant les données, lire les données dans des registres, effectuer le calcul, calculer l’adresse du destination et réécrivez la valeur là où elle est nécessaire. Pour des instructions simples qui ne peuvent prendre qu'un cycle ou deux, ceci est extrêmement inefficace.
Une technique novatrice qui a fait l’objet de nombreuses recherches est une technique appelée Calcul proche de la mémoire. Plutôt que d'aller chercher de petits morceaux de données dans la mémoire pour les amener au processeur rapide aux fins de calcul, les chercheurs renversent cette idée. Ils tentent de créer de petits processeurs directement dans les contrôleurs de mémoire de votre RAM ou de votre SSD. En rapprochant les calculs de la mémoire, il est possible d'économiser énormément d'énergie et de temps, car les données n'ont pas besoin d'être transférées autant. Les unités de calcul ont un accès direct aux données dont elles ont besoin puisqu'elles se trouvent juste dans la mémoire. Cette idée en est encore à ses balbutiements, mais les résultats semblent prometteurs.
L'un des obstacles à surmonter avec l'informatique proche de la mémoire est la limitation des processus de fabrication. Comme indiqué dans la partie 3, le processus de fabrication du silicium est très complexe et implique des dizaines d'étapes. Ces processus sont généralement spécialisés pour produire soit des éléments logiques rapides, soit des éléments de stockage denses. Si vous tentiez de créer une puce de mémoire à l'aide d'un processus de fabrication optimisé pour le calcul, la densité de la puce serait extrêmement médiocre. Si vous tentiez de créer un processeur à l'aide d'un processus de fabrication de stockage, les performances et le timing seraient très médiocres.
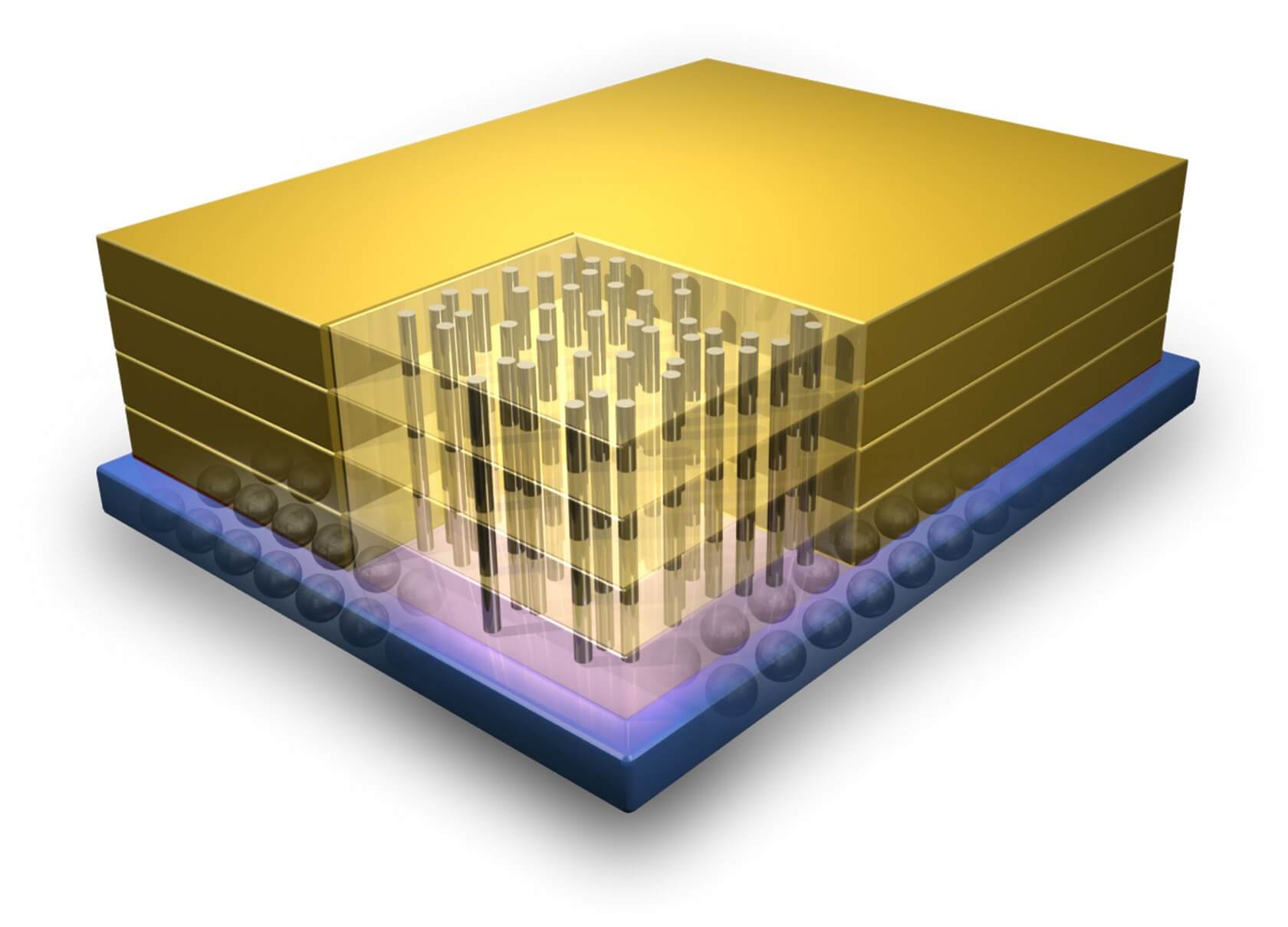
Un exemple d'intégration 3D montrant les connexions verticales entre les couches de transistors.
Une solution potentielle à ce problème est connue sous le nom de Intégration 3D. Les processeurs traditionnels ont une très large couche de transistors, mais celle-ci a ses limites. Comme son nom l'indique, l'intégration 3D consiste à empiler plusieurs couches de transistors les uns sur les autres pour améliorer la densité et réduire le temps de latence. Des colonnes verticales construites sur différents processus de fabrication peuvent ensuite être utilisées pour relier les couches. Cette idée a été proposée il y a longtemps, mais l'industrie a perdu tout intérêt en raison de difficultés majeures de mise en œuvre. Récemment, nous avons assisté à la technologie de stockage 3D NAND et à une résurgence de celle-ci en tant que domaine d'étude.
Outre les changements physiques et architecturaux, une des tendances qui affectera l’ensemble du secteur des semi-conducteurs est l’accent mis sur la sécurité. Jusqu'à récemment, la sécurité de nos processeurs était un peu une réflexion après coup. Ceci est similaire à la manière dont Internet, la messagerie électronique et de nombreux autres systèmes sur lesquels nous comptons ont été conçus sans aucune considération pour la sécurité. Tous les agents de sécurité présents ont été installés après coup pour que nous nous sentions plus en sécurité. Avec les processeurs, cela est revenu pour mordre les entreprises, en particulier Intel.
Les bugs Spectre et Meltdown sont peut-être l'exemple le plus célèbre de concepteurs qui ont ajouté des fonctionnalités qui accélèrent considérablement les processeurs, même s'ils ne comprennent pas parfaitement les risques de sécurité impliqués. La conception actuelle des processeurs insiste beaucoup plus sur la sécurité en tant qu'élément clé de la conception. La sécurité accrue nuit souvent aux performances, mais compte tenu des inconvénients de ces problèmes de sécurité majeurs, il est prudent d'affirmer qu'il vaut mieux se concentrer autant sur la sécurité que sur les performances.
Dans les parties précédentes de cette série, nous avons abordé des techniques telles que la synthèse de haut niveau, qui permettent aux concepteurs de spécifier d'abord leurs conceptions dans un langage de programmation de haut niveau, puis de faire appel à des algorithmes avancés pour déterminer la configuration matérielle optimale permettant d'exécuter cette fonction. Alors que les cycles de conception deviennent de plus en plus coûteux à chaque génération, les ingénieurs recherchent des moyens pour accélérer leur développement. Attendez-vous à ce que la tendance actuelle de la conception de matériel assisté par logiciel continue de croître.
Bien qu'il soit impossible de prédire l'avenir, les idées innovantes et les domaines de recherche dont nous avons parlé devraient servir de feuille de route pour ce que nous pouvons attendre des futurs processeurs. Ce que nous pouvons dire avec certitude, c'est que nous approchons de la fin des améliorations régulières du processus de fabrication. Pour continuer à augmenter les performances chaque génération, les concepteurs devront proposer des solutions encore plus complexes.
Nous espérons que cette série en quatre parties a suscité votre intérêt pour les domaines de la conception, de la fabrication, de la vérification et plus encore des processeurs. Il y a une quantité infinie de matériel à couvrir et chacun de ces articles pourrait compléter un cours universitaire supérieur si nous essayions de tout couvrir. J'espère que vous avez appris quelque chose de nouveau et que vous comprenez mieux la complexité des ordinateurs à tous les niveaux. Si vous avez des suggestions de sujets sur lesquels vous aimeriez que nous approfondissions, nous sommes toujours ouverts aux suggestions.
Crédit générique: Processeur d'ordinateur avec éclairage abstrait par Dan74