
Nous pensons tous que le processeur est le "cerveau" d'un ordinateur, mais qu'est-ce que cela signifie réellement? Que se passe-t-il à l'intérieur des milliards de transistors nécessaires au bon fonctionnement de votre ordinateur? Dans cette nouvelle mini série en quatre parties, nous allons nous concentrer sur la conception de matériel informatique, en abordant les aspects fondamentaux de ce qui fait fonctionner un ordinateur.
La série couvrira l'architecture informatique, la conception de circuits de processeur, VLSI (intégration à très grande échelle), la fabrication de puces et les tendances futures en informatique. Si vous avez toujours été intéressé par les détails du fonctionnement des processeurs à l'intérieur, restez dans les environs, car c'est ce que vous voulez savoir avant de commencer.
Nous allons commencer à un niveau très élevé de ce que fait un processeur et de la manière dont les blocs de construction se combinent dans une conception fonctionnelle. Cela inclut les cœurs de processeur, la hiérarchie de la mémoire, la prédiction de branche, etc. Premièrement, nous avons besoin d’une définition de base de ce que fait un processeur. L’explication la plus simple est qu’une CPU suit un ensemble d’instructions pour effectuer certaines opérations sur un ensemble d’entrées. Par exemple, il peut s’agir de lire une valeur dans la mémoire, puis de l’ajouter à une autre valeur et enfin de stocker le résultat en mémoire dans un emplacement différent. Cela pourrait aussi être quelque chose de plus complexe, comme de diviser deux nombres si le résultat du calcul précédent était supérieur à zéro.
Lorsque vous souhaitez exécuter un programme tel qu'un système d'exploitation ou un jeu, le programme lui-même est une série d'instructions à exécuter par la CPU. Ces instructions sont chargées à partir de la mémoire et sur un simple processeur, elles sont exécutées une par une jusqu'à la fin du programme. Alors que les développeurs de logiciels écrivent leurs programmes dans des langages de haut niveau tels que C ++ ou Python, par exemple, le processeur ne peut pas comprendre cela. Il ne comprend que les 1 et les 0, nous avons donc besoin d'un moyen de représenter le code dans ce format.
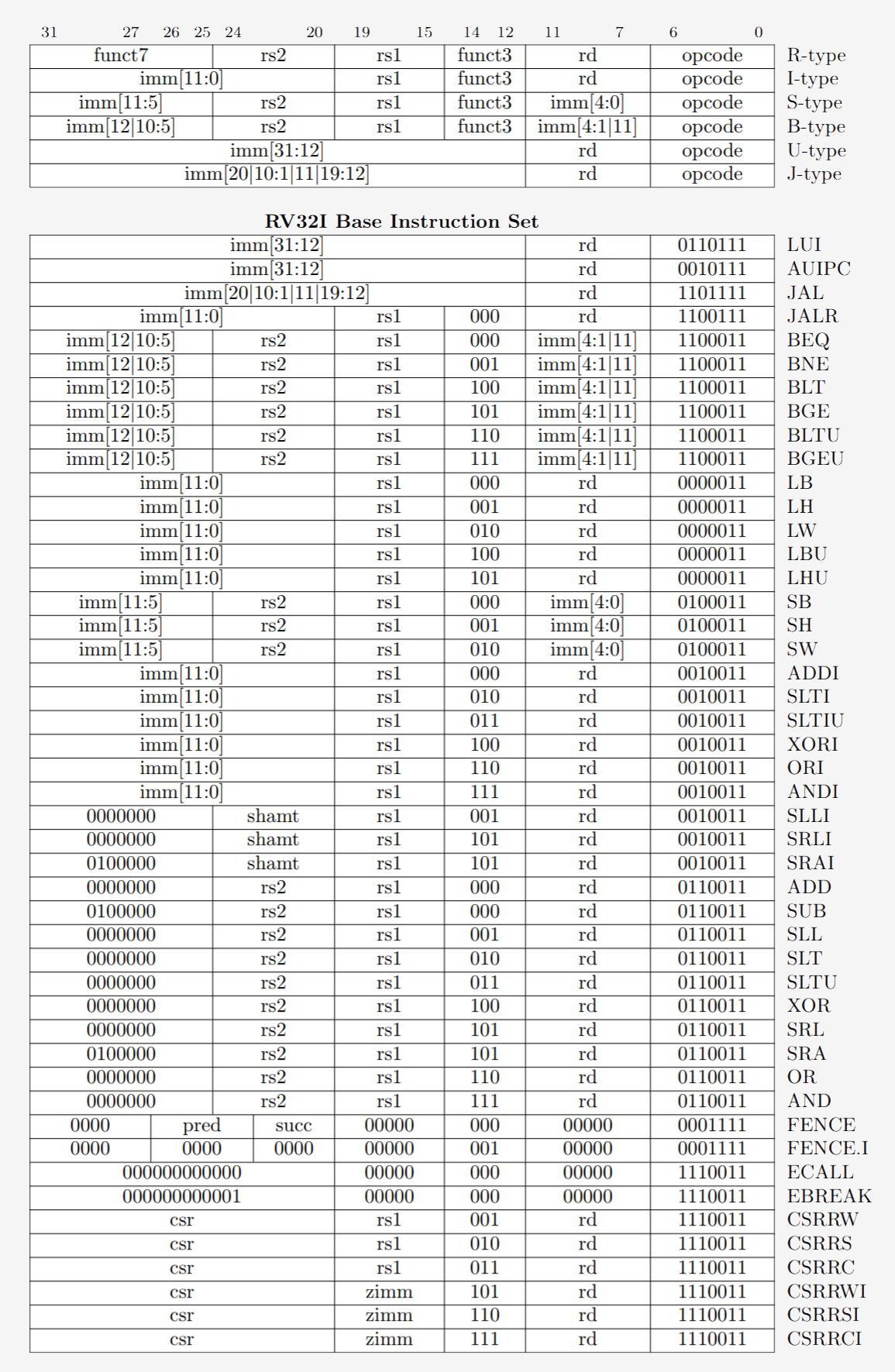
Les programmes sont compilés dans un ensemble d’instructions de bas niveau appelé langage d'assemblage dans le cadre d'une architecture ISA (Instruction Set Architecture). C'est l'ensemble d'instructions que le CPU est construit pour comprendre et exécuter. Les normes ISA les plus courantes sont x86, MIPS, ARM, RISC-V et PowerPC. Tout comme la syntaxe pour écrire une fonction en C ++ est différente d'une fonction qui fait la même chose en Python, chaque ISA a une syntaxe différente.
Ces ISA peuvent être divisées en deux catégories principales: les longueurs fixes et les longueurs variables. Le RISC-V ISA utilise des instructions de longueur fixe, ce qui signifie qu’un certain nombre de bits prédéfini dans chaque instruction détermine le type d’instruction considéré. Ceci diffère de x86 qui utilise des instructions de longueur variable. En x86, les instructions peuvent être codées de différentes manières et avec différents nombres de bits pour différentes parties. En raison de cette complexité, le décodeur d'instructions dans les processeurs x86 est généralement la partie la plus complexe de la conception.
Les instructions de longueur fixe permettent un décodage plus facile en raison de leur structure régulière, mais limitent le nombre d'instructions totales qu'une ISA peut prendre en charge. Bien que les versions courantes de l'architecture RISC-V comportent environ 100 instructions et soient à source ouverte, x86 est propriétaire et personne ne sait vraiment combien il y a d'instructions. Les gens croient généralement qu'il existe quelques milliers d'instructions x86, mais le nombre exact n'est pas public. Malgré les différences entre les normes ISA, elles ont toutes essentiellement la même fonctionnalité principale.
Nous sommes maintenant prêts à allumer notre ordinateur et à lancer des tâches. L’exécution d’une instruction comporte en réalité plusieurs éléments de base qui se décomposent en plusieurs étapes d’un processeur.
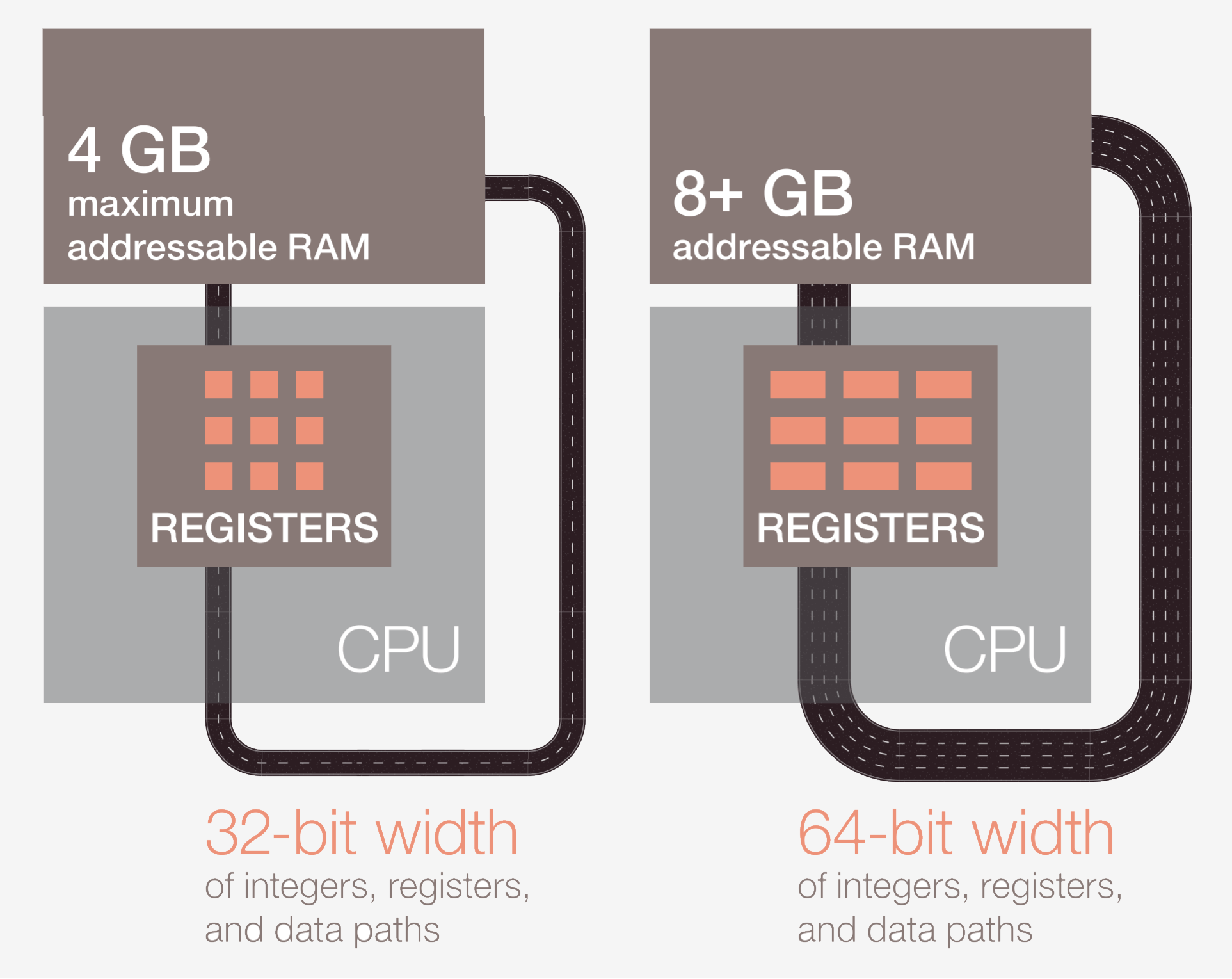
La première étape consiste à extraire l'instruction de la mémoire dans la CPU pour commencer l'exécution. Dans la deuxième étape, l'instruction est décodée afin que la CPU puisse déterminer de quel type d'instruction il s'agit. Il en existe de nombreux types, notamment les instructions arithmétiques, les instructions de branche et les instructions de mémoire. Une fois que la CPU sait quel type d’instruction elle est en train d’exécuter, les opérandes de l’instruction sont collectés dans la mémoire ou dans des registres internes de la CPU. Si vous souhaitez ajouter le nombre A au nombre B, vous ne pouvez pas l'ajouter tant que vous ne connaissez pas les valeurs de A et B. La plupart des processeurs modernes sont à 64 bits, ce qui signifie que la taille de chaque valeur de données est de 64 bits.
Une fois que la CPU a obtenu les opérandes de l'instruction, elle passe à l'étape d'exécution où l'opération est effectuée sur l'entrée. Il peut s’agir d’ajouter des nombres, d’effectuer une manipulation logique des nombres ou de simplement passer les chiffres sans les modifier. Une fois le résultat calculé, il peut être nécessaire d'accéder à la mémoire pour stocker le résultat ou au processeur de ne conserver que la valeur dans l'un de ses registres internes. Une fois le résultat enregistré, la CPU met à jour l’état de divers éléments et passe à l’instruction suivante.
Cette description est, bien sûr, une énorme simplification et la plupart des processeurs modernes diviseront ces quelques étapes en 20 étapes ou plus pour améliorer l'efficacité. Cela signifie que, bien que le processeur commence et termine plusieurs instructions à chaque cycle, il peut s'écouler 20 cycles ou plus pour qu'une instruction soit complète du début à la fin. Ce modèle est généralement appelé pipeline, car il faut un certain temps pour le remplir et que le liquide le traverse complètement, mais une fois rempli, le résultat obtenu est constant.
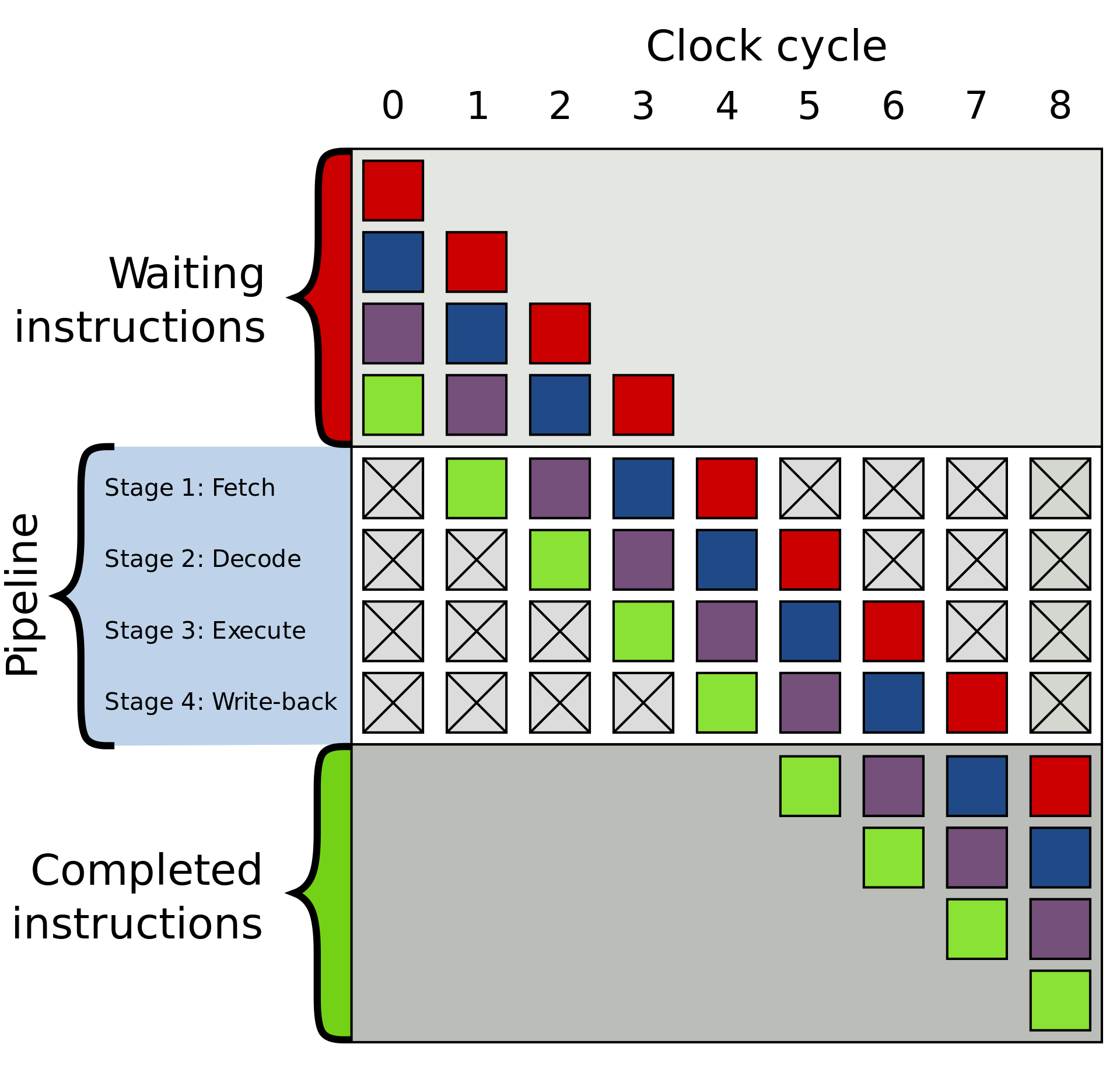
Le cycle complet d'une instruction est un processus très étroitement chorégraphié, mais toutes les instructions ne peuvent pas se terminer en même temps. Par exemple, l'ajout est très rapide, tandis que la division ou le chargement en mémoire peut prendre des centaines de cycles. Plutôt que de bloquer tout le processeur alors qu'une instruction lente est terminée, la plupart des processeurs modernes s'exécutent dans le désordre. Cela signifie qu'ils détermineront quelle instruction serait la plus utile à exécuter à un moment donné et mettra en tampon d'autres instructions qui ne sont pas prêtes. Si l'instruction en cours n'est pas encore prête, le processeur peut avancer dans le code pour voir si un autre élément est prêt.
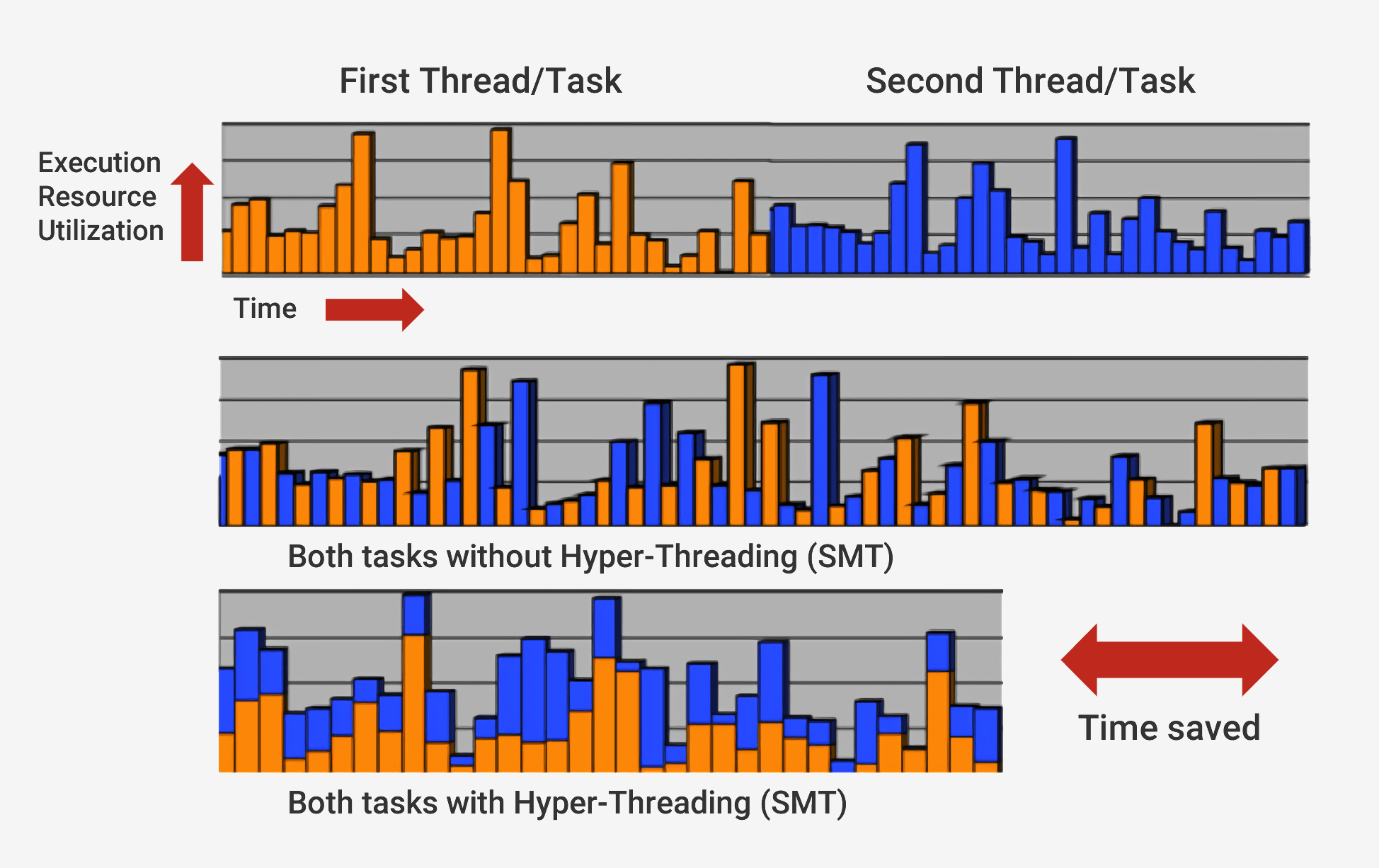
En plus de l'exécution dans le désordre, les processeurs modernes utilisent ce qu'on appelle un architecture superscalaire. Cela signifie qu’à tout moment, le processeur exécute plusieurs instructions à la fois à chaque étape de la pipe. Il se peut également que des centaines d’autres attendent pour commencer leur exécution. Afin de pouvoir exécuter plusieurs instructions à la fois, les processeurs disposeront de plusieurs copies de chaque étape du pipeline. Si un processeur voit que deux instructions sont prêtes à être exécutées et qu'il n'y a pas de dépendance entre elles plutôt que d'attendre qu'elles se terminent séparément, il les exécutera toutes les deux en même temps. Une implémentation courante de cela s'appelle le multithreading simultané (SMT), également appelé Hyper-Threading. Les processeurs Intel et AMD prennent actuellement en charge le SMT bidirectionnel, tandis qu'IBM a développé des puces prenant en charge le SMT jusqu'à huit voies.
Pour accomplir cette exécution soigneusement chorégraphiée, un processeur comporte de nombreux éléments supplémentaires en plus du noyau de base. Il existe des centaines de modules individuels dans un processeur qui servent chacun un objectif spécifique, mais nous allons simplement passer en revue les bases. Les deux plus gros et les plus bénéfiques sont les prédicteurs de caches et de branches. Les structures supplémentaires que nous ne couvrirons pas incluent des choses telles que les tampons de réorganisation, les tables de pseudonymes de registre et les stations de réservation.
Les caches peuvent souvent être déroutants dans la mesure où ils stockent des données telles que la RAM ou un SSD. Cependant, ce qui distingue les caches, c'est leur temps de latence et leur vitesse d'accès. Même si la RAM est extrêmement rapide, elle est beaucoup trop lente pour un processeur. Cela peut prendre des centaines de cycles à la RAM pour répondre avec des données et le processeur serait bloqué avec rien à faire. Si les données ne sont pas dans la RAM, plusieurs dizaines de milliers de cycles sont nécessaires pour accéder aux données d'un disque SSD. Sans caches, nos processeurs seraient bloqués.
Les processeurs ont généralement trois niveaux de cache qui forment ce qu’on appelle un hiérarchie de la mémoire. Le cache L1 est le plus petit et le plus rapide, le L2 est au milieu et L3 est le plus grand et le plus lent des caches. Au-dessus des caches de la hiérarchie se trouvent de petits registres qui stockent une seule valeur de données lors du calcul. Ces registres sont les périphériques de stockage les plus rapides de votre système par ordre de grandeur. Lorsqu'un compilateur transforme un programme de haut niveau en langage assembleur, il déterminera le meilleur moyen d'utiliser ces registres.
Lorsque la CPU demande des données de la mémoire, elle vérifie d'abord si ces données sont déjà stockées dans le cache L1. Si tel est le cas, les données peuvent être rapidement consultées en quelques cycles seulement. Si tel n'est pas le cas, la CPU vérifie la couche L2 et recherche ensuite le cache L3. Les caches sont mis en œuvre de manière à être généralement transparents pour le noyau. Le noyau demandera simplement des données à une adresse de mémoire spécifiée et à n’importe quel niveau de la hiérarchie auquel elle répondra. Au fur et à mesure que nous passons aux étapes suivantes de la hiérarchie de la mémoire, la taille et la latence augmentent généralement d'un ordre de grandeur à l'autre. À la fin, si le processeur ne peut pas trouver les données qu'il recherche dans l'un des caches, alors seulement il ira dans la mémoire principale (RAM).
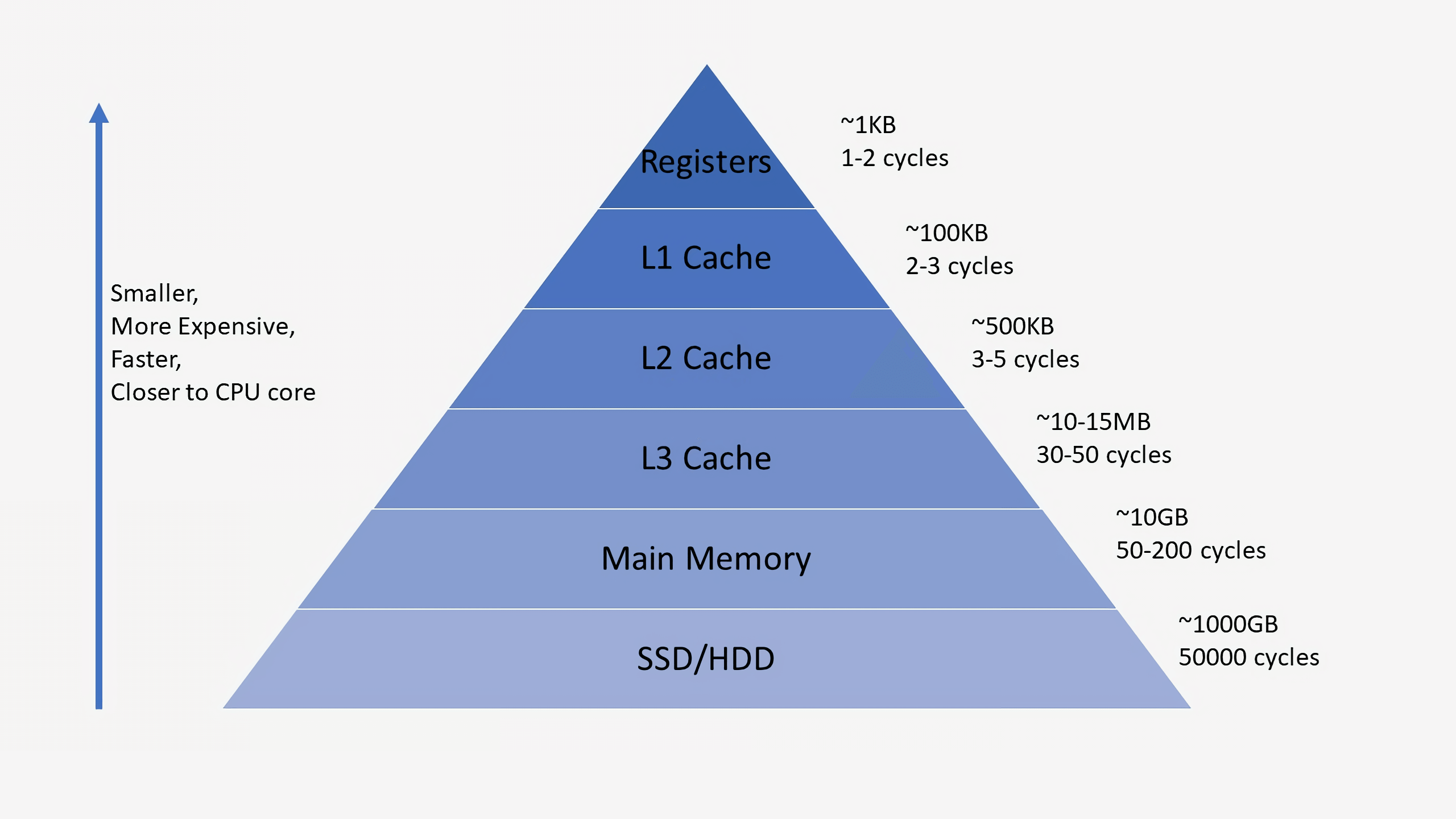
Sur un processeur typique, chaque cœur aura deux caches L1: un pour les données et un pour les instructions. Les caches L1 ont généralement un total d'environ 100 kilo-octets et leur taille peut varier en fonction de la puce et de la génération. Il existe également généralement un cache N2 pour chaque cœur, bien qu'il puisse être partagé entre deux cœurs dans certaines architectures. Les caches L2 sont généralement de quelques centaines de kilo-octets. Enfin, il existe un seul cache N3 qui est partagé entre tous les cœurs et est de l’ordre de quelques dizaines de mégaoctets.
Lorsqu'un processeur exécute du code, les instructions et les valeurs de données qu'il utilise le plus souvent sont mises en cache. Cela accélère considérablement l'exécution, car le processeur n'a pas besoin d'aller constamment dans la mémoire principale pour les données dont il a besoin. Nous parlerons davantage de la manière dont ces systèmes de mémoire sont réellement mis en œuvre dans les deuxième et troisième parties de cette série.
Outre les caches, l’un des autres composants essentiels d’un processeur moderne est une prédicteur de branche. Les instructions de branchement sont similaires aux instructions "if" pour un processeur. Un ensemble d'instructions sera exécuté si la condition est vraie et un autre, si la condition est fausse. Par exemple, vous souhaiterez peut-être comparer deux nombres et, s'ils sont égaux, exécuter une fonction et, s'ils sont différents, exécuter une autre fonction. Ces instructions de branche sont extrêmement courantes et peuvent représenter environ 20% de toutes les instructions d'un programme.
En apparence, ces instructions de branche ne semblent pas être un problème, mais elles peuvent en réalité être très difficiles à obtenir pour un processeur. Étant donné qu’à un moment donné, la CPU peut exécuter dix ou vingt instructions à la fois, il est très important de savoir lequel instructions à exécuter. Il faut parfois 5 cycles pour déterminer si l’instruction en cours est une branche et 10 autres cycles pour déterminer si la condition est vraie. Pendant ce temps, le processeur peut avoir commencé à exécuter des dizaines d'instructions supplémentaires sans même savoir si celles-ci étaient correctes à exécuter.
Pour résoudre ce problème, tous les processeurs modernes haute performance utilisent une technique appelée spéculation. Cela signifie que le processeur va garder une trace des instructions de branche et deviner si la branche sera prise ou non. Si la prédiction est correcte, le processeur a déjà commencé à exécuter les instructions suivantes, ce qui procure un gain de performance. Si la prédiction est incorrecte, le processeur arrête l'exécution, supprime toutes les instructions incorrectes qu'il a commencé à exécuter et recommence à partir du point correct.
Ces prédicteurs de branche sont parmi les plus anciennes formes d’apprentissage automatique, car le prédicteur apprend le comportement des branches au fur et à mesure. S'il prédit de manière erronée trop de fois, il commencera à apprendre le comportement correct. Des décennies de recherche sur les techniques de prévision de branche ont permis d'obtenir des précisions supérieures à 90% sur les processeurs modernes.
Alors que la spéculation offre d’immenses gains de performances puisque le processeur peut exécuter des instructions prêtes au lieu d’attendre les commandes surchargées, elle expose également des vulnérabilités de sécurité. La célèbre attaque Spectre exploite des bugs de prédiction de branche et de spéculation. L’attaquant utiliserait un code spécialement conçu pour amener le processeur à exécuter de façon spéculative un code susceptible de libérer des valeurs de mémoire. Certains aspects de la spéculation ont dû être repensés pour éviter toute fuite de données, ce qui a entraîné une légère baisse des performances.
L'architecture utilisée dans les processeurs modernes a parcouru un long chemin au cours des dernières décennies. Les innovations et la conception intelligente ont entraîné plus de performances et une meilleure utilisation du matériel sous-jacent. Les fabricants de processeurs sont cependant très discrets sur les technologies de leurs processeurs. Il est donc impossible de savoir exactement ce qui se passe à l'intérieur. Cela dit, les principes de base du fonctionnement des ordinateurs sont normalisés sur tous les processeurs. Intel peut ajouter sa sauce secrète pour augmenter les taux d’accès au cache ou AMD peut ajouter un prédicteur de branche avancé, mais ils accomplissent tous les deux la même tâche.
Ce premier aperçu et aperçu couvrait la plupart des bases sur le fonctionnement des processeurs. Dans la partie suivante, nous verrons comment sont conçus les composants qui entrent dans la CPU: couvrent les portes logiques, la synchronisation, la gestion de l’alimentation, les schémas de circuit, etc. Restez à l'écoute.
Lectures recommandées:
Crédits Masthead: Un circuit électronique de près par Raimudas