
Les premières cartes graphiques 3D sont apparues il y a 25 ans et depuis lors, leur puissance et leur complexité ont augmenté à une échelle supérieure à toute autre micropuce trouvée dans un PC. À l'époque, ces processeurs contenaient environ 1 million de transistors, avaient une taille inférieure à 100 mm2 et consommaient seulement une poignée de watts d'énergie électrique.
Avance rapide aujourd'hui, et une carte graphique typique pourrait avoir 14 milliards de transistors, dans une puce de 500 mm2 de taille et consomment plus de 200 W de puissance. Les capacités de ces géants seront infiniment plus grandes que leurs anciens prédécesseurs, mais ont-ils amélioré leur efficacité avec tous ces minuscules commutateurs et cette énergie?
Un conte de deux nombres
Dans cet article, nous allons voir dans quelle mesure les concepteurs de GPU ont utilisé l'augmentation de la taille des matrices et de la consommation d'énergie pour nous donner toujours plus de puissance de traitement. Avant de plonger, vous pouvez d'abord réviser les composants d'une carte graphique ou vous promener dans l'histoire du processeur graphique moderne. Avec ces informations, vous aurez une excellente base pour suivre cette fonctionnalité.
Pour comprendre comment l'efficacité d'une conception de GPU a changé, voire pas du tout, au fil des ans, nous avons utilisé l'excellente base de données de TechPowerUp, en prenant un échantillon de processeurs des 14 dernières années. Nous avons choisi ce délai car il marque le début du moment où les GPU avaient une structure de shader unifiée.
Plutôt que d'avoir des circuits séparés dans la puce pour gérer les triangles et les pixels, les shaders unifiés sont des unités logiques arithmétiques qui sont conçues pour traiter toutes les mathématiques nécessaires à tout calcul impliqué dans les graphiques 3D. Cela nous permet d'utiliser une mesure de performance relative, de manière cohérente sur les différents GPU: opérations à virgule flottante par seconde (FLOPS, pour faire court).
Les fournisseurs de matériel sont souvent désireux d'indiquer des chiffres FLOPS comme mesure de la capacité de traitement maximale du GPU et bien que ce ne soit absolument pas le seul aspect derrière la vitesse d'un GPU, FLOPS nous donne un nombre avec lequel nous pouvons travailler.
Il en va de même pour la taille de la puce, qui est une mesure de la surface de la puce de traitement. Cependant, vous pouvez avoir deux puces de même taille, mais dont le nombre de transistors est très différent.
Par exemple, le processeur G71 de Nvidia (pensez à la GeForce 7900 GT) de 2005 mesure 196 mm2 de taille et contient 278 millions de transistors; leur TU117 sorti au début de l'année dernière (GeForce GTX 1650), est à seulement 4 mm2 plus grand mais a 4,7 milliards de petits commutateurs.
Un graphique des principaux GPU de Nvidia montrant les changements de densité de transistor au fil des ans
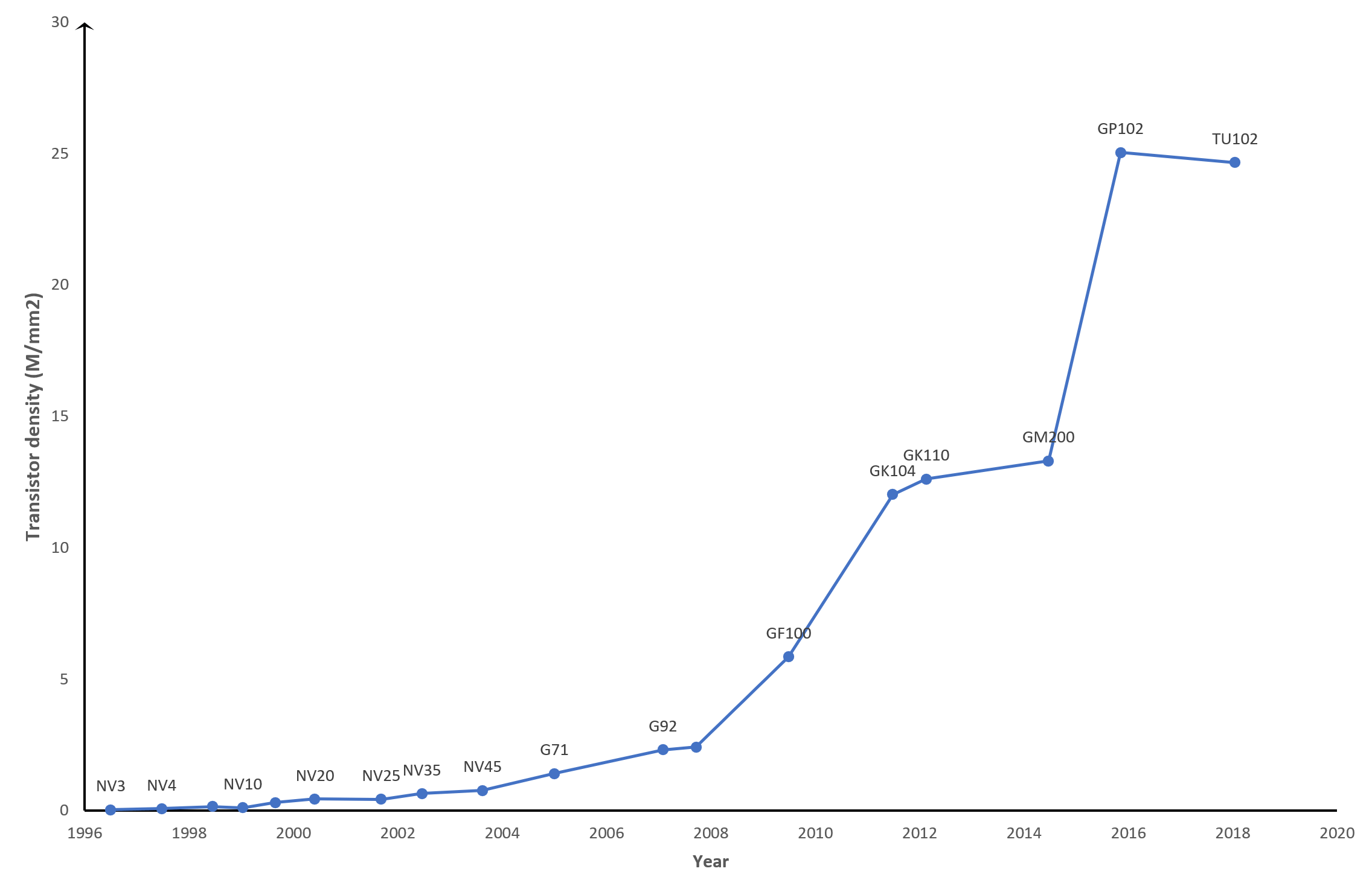
Naturellement, cela doit signifier que les nouveaux transistors GPU sont beaucoup plus petits que les puces plus anciennes, et c'est très bien le cas. Le soi-disant nœud de processus – l'échelle de conception globale du processus de fabrication utilisé pour fabriquer le processeur – utilisé par les fournisseurs de matériel a changé au fil des ans, devenant de plus en plus petit. Nous allons donc analyser l'efficacité du point de vue de la densité de filière, qui est une mesure du nombre de millions de transistors par mm2 de la surface de la puce.
La mesure la plus controversée que nous utiliserons est peut-être le chiffre de la consommation d'énergie du GPU. Nous ne doutons pas que de nombreux lecteurs n'aimeront pas cela, car nous utilisons la valeur de puissance de conception thermique (TDP) indiquée par le vendeur. Il s'agit en fait d'une mesure (ou du moins, c'est censé l'être) de la quantité de chaleur émise par l'ensemble de la carte graphique dans une situation moyenne, mais à charge élevée.
Avec les puces en silicium, l'énergie qu'elles consomment est principalement transformée en chaleur, mais ce n'est pas la raison pour laquelle l'utilisation du TDP est un problème. C'est que différents fournisseurs indiquent ce nombre dans des conditions différentes, et ce n'est pas nécessairement la consommation d'énergie tout en produisant des FLOPS de pointe. C'est également la valeur de puissance de toute la carte graphique, y compris la mémoire intégrée, bien que la majeure partie soit le GPU lui-même.
Il est possible de mesurer directement la consommation électrique d'une carte graphique. Par exemple, TechPowerUp le fait pour leurs examens de GPU, et quand ils ont testé un GeForce RTX 2080 Super, avec un TDP déclaré par le fournisseur de 250 W, ils ont trouvé qu'il était en moyenne de 243 W mais a culminé à 275 W, lors de leurs tests.
Mais nous sommes restés avec l'utilisation de TDP pour des raisons de simplicité et nous avons été quelque peu prudents en faisant des jugements uniquement basés sur les performances de traitement par rapport à la puissance de conception thermique.
Nous allons comparer directement 2 métriques: GFLOPS et densité de matrice unitaire. Un GFLOPS équivaut à 1 000 millions d'opérations en virgule flottante par seconde, et nous avons affaire à la valeur des calculs FP32, effectués exclusivement par les shaders unifiés. La comparaison prendra la forme d'un graphique comme celui-ci:
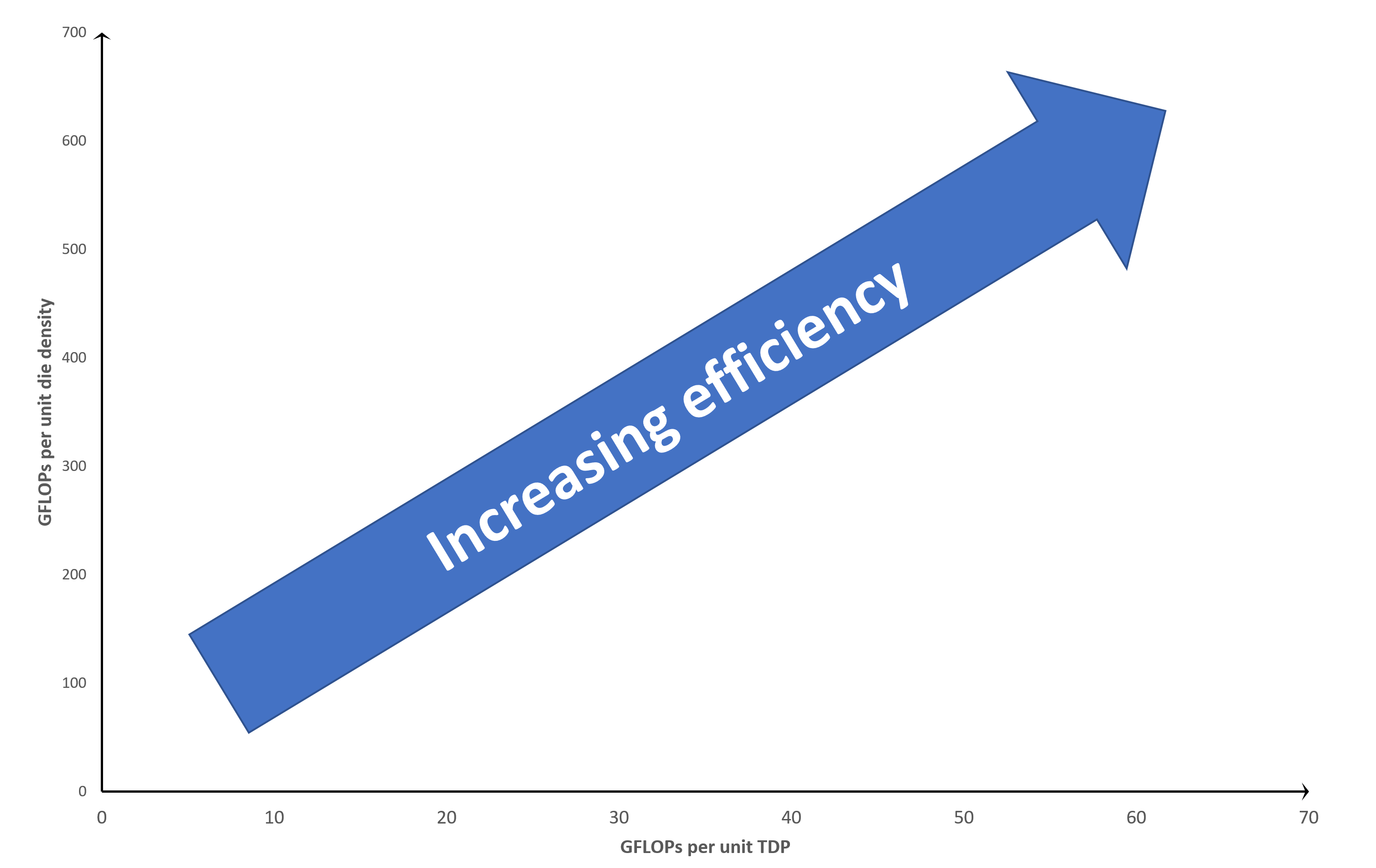
le X-l'axe trace GFLOPS par unité TDP, vous voulez donc que ce soit aussi élevé que possible: plus la position est basse avec l'axe, moins la puce est économe en énergie. Il en va de même pour le y-axis car cela trace GFLOPS par unité de densité de matrice. Plus vous avez emballé de transistors dans un mm carré, plus vous vous attendez à des performances. Ainsi, l'efficacité globale du traitement GPU (tenant compte du nombre de transistors, de la taille des matrices et du TDP) augmente à mesure que vous vous dirigez vers le coin supérieur droit du graphique.
Tous les points de données situés en haut à gauche indiquent "que ce GPU obtient de bonnes performances de la conception de la puce, mais au prix d'une consommation d'énergie relativement importante". Aller vers le bas à droite et c'est "bien utiliser l'énergie efficacement, mais la conception de la matrice ne génère pas beaucoup de performances."
En bref, nous définissons l'efficacité du traitement comme combien le GPU fait pour le package et la puissance qu'il a.
Efficacité du GPU: TDP vs unité de densité de matrice
Sans plus tarder, passons aux résultats:
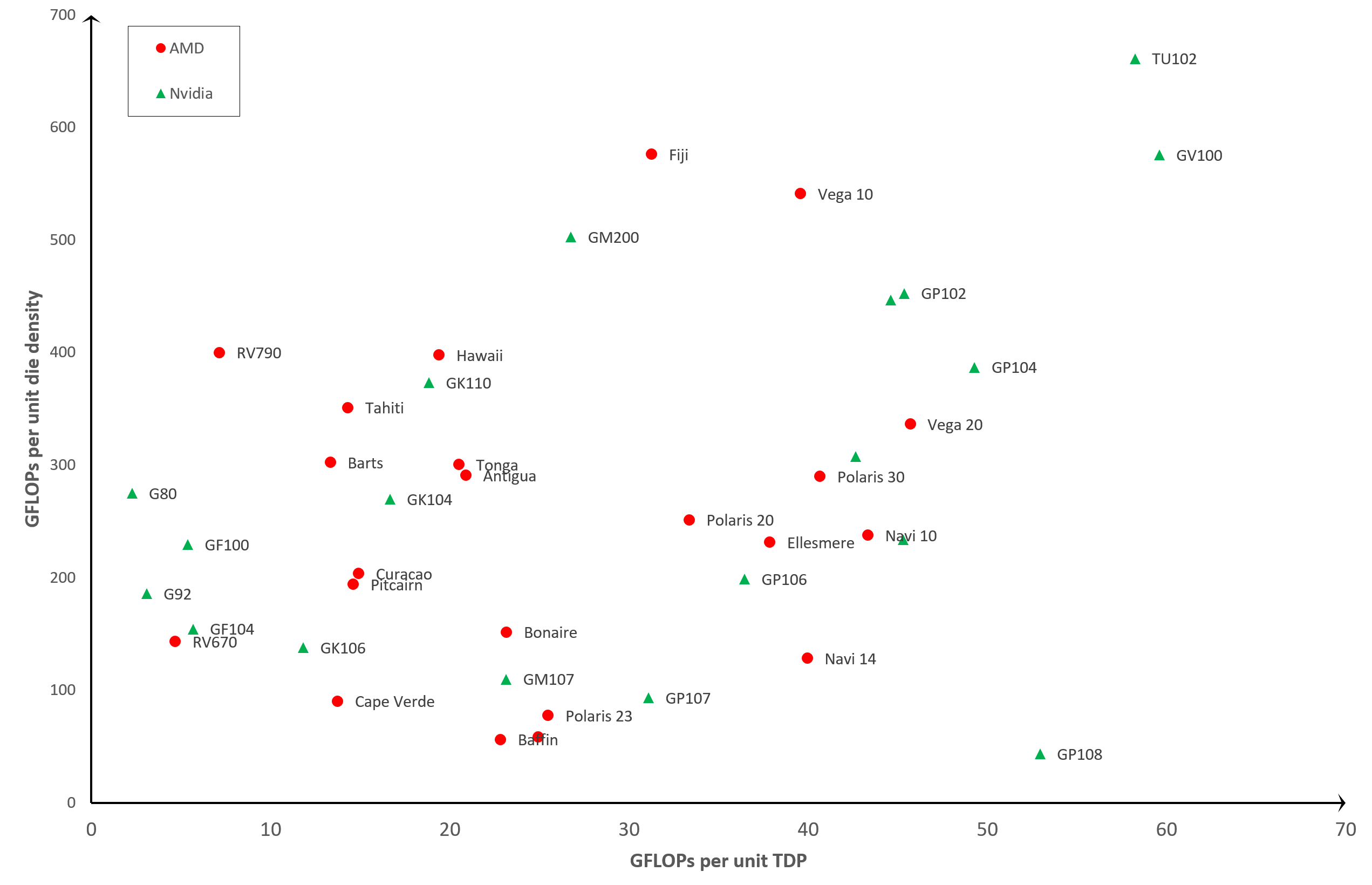
À première vue, les résultats semblent plutôt dispersés, mais nous pouvons voir un schéma de base: les anciens GPU, tels que le G80 ou RV670, sont beaucoup moins efficaces par rapport aux modèles plus récents, tels que le Vega 20 ou le GP102. C'est ce que vous attendez! Après tout, ce serait une équipe d'ingénieurs en électronique assez pauvre qui ferait tout son possible pour concevoir et publier en permanence de nouveaux produits moins efficaces à chaque version.
Mais il y a des points de données intéressants. Les premiers sont les TU102 et GV100. Les deux sont fabriqués par Nvidia et peuvent être trouvés dans des graphiques tels que le GeForce RTX 2080 Ti et Titan V, respectivement.

On pourrait dire qu'aucun des GPU n'a été conçu pour le marché grand public, en particulier le GV100, car ils sont vraiment destinés aux postes de travail ou aux serveurs de calcul. Donc, bien qu'ils semblent être les plus efficaces du lot, c'est ce que vous attendez des processeurs conçus pour des marchés spécialisés, qui coûtent beaucoup plus cher que les processeurs standard.
Un autre GPU qui ressort, et un peu comme un pouce endolori, est le GP108 – c'est un autre des puces de Nvidia et se trouve principalement dans la GeForce GT 1030. Ce produit bas de gamme, sorti en 2017, a un très petit processeur seulement 74 mm2 en taille avec un TDP de seulement 30 W.Cependant, ses performances relatives en virgule flottante ne sont en fait pas meilleures que le premier GPU unifié de Nvidia, le G80, de 2006.

En face du GP108 se trouve la puce Fuji d'AMD qui alimentait sa série Radeon R9 Fury. Cette conception ne semble pas être trop économe en énergie, d'autant plus que l'utilisation de la mémoire à large bande passante (HBM) était censée aider à cet égard. La conception fidjienne a été plutôt chaude, ce qui rend les processeurs à semi-conducteurs moins économes en énergie en raison d'une augmentation des fuites. C'est là que l'énergie électrique se perd dans le boîtier et l'environnement, plutôt que d'être contrainte dans les circuits. Toutes les puces fuient, mais le taux de perte augmente avec la température.
Navi 10 est peut-être le point de données le plus intéressant: il s'agit de la conception de GPU la plus récente d'AMD et est fabriqué par TSMC, en utilisant leur nœud de processus N7, actuellement la plus petite échelle utilisée. Cependant, la puce Vega 20 est fabriquée sur le même nœud, mais elle semble être plus efficace, malgré son ancienne conception. Alors, que se passe-t-il ici?

Le Vega 20 (AMD ne l'utilisait que sur la seule carte graphique grand public – la Radeon VII) était le dernier processeur fabriqué par AMD à utiliser son architecture GCN (Graphics Core Next). Il intègre un grand nombre de cœurs de shaders unifiés dans une configuration qui se concentre fortement sur le débit FP32. Cependant, la programmation de l'appareil pour atteindre ces performances n'a pas été facile à faire et il manquait de flexibilité.
Navi 10 utilise leur dernière architecture, RDNA, qui résout ce problème, mais au détriment du débit FP32. Cependant, il s'agit d'une nouvelle configuration et fabriquée sur un nœud de processus relativement récent, nous pouvons donc nous attendre à voir des améliorations d'efficacité alors que TSMC développe son nœud de processus et AMD met à jour l'architecture.
Si nous ignorons les valeurs aberrantes, les GPU les plus efficaces de notre graphique sont les GP102 et GP104. Ceux-ci utilisent l'architecture Pascal de Nvidia et peuvent être trouvés dans des cartes graphiques telles que la GeForce GTX 1080 Ti et GTX 1060, respectivement. Celui à côté du GP102, mais non étiqueté pour des raisons de clarté, est le TU104 qui utilise le dernier design Turing de Nvidia, et peut être trouvé dans une série de modèles GeForce RTX: 2060, 2070 Super, 2080, 2080 Super, pour ne nommer que quelques.

Ils sont également fabriqués par TSMC mais en utilisant un nœud de processus spécialement conçu pour les produits Nvidia, appelé 12FFN, qui est lui-même une version raffinée du nœud 16FF.
Les améliorations se concentrent sur l'augmentation de la densité des matrices, tout en réduisant les fuites, ce qui expliquerait en partie pourquoi les GPU de Nvidia sont apparemment les plus efficaces.
Efficacité du GPU: TDP vs zone de matrice d'unité
Nous pouvons réduire l'impact du nœud de processus à partir de l'analyse, en remplaçant la métrique de densité de matrice par une zone de matrice unique. Cela nous donne une image très différente …
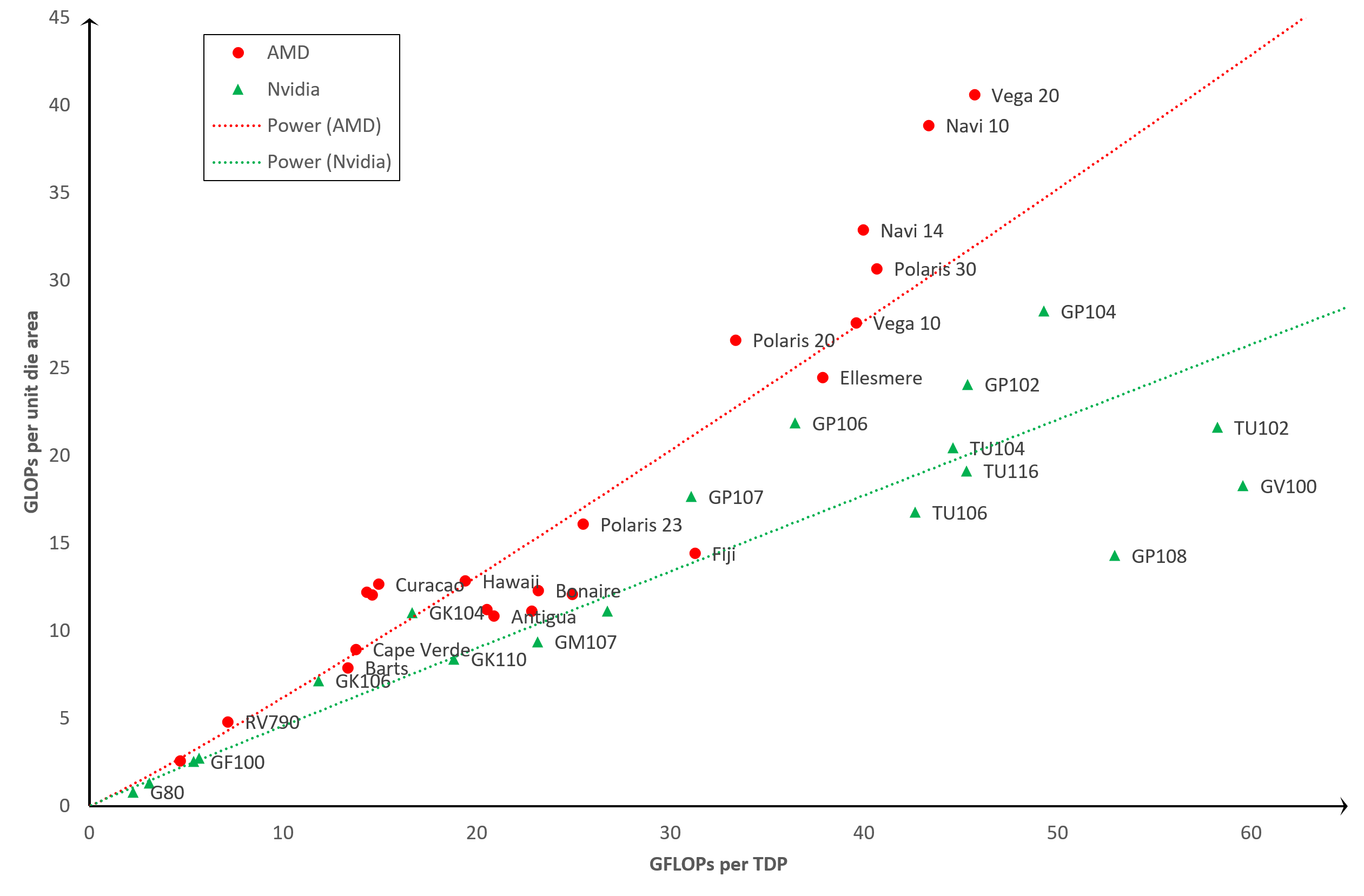
L'efficacité augmente dans la même direction dans ce graphique, mais nous pouvons maintenant voir que certaines positions clés ont changé. Le TU102 et le GV100 ont chuté tout en bas, tandis que le Navi 10 et le Vega 20 ont grimpé dans le graphique. En effet, les deux anciens processeurs sont d'énormes puces (754 mm2 et 815 mm2), alors que les deux derniers d'AMD sont beaucoup plus petits (251 mm2 et 331 mm2).
Si nous concentrons le graphique pour qu'il affiche uniquement les GPU les plus récents, et les différences deviennent encore plus prononcées:
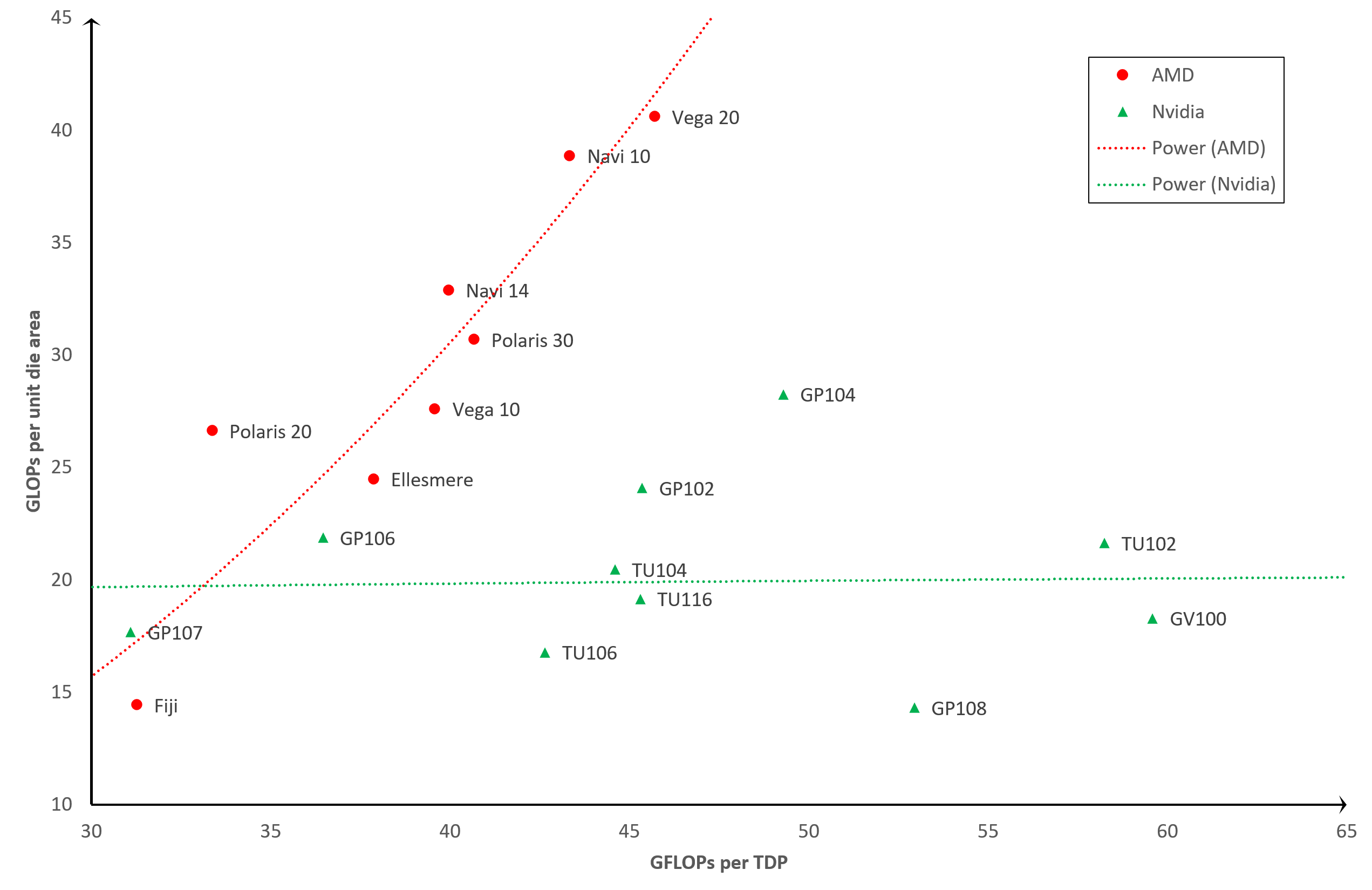
Cette opinion suggère fortement que AMD s'est moins concentré sur l'efficacité énergétique que sur l'efficacité de la taille de la puce.
En d'autres termes, ils ont voulu obtenir plus de puces GPU par tranche fabriquée. Nvidia, d'autre part, semble avoir adopté l'approche où ils conçoivent leurs puces de plus en plus grandes (et donc chaque tranche fournit moins de matrices), mais ils utilisent mieux l'énergie électrique.
AMD et Nvidia continueront-ils ainsi avec leurs prochains GPU? Eh bien, le premier a déjà déclaré qu'il se concentrait sur l'amélioration du rapport performances par watt dans RDNA 2.0 de 50%, nous devrions donc voir leurs futurs GPU se situer plus à droite sur notre graphique ci-dessus. Mais qu'en est-il de Nvidia?
Malheureusement, ils sont connus pour rester très informés sur les développements futurs, mais nous savons que leurs prochains processeurs seront fabriqués par TSMC et Samsung sur un nœud de processus similaire à celui utilisé pour Navi. Il y a eu certaines affirmations selon lesquelles nous verrons une forte réduction de puissance, mais aussi une forte augmentation du nombre de shaders unifiés, donc nous verrons peut-être une position similaire sur le graphique pour Nvidia.
Alors, comment les GPU sont-ils devenus plus efficaces?
Ce qui précède est assez concluant: au fil des ans, AMD et Nvidia ont augmenté les performances de traitement par unité de densité de matrice et par unité de TDP. Dans certains cas, l'augmentation a été étonnante …
Prenez les processeurs G92 et TU102 de Nvidia. Le premier a alimenté des GeForce 8800 GT et 9800 GTX, et contient 754 millions de transistors dans une puce de 324 mm2 dans la zone. Lorsqu'il est apparu en octobre 2007, il a été bien accueilli pour ses performances et ses besoins en énergie.
Onze ans plus tard, Nvidia nous proposait le TU102 sous la forme du GeForce RTX 2080 Ti, avec près de 19 milliards de transistors sur une surface de 754 mm2 – c'est 25 fois plus de composants microscopiques dans une surface qui n'est que 2,3 fois plus grande.
Rien de tout cela ne serait possible sans le travail accompli par TSMC pour développer constamment sa technologie de fabrication: le G92 de la 8800 GT a été construit sur un nœud de processus à 65 nm, tandis que le dernier TU102 est leur échelle spéciale 12FFN. Les noms des méthodes de production ne nous disent pas vraiment le sens de la différence entre les deux, mais les nombres GPU le font. L'actuel a une densité de filières de 24,67 millions de transistors par mm2, par rapport à la valeur de l'ancien de 2,33 millions d'euros.
Une multiplication par dix de l'emballage des composants est la principale raison de l'énorme différence d'efficacité des deux GPU. Les unités logiques plus petites nécessitent moins d'énergie pour fonctionner et les voies plus courtes les reliant signifient que les données prennent moins de temps à voyager. Avec des améliorations dans la fabrication de puces en silicium (réduction des défauts et meilleure isolation), cela permet de fonctionner à des vitesses d'horloge plus élevées pour la même puissance requise ou de consommer moins d'énergie pour la même fréquence d'horloge.

En parlant d'horloges, c'est un autre facteur à considérer. Comparons le RV670, de novembre 2007 dans la Radeon HD 3870, au Vega 10 alimentant la Radeon RX Vega 64, sorti en août 2017.
Le premier a une vitesse d'horloge fixe d'environ 775 MHz, tandis que le second a au moins trois débits disponibles:
- 850 MHz – lors du traitement de bureau, 2D
- 1250 MHz – pour les travaux 3D très lourds (appelés horloge de base)
- 1550 MHz – pour les charges 3D légères à moyennes (appelées booster l'horloge)
Nous disons «au moins» parce que la carte graphique peut varier dynamiquement sa vitesse d'horloge et la puissance consommée, entre les valeurs ci-dessus, en fonction de sa charge de travail et de sa température de fonctionnement. C'est quelque chose que nous tenons pour acquis maintenant, avec les derniers GPU, mais ce niveau de contrôle n'existait tout simplement pas il y a 13 ans. La capacité n'a cependant pas d'impact sur nos résultats d'efficacité, car nous avons seulement examiné de pointe la sortie de traitement (c'est-à-dire aux vitesses d'horloge maximales), mais cela affecte les performances de la carte pour le grand public.
Mais la raison la plus importante de l'augmentation constante de l'efficacité du traitement GPU au fil des ans est due aux changements dans l'utilisation du processeur lui-même. En juin 2008, les meilleurs superordinateurs du monde étaient tous alimentés par des processeurs AMD, IBM et Intel; onze ans plus tard et il y a un autre fournisseur de puces dans le mélange: Nvidia.

Leurs processeurs GV100 et GP100 ont été conçus presque exclusivement pour le marché de l'informatique, ils disposent d'un ensemble de fonctionnalités architecturales clés pour prendre en charge cela, et beaucoup d'entre eux sont très proches du CPU. Par exemple, la mémoire interne des puces (le cache) ressemble à celle d'un processeur de serveur typique:
- Fichier d'enregistrement par SM = 256 Ko
- Cache L0 par instruction SM = 12 Ko
- Cache L1 par SM = instruction 128 Ko / données 128 Ko
- Cache L2 par GPU = 6 Mo
Comparez cela au Xeon E5-2692 v2 d'Intel, qui a été utilisé dans de nombreux serveurs de calcul:
- Cache L1 par cœur = instruction 32 Ko / données 32 Ko
- Cache L2 par cœur = 256 Ko
- Cache L3 par CPU = 30 Mo
Les unités logiques à l'intérieur d'un GPU moderne prennent en charge une gamme de formats de données; certains ont des unités spécialisées pour les calculs d'entiers, de flottants et de matrices, tandis que d'autres ont des structures complexes qui les font tous. Les unités sont connectées à la mémoire cache et à la mémoire locale avec des interconnexions larges et rapides. Ces changements aident certainement au traitement des graphiques 3D, mais ils seraient considérés comme excessifs pour la plupart des jeux. Mais ces GPU ont été conçus pour un ensemble de charges de travail plus large que les seules images et il y a un nom pour cela: GPU à usage général (GPGPU).
L'apprentissage automatique et l'exploration de données sont deux domaines qui ont énormément bénéficié du développement des GPGPU et des progiciels et API pris en charge (par exemple, CUDA de Nvidia, ROMc d'AMD, OpenCL) car ils impliquent de nombreux calculs complexes et massivement parallèles.
Les grands GPU, remplis de milliers d'unités de shaders unifiés, sont parfaits pour de telles tâches, et AMD et Nvidia (et maintenant Intel se joint au plaisir) ont investi des milliards de dollars dans la R&D de puces qui offrent des performances de calcul toujours meilleures.

À l'heure actuelle, les deux sociétés conçoivent des architectures GPU qui peuvent être utilisées dans une variété de secteurs du marché et évitent généralement de faire des dispositions complètement distinctes pour les graphiques et les calculs. En effet, l'essentiel des bénéfices de la fabrication de GPU provient toujours de la vente de cartes graphiques 3D, mais il n'est pas certain que cela reste ainsi. Il est possible qu'à mesure que la demande de calcul continue d'augmenter, AMD ou Nvidia pourraient consacrer plus de ressources à l'amélioration de l'efficacité des puces pour ces marchés, et moins pour le rendu.
Mais quoi qu'il arrive ensuite, nous savons qu'une chose est certaine: la prochaine série de transistors multi-milliards de GPU haute puissance continuera d'être un peu plus efficace que leurs prédécesseurs. Et c'est une bonne nouvelle, peu importe qui le fabrique ou à quoi il sert.