
L'apprentissage automatique (ML) est devenu un sujet brûlant ces dernières années, mais ce que vous ne réalisez peut-être pas, c'est que le concept d'apprentissage automatique existe depuis des décennies. La conception des systèmes d'apprentissage automatique utilisés à ce jour est basée sur le modèle du cerveau humain décrit par Donald Hebb en 1949 dans son livre "The Organization of Behavior".
Hebb a noté que lorsque les cellules du cerveau tirent de manière répétée, des boutons synaptiques se forment ou s'agrandissent s'ils existent déjà. Le même principe est appliqué aux nœuds d'un réseau neuronal numérique. Les nœuds développent des relations qui se renforcent s'ils sont activés simultanément et s'affaiblissent s'ils se déclenchent séparément. L'apprentissage par renforcement est une forme d'apprentissage automatique basé sur ce concept, mais n'allons pas de l'avant.
"Le Machine Learning est l'étude d'algorithmes informatiques qui s'améliorent automatiquement par l'expérience." – Tom Mitchell
Le programmeur IBM et pionnier de l'IA, Arthur Samuel, a inventé le terme "machine learning" en 1952. Samuel avait écrit un programme de jeu de dames qui "apprenait" et s'améliorait avec le temps. Il a utilisé une technique appelée «élagage alpha-bêta», qui marquerait le tableau en fonction de la position des pièces et des chances de gagner de chaque côté. Ce modèle est devenu l'algorithme Minimax qui est toujours enseigné aujourd'hui.
Au fil des décennies, d'autres pionniers ont combiné, adapté et appliqué les modèles Hebb et Samuel (et ceux à suivre) à diverses applications. Par exemple, en 1957, Frank Rosenblatt a construit le perceptron Mark 1, l'une des toutes premières machines de reconnaissance d'images et le premier neuro-ordinateur à succès.
De nombreuses applications telles que la reconnaissance vocale et faciale, l'analyse de données, le traitement du langage naturel et même les alertes de phishing dans nos e-mails sont basées sur le travail de ces innovateurs.
Une décennie plus tard, en 1967, Marcello Pelillo a développé la "règle du plus proche voisin" pour la reconnaissance des formes. L'algorithme du plus proche voisin est le grand-père des applications de cartographie GPS d'aujourd'hui. D'autres ont continué à bâtir sur ces fondations en créant des réseaux de neurones perceptron multicouches dans les années 1960 et en rétropropagation dans les années 1970, que les chercheurs utilisent pour former des réseaux de neurones profonds.
Tous ces travaux antérieurs ont constitué les pierres angulaires de la recherche en cours aujourd'hui. De nombreuses applications comme la reconnaissance vocale et faciale, l'analyse de données, le traitement du langage naturel (synthèse vocale), et même les alertes de phishing dans notre courrier électronique sont basées sur le travail de ces innovateurs. L'automatisation d'aujourd'hui dans presque tous les secteurs de l'économie a mis l'apprentissage automatique au premier plan, mais il a toujours fonctionné en arrière-plan.
Qu'est-ce que l'apprentissage automatique?
Le monde universitaire ne s'est pas arrêté sur une définition standard pour l'apprentissage automatique. La portée du ML est large et ne se résume pas facilement à une seule phrase, bien que certains aient essayé …
La définition du MIT se lit comme suit: "Les algorithmes d'apprentissage automatique utilisent des statistiques pour trouver des modèles dans d'énormes quantités de données, [including] chiffres, mots, images, clics, qu'avez-vous. S'il peut être stocké numériquement, il peut être introduit dans un algorithme d'apprentissage automatique. "
"L'apprentissage automatique est la science qui permet aux ordinateurs d'agir sans être explicitement programmés", décrit le cours d'apprentissage automatique de Stanford.
Pendant ce temps, Carnegie Mellon dit: "Le domaine de l'apprentissage automatique cherche à répondre à la question:" Comment pouvons-nous construire des systèmes informatiques qui s'améliorent automatiquement avec l'expérience, et quelles sont les lois fondamentales qui régissent tous les processus d'apprentissage? ""
À des fins pratiques, nous pouvons jeter ces ingrédients dans notre pot et le réduire à ceci:
L'apprentissage automatique implique de former un ordinateur avec un grand nombre d'exemples pour prendre de façon autonome des décisions logiques basées sur une quantité limitée de données en entrée et pour améliorer ce processus avec l'utilisation.
Tous les ordinateurs «pensants» ne sont pas créés égaux
Nous entendons de nombreux autres termes dans les discussions sur l'apprentissage automatique, en particulier l'intelligence artificielle et l'apprentissage en profondeur. Bien que ces champs soient liés, ils ne sont pas identiques. Comprendre la relation entre ces technologies est essentiel pour apprendre ce qu'est exactement l'apprentissage automatique.
L'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond sont trois catégories informatiques qui s'imbriquent les unes dans les autres. Autrement dit, le machine learning est un sous-ensemble de l'IA, et le deep learning est un sous-ensemble du ML (voir schéma).
L'intelligence artificielle générale est un ensemble d'instructions qui indiquent à un ordinateur comment agir ou afficher un comportement humain. La façon dont il réagit à l'entrée est codée en dur, c'est-à-dire "Si cela se produit, faites-le". La règle générale est que si l'IA est explicitement informée des décisions à prendre, le programme se situe en dehors du domaine de l'apprentissage automatique.
L'apprentissage automatique est un sous-ensemble de l'IA qui peut agir de manière autonome. Contrairement à l'IA générale, il n'est pas nécessaire de dire à un algorithme ML comment interpréter les informations. Les réseaux neuronaux artificiels (ANN) les plus simples sont constitués d'une seule couche d'algorithmes d'apprentissage automatique (voir ci-dessous).
Comme un enfant, il doit être formé à l'aide de jeux de données étiquetés ou classifiés ou d'entrée. En d'autres termes, à mesure que les données sont introduites, il faut leur dire ce que c'est, c'est-à-dire qu'il s'agit d'un chat et d'un chien. Armé de ces informations, l'ANN peut ensuite terminer sa tâche sans instructions explicites pour accéder aux résultats ou à la sortie.
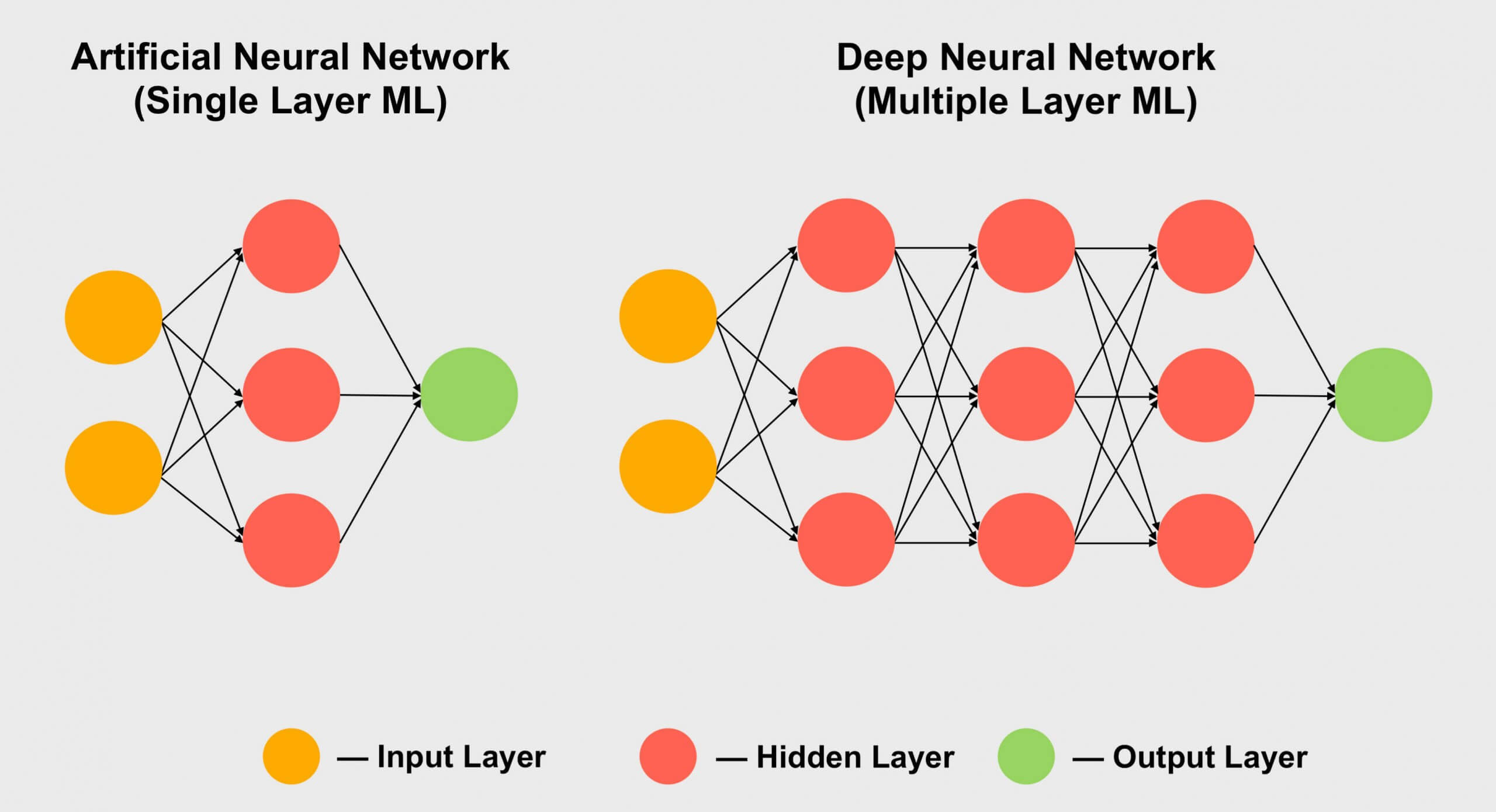
L'apprentissage profond est un sous-ensemble de l'IA et de l'apprentissage automatique. Ces constructions se composent de plusieurs couches d'algorithmes ML. Ainsi, ils sont souvent appelés «réseaux de neurones profonds» (DNN). L'entrée est transmise à travers les couches, chacune ajoutant des qualificatifs ou des balises. L'apprentissage en profondeur ne nécessite donc pas de données pré-classifiées pour effectuer des interprétations.
Nous explorerons plus en détail les différences entre ML et DL dans un instant.
Comment les réseaux de neurones apprennent-ils?
Qu'il s'agisse d'apprentissage automatique à couche unique ou de réseaux de neurones profonds, ils nécessitent tous deux une formation. Alors que certains programmes de ML simples, également appelés apprenants, peuvent être formés avec des quantités relativement petites d'échantillons d'informations, la plupart nécessitent de grandes quantités de données pour fonctionner avec précision.
Quels que soient les besoins initiaux du système ML en cours de formation, plus il est alimenté en exemples, mieux il fonctionne. Les apprenants profonds ont généralement besoin de plus de données d'entrée que le ML à couche unique, car ils ne savent pas comment classer les données. Il n'est pas rare que les systèmes utilisent des ensembles de données contenant des millions ou des centaines de millions d'exemples pour la formation.
La façon dont les programmes ML utilisent ce volume massif de données dépend du type d'apprentissage utilisé. Actuellement, il existe trois modèles d'apprentissage: supervisé, non supervisé et renforcé. Le choix de l'utilisation dépend principalement de ce qui doit être accompli.
Enseignement supervisé
L'apprentissage supervisé n'est pas ce que son nom l'indique. Les opérateurs ne restent pas assis à regarder l'apprenant pendant qu'il fonctionne et à l'ajuster pour les erreurs. L'apprentissage supervisé signifie simplement que les données d'entrée doivent être étiquetées ou classées pour que les algorithmes puissent faire leur travail. Le système doit savoir quelles sont les données d'entrée pour savoir quoi en faire.

L'apprentissage supervisé est la méthode de formation ML la plus courante et est utilisé dans de nombreuses applications familières.
Par exemple, de nombreux services tels que le PlayStation Network, Netflix, Spotify et d'autres l'utilisent pour générer automatiquement des listes organisées en fonction des préférences de l'utilisateur. Chaque fois qu'un utilisateur achète un jeu, regarde un film ou joue une chanson, les algorithmes ML enregistrent et analysent ces données et leurs balises, puis recherchent un contenu similaire. Plus le service est utilisé, mieux le système apprend et prédit ce que l'utilisateur souhaite.
Apprentissage non supervisé
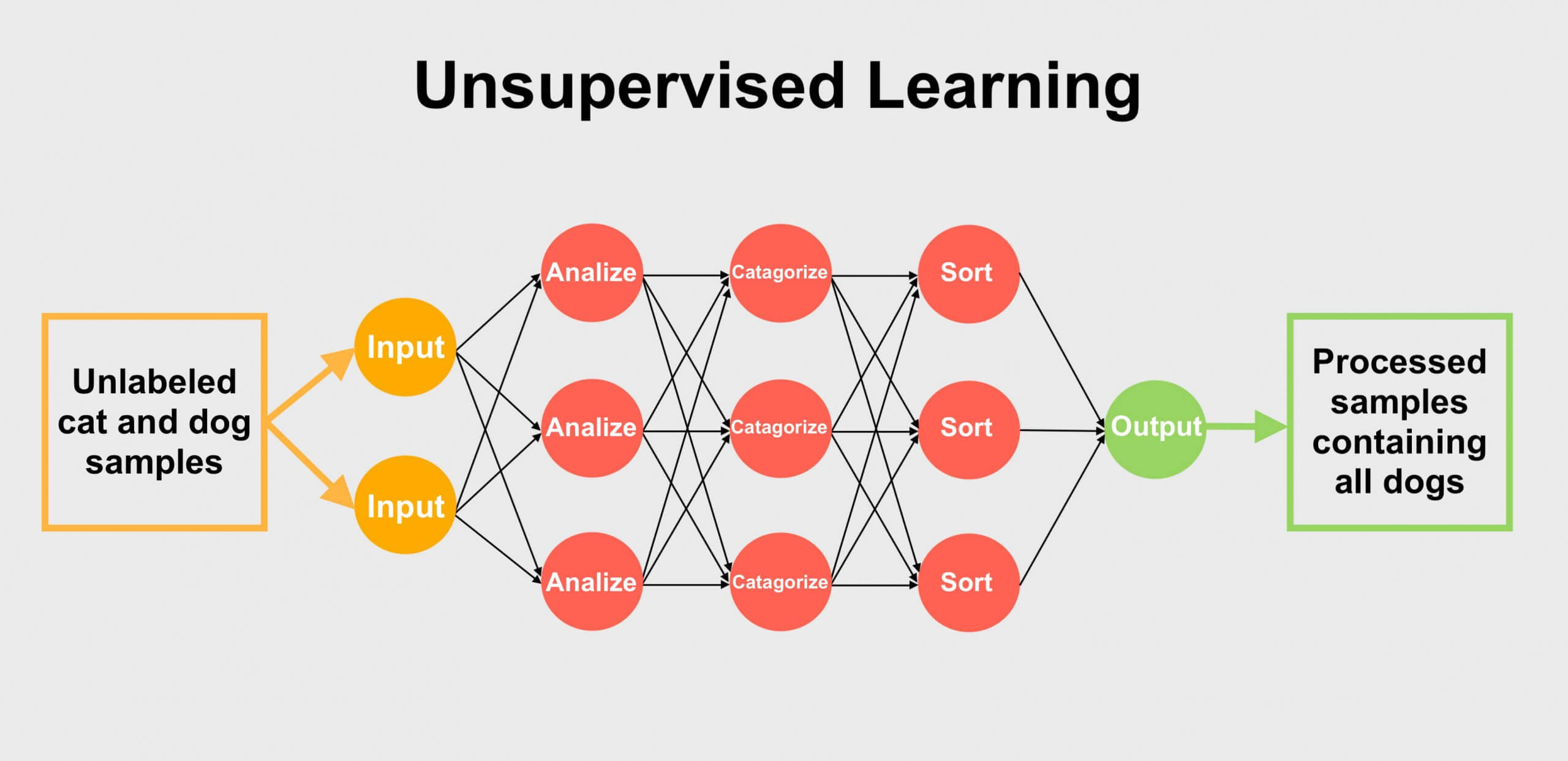
L'apprentissage non supervisé ne nécessite aucune étiquette. Dans ce cas, l'apprenant recherche des modèles et crée ses propres catégories. Par exemple, s'il est nourri d'une image d'un chien, il ne peut pas le classer comme tel car il n'y a pas de données pour lui dire que c'est ce que c'est. Au lieu de cela, il regarde des choses comme des formes ou des couleurs et crée une classification rudimentaire. En se nourrissant de plus de données, il peut affiner son profil de chiens, créant des balises supplémentaires qui les distinguent des autres objets ou animaux.
Les systèmes ML monocouche ne sont pas efficaces pour travailler avec une entrée sans étiquette. Cela s'explique en partie par le fait qu'il nécessite des réseaux de neurones profonds pour donner un sens à l'information. Les réseaux multicouches conviennent mieux à ce type de traitement des données car chaque couche remplit une fonction spécifique avec l'entrée avant de la transmettre à une autre couche avec ses résultats. Étant donné que les RNA sont beaucoup plus courants que les DNN, l'apprentissage non supervisé est considéré comme une forme rare de formation.
Cependant, il existe des exemples bien connus de systèmes ML qui utilisent un apprentissage non supervisé. Google Lens utilise cette méthode d'apprentissage pour identifier les objets à partir d'images statiques et en direct. Un autre exemple serait les algorithmes que la société de cybersécurité Darktrace utilise pour détecter les fuites de sécurité internes. Le système ML de Darktrace utilise un apprentissage non supervisé d'une manière qui n'est pas différente du système immunitaire humain.
"Cela ressemble beaucoup au système immunitaire du corps humain", a déclaré la co-PDG Nicole Eagan au MIT Technology Review. "Aussi complexe soit-il, il a ce sens inné de ce qui est soi et non soi. Et quand il trouve quelque chose qui n'appartient pas – ce n'est pas soi-même – il a une réponse extrêmement précise et rapide."
Apprentissage par renforcement
La troisième méthode de formation traite également des données non étiquetées. En tant que tel, l'apprentissage par renforcement n'est également utilisé que chez les apprenants profonds. Les systèmes non supervisés et renforcés traitent les données avec des objectifs prédéfinis spécifiques. La façon dont ils atteignent ces objectifs est là où les algorithmes diffèrent.
Contrairement aux apprenants non supervisés, qui opèrent selon des paramètres spécifiques pour les conduire à l'objectif final, l'apprentissage par renforcement utilise un système de notation pour le diriger vers le résultat souhaité.
Les algorithmes tentent différentes manières d'atteindre leur objectif et sont récompensés ou pénalisés selon que leur approche est efficace ou inefficace pour obtenir les résultats finaux. La formation de renforcement est bien adaptée pour enseigner à l'IA comment jouer et gagner à des jeux comme Go, Chess, Dota 2 ou même Pac-Man.
<iframe allowfullscreen = "" frameborder = "0" height = "390" src = "https://www.youtube.com/embed/QilHGSYbjDQ?rel=0&showinfo=0&modestbranding=1&vq=hd720&autohide=1&autoplay=1" width = " 560 "loading =" lazy "srcdoc ="
 ▶">
▶">
Ce système de formation est analogue à jouer au jeu Hot and Cold avec un enfant en bas âge. Vous dites à l'enfant de trouver le ballon, et pendant qu'il le regarde, vous le dirigez avec les mots de renforcement "plus chaud" et "plus froid" selon qu'il se rapproche ou s'éloigne du ballon – le renforcement. En utilisant un apprentissage non supervisé, le tout-petit devrait trouver le ballon en suivant une carte ou des directions prédéfinies. Dans les deux cas, l'enfant doit encore comprendre ce qu'est une balle.
L'apprentissage par renforcement est la plus récente forme de formation pour les systèmes de ML et a connu une augmentation de la recherche ces dernières années. Comme mentionné précédemment, le jeu de dames d'Arthur Samuel de 1952 était une première forme d'apprentissage automatique par renforcement. Maintenant, les apprenants profonds comme AlphaGo de Google et le bot Dota 2 d'OpenAi, «Five», utilisent l'apprentissage par renforcement pour battre les joueurs humains professionnels dans des jeux beaucoup plus compliqués que les dames.
L'apprentissage automatique aujourd'hui et demain
Bien que l'apprentissage automatique existe depuis des décennies, ce n'est que ces dernières années que nous avons vu une forte poussée pour des applications pratiques qui utilisent la technologie. Il y a de fortes chances que vous utilisiez régulièrement un appareil ou une application qui repose sur des algorithmes ML. Les smartphones sont un exemple évident, tout comme diverses applications telles que les assistants vocaux, les cartes et les trackers d'exercice. Il existe également d'autres cas d'utilisation moins évidents, mais qui peuvent faire des choses incroyables.
Les systèmes de surveillance sont loin d'être de simples caméras vidéo montées surveillées par le personnel de sécurité de nos jours. Les systèmes avancés utilisent désormais l'apprentissage automatique pour automatiser diverses tâches, notamment la détection des comportements suspects et le suivi des individus par reconnaissance faciale.
Travaillant dans les casinos du Nevada depuis de nombreuses années, j'ai vu de visu un système de surveillance qui pouvait non seulement signaler les tricheurs potentiels, mais aussi suivre le suspect dans tout le casino en passant automatiquement à la caméra qui avait la personne en vue. C'était incroyable de regarder le système de surveillance alors qu'il suivait quelqu'un à travers le casino et même dans le parking sans aucune intervention humaine.
«Le monde manque de capacité de calcul. La loi de Moore s'essouffle un peu… [we need quantum computing to] créer toutes ces expériences riches dont nous parlons, toute cette intelligence artificielle. "- Satya Nadella, PDG de Microsoft.
Les applications d'apprentissage automatique que nous voyons aujourd'hui sont déjà assez étonnantes, mais que nous réserve l'avenir? Le domaine de l'intelligence artificielle commence à peine à s'épanouir.
Les algorithmes d'apprentissage automatique et d'apprentissage en profondeur ont une marge de croissance infinie, et nous sommes sûrs de voir des applications encore plus pratiques pénétrer les marchés des consommateurs et des entreprises au cours de la prochaine décennie. En fait, Forbes note que 82% des leaders du marketing adoptent déjà le machine learning pour améliorer la personnalisation. Ainsi, nous pouvons nous attendre à voir ML exploité commercialement dans la publicité ciblée et la personnalisation des services dans le futur.
Le prochain grand boom sera probablement l'apprentissage automatique quantique. Des chercheurs du MIT, d'IBM et de la NASA ont déjà expérimenté l'application de l'informatique quantique à l'apprentissage automatique. Sans surprise, ils ont constaté que certains problèmes peuvent être résolus en une fraction du temps par rapport au matériel de traitement contemporain. Sur cette même note, Microsoft et Google ont récemment annoncé leur intention d'aller de l'avant dans le domaine du ML quantique, il est donc probable que nous entendrons et verrons beaucoup plus de choses dans un avenir proche.