
Au cours des trois dernières années, Nvidia fabrique des puces graphiques dotées de cœurs supplémentaires, au-delà de celles normalement utilisées pour les shaders. Connues sous le nom de cœurs tensoriels, ces unités mystérieuses se trouvent dans des milliers d'ordinateurs de bureau, d'ordinateurs portables, de stations de travail et de centres de données à travers le monde. Mais que sont-ils exactement et à quoi servent-ils? En avez-vous vraiment besoin dans une carte graphique?
Aujourd'hui, nous allons vous expliquer ce qu'est un tenseur et comment les cœurs de tenseur sont utilisés dans le monde du graphisme et du deep learning.
Temps pour une leçon de mathématiques rapide
Pour comprendre exactement ce que font les noyaux tensoriels et à quoi ils peuvent être utilisés, nous devons d'abord couvrir exactement ce que sont les tenseurs. Les microprocesseurs, quelle que soit leur forme, effectuent tous des opérations mathématiques (addition, multiplication, etc.) sur les nombres.
Parfois, ces nombres doivent être regroupés, car ils ont une certaine signification l'un pour l'autre. Par exemple, lorsqu'une puce traite des données pour rendre des graphiques, elle peut avoir affaire à des valeurs entières uniques (telles que +2 ou +115) pour un facteur d'échelle, ou un groupe de nombres à virgule flottante (+0,1, -0,5, + 0.6) pour les coordinations d'un point dans l'espace 3D. Dans le cas de ce dernier, la position de l'emplacement nécessite les trois éléments de données.
Un tenseur est un objet mathématique qui décrit la relation entre d'autres objets mathématiques qui sont tous liés entre eux.
UNE tenseur est un objet mathématique qui décrit la relation entre d'autres objets mathématiques qui sont tous liés entre eux. Ils sont généralement représentés comme un tableau de nombres, où la dimension du tableau peut être visualisée comme indiqué ci-dessous.
Le type de tenseur le plus simple que vous puissiez obtenir aurait des dimensions nulles et se composerait d'une seule valeur – un autre nom pour cela est un scalaire quantité. À mesure que nous commençons à augmenter le nombre de dimensions, nous pouvons rencontrer d'autres structures mathématiques courantes:
- 1 dimension = vecteur
- 2 dimensions = matrice
Strictement parlant, un scalaire est un tenseur 0 x 0, un vecteur est 1 x 0 et une matrice est 1 x 1, mais par souci de simplicité et de son rapport avec les cœurs de tenseur dans un processeur graphique, nous allons simplement traiter avec des tenseurs sous forme de matrices.
L'une des opérations mathématiques les plus importantes effectuées avec des matrices est une multiplication (ou un produit). Voyons comment deux matrices, toutes deux avec 4 lignes et colonnes de valeurs, se multiplient ensemble:
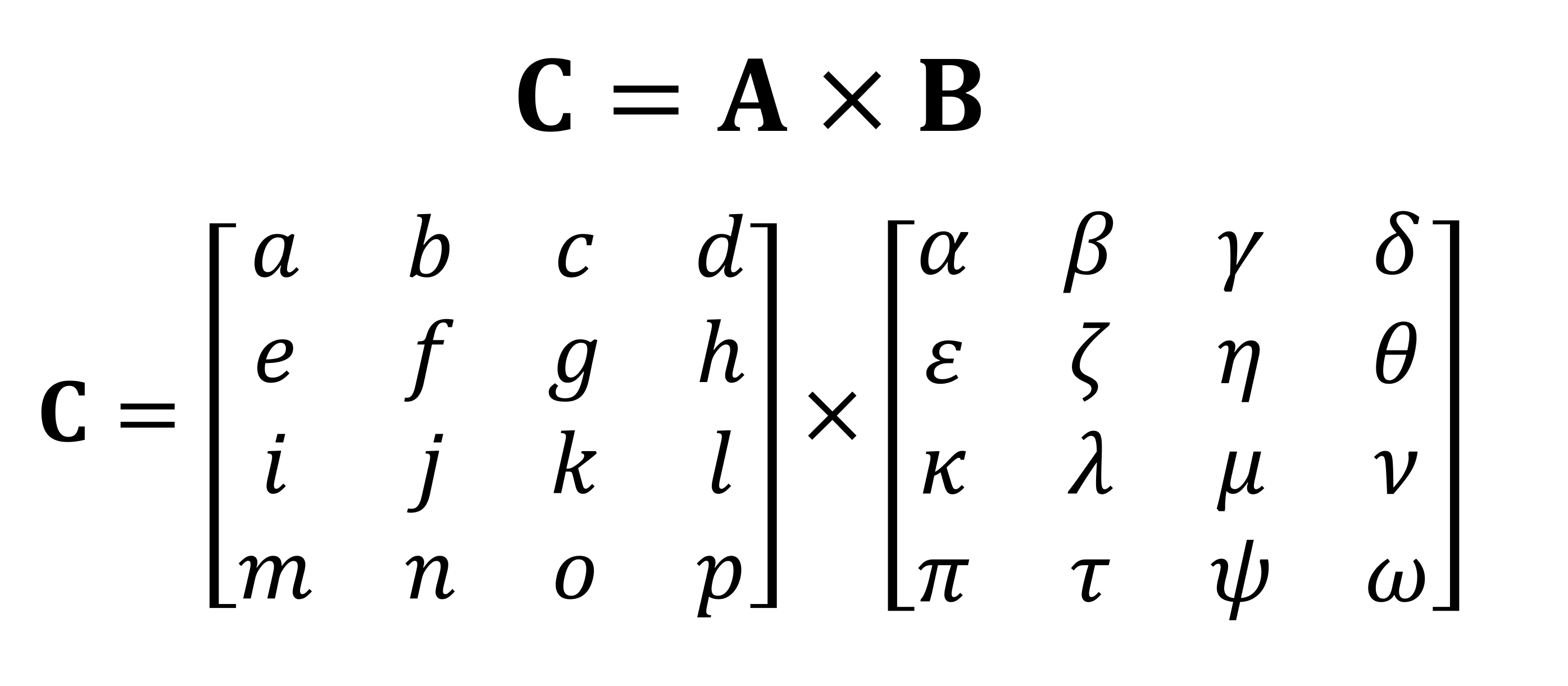
La réponse finale à la multiplication a toujours le même nombre de lignes que la première matrice, et le même nombre de colonnes que la seconde. Alors, comment multipliez-vous ces deux tableaux? Comme ça:
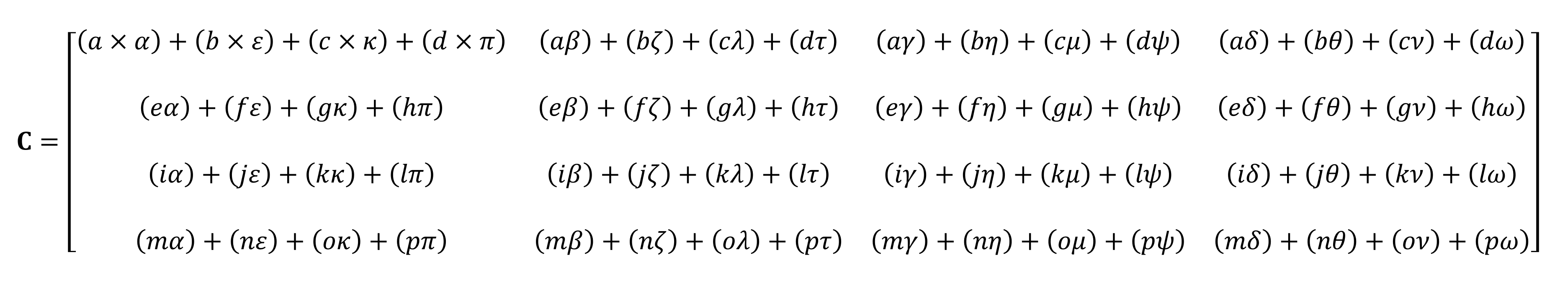
Comme vous pouvez le voir, un calcul de produit matriciel «simple» consiste en une pile entière de petites multiplications et additions. Étant donné que chaque processeur sur le marché aujourd'hui peut effectuer ces deux opérations, cela signifie que n'importe quel ordinateur de bureau, ordinateur portable ou tablette peut gérer des tenseurs de base.
Cependant, l'exemple ci-dessus contient 64 multiplications et 48 additions; chaque petit produit aboutit à une valeur qui doit être stockée quelque part, avant de pouvoir être accumulée avec les 3 autres petits produits, avant que la valeur finale du tenseur puisse être stockée quelque part. Ainsi, bien que les multiplications matricielles soient mathématiquement simples, elles informatique intensif – beaucoup de registres doivent être utilisés, et le cache doit faire face à de nombreuses lectures et écritures.

Les processeurs AMD et Intel ont proposé diverses extensions au fil des ans (MMX, SSE, maintenant AVX – tous sont SIMD, instruction unique plusieurs données) qui permet au processeur de gérer plusieurs nombres à virgule flottante en même temps; exactement ce dont les multiplications matricielles ont besoin.
Mais il existe un type spécifique de processeur surtout conçu pour gérer les opérations SIMD: unités de traitement graphique (GPU).
Plus intelligent que votre calculatrice moyenne?
Dans le monde du graphisme, une énorme quantité de données doit être déplacée et traitée sous forme de vecteurs, le tout en même temps. La capacité de traitement parallèle des GPU les rend idéaux pour gérer les tenseurs et tous prennent aujourd'hui en charge ce qu'on appelle un GEMM (Multiplication générale de la matrice).
Il s'agit d'une opération «fusionnée», où deux matrices sont multipliées ensemble, et la réponse à laquelle est ensuite accumulée avec une autre matrice. Il existe des restrictions importantes sur le format que les matrices doivent prendre et elles tournent autour du nombre de lignes et de colonnes de chaque matrice.
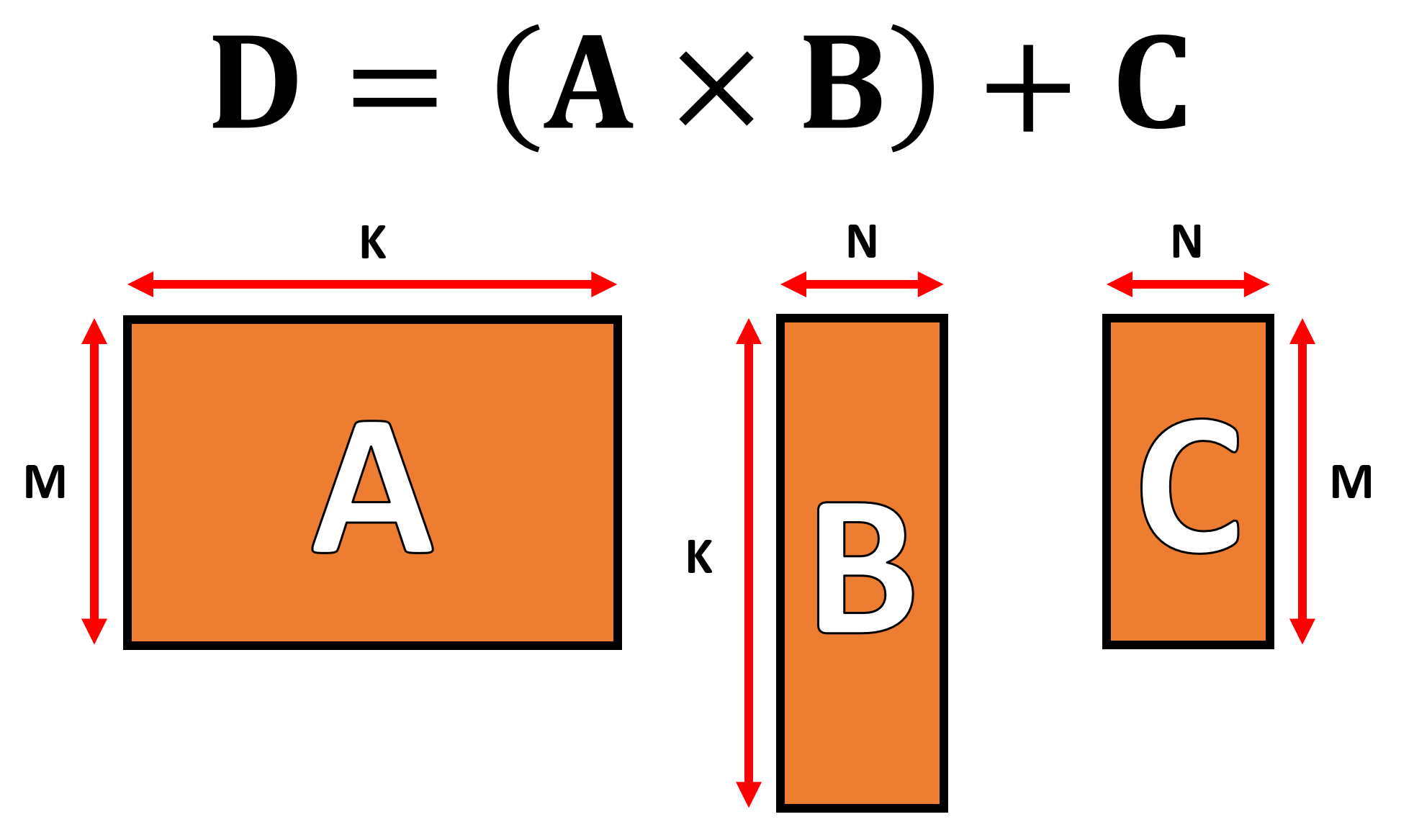
Les algorithmes utilisés pour effectuer des opérations matricielles ont tendance à mieux fonctionner lorsque les matrices sont carrées (par exemple, l'utilisation de tableaux 10 x 10 fonctionnerait mieux que 50 x 2) et de taille assez petite. Mais ils fonctionnent toujours mieux lorsqu'ils sont traités sur du matériel uniquement dédié à ces opérations.
En décembre 2017, Nvidia a sorti une carte graphique dotée d'un GPU avec une nouvelle architecture appelée Volta. Il était destiné aux marchés professionnels, donc aucun modèle GeForce n'a jamais utilisé cette puce. Ce qui le rendait spécial, c'est que c'était le premier processeur graphique à avoir des cœurs uniquement pour les calculs de tenseurs.

Avec zéro imagination derrière la dénomination, Nvidia noyaux tenseur ont été conçus pour transporter 64 GEMM par cycle d'horloge sur des matrices 4 x 4, contenant des valeurs FP16 (nombres à virgule flottante de 16 bits) ou une multiplication FP16 avec addition FP32. Ces tenseurs sont de très petite taille, donc lors de la manipulation d'ensembles de données réels, les cœurs transforment de petits blocs de matrices plus grandes, constituant la réponse finale.
Moins d'un an plus tard, Nvidia a lancé l'architecture Turing. Cette fois, les modèles GeForce de qualité grand public arboraient également des cœurs tensoriels. Le système avait été mis à jour pour prendre en charge d'autres formats de données, tels que INT8 (valeurs entières 8 bits), mais à part cela, ils fonctionnaient toujours comme ils le faisaient en Volta.

Plus tôt cette année, l'architecture Ampere a fait ses débuts dans le processeur graphique du centre de données A100, et cette fois Nvidia a amélioré les performances (256 GEMM par cycle, contre 64), ajouté d'autres formats de données et la capacité de gérer tenseurs clairsemés (matrices contenant beaucoup de zéros) très rapidement.
Pour les programmeurs, accéder aux cœurs de tenseur dans l'une des puces Volta, Turing ou Ampère est facile: le code doit simplement utiliser un indicateur pour indiquer à l'API et aux pilotes que vous souhaitez utiliser des cœurs de tenseur, le type de données doit être pris en charge par les cœurs, et les dimensions des matrices doivent être un multiple de 8. Après cela, ce matériel gérera tout le reste.
Tout cela est bien, mais à quel point les cœurs de tenseur sont-ils meilleurs pour gérer les GEMM que les cœurs normaux d'un GPU?
Lorsque Volta est apparu pour la première fois, Anandtech a effectué des tests de mathématiques en utilisant trois cartes Nvidia: la nouvelle Volta, une carte haut de gamme basée sur Pascal et une ancienne carte Maxwell.
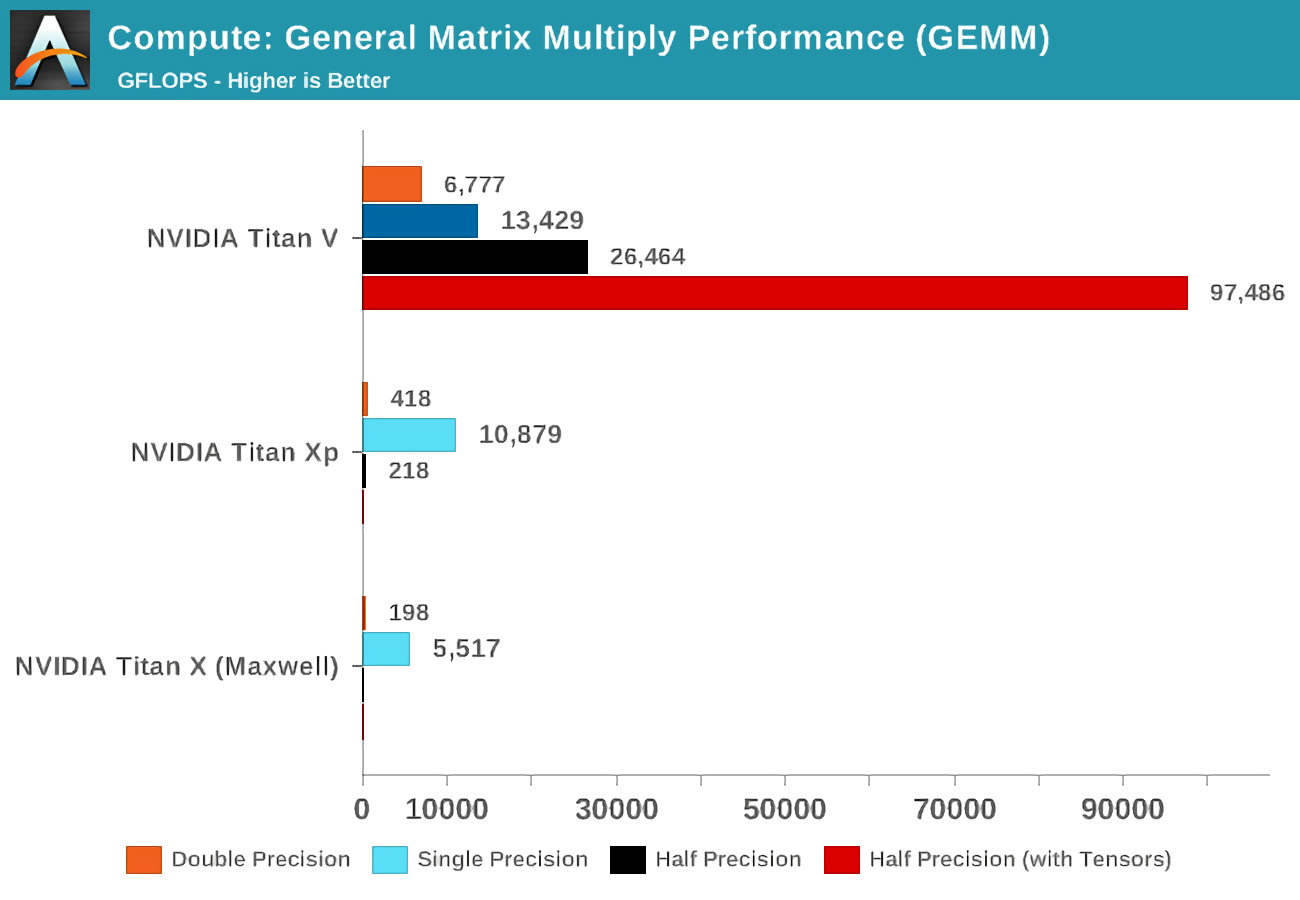
Le terme précision fait référence au nombre de bits utilisés pour les nombres à virgule flottante dans les matrices, le double étant 64, le simple 32, et ainsi de suite. L'axe horizontal fait référence au nombre maximal d'opérations FP effectuées par seconde ou FLOP en abrégé (rappelez-vous qu'un GEMM est 3 FLOP).
Il suffit de regarder quel a été le résultat lorsque les cœurs de tenseur ont été utilisés, au lieu des cœurs standard dits CUDA! Ils sont clairement fantastiques dans ce genre de travail, alors quoi pouvez vous faites avec des noyaux tensoriels?
Les mathématiques pour tout améliorer
Le calcul tensoriel est extrêmement utile en physique et en ingénierie, et est utilisé pour résoudre toutes sortes de problèmes complexes en mécanique des fluides, électromagnétisme et astrophysique, mais les ordinateurs utilisés pour calculer ces nombres ont tendance à effectuer des opérations matricielles sur de grands groupes de processeurs.
L'apprentissage automatique est un autre domaine qui aime utiliser des tenseurs, en particulier le sous-ensemble d'apprentissage profond. Il s'agit de gérer d'énormes collections de données, dans d'énormes tableaux appelés réseaux de neurones. Les connexions entre les différentes valeurs de données reçoivent un poids spécifique – un nombre qui exprime l'importance de cette connexion.
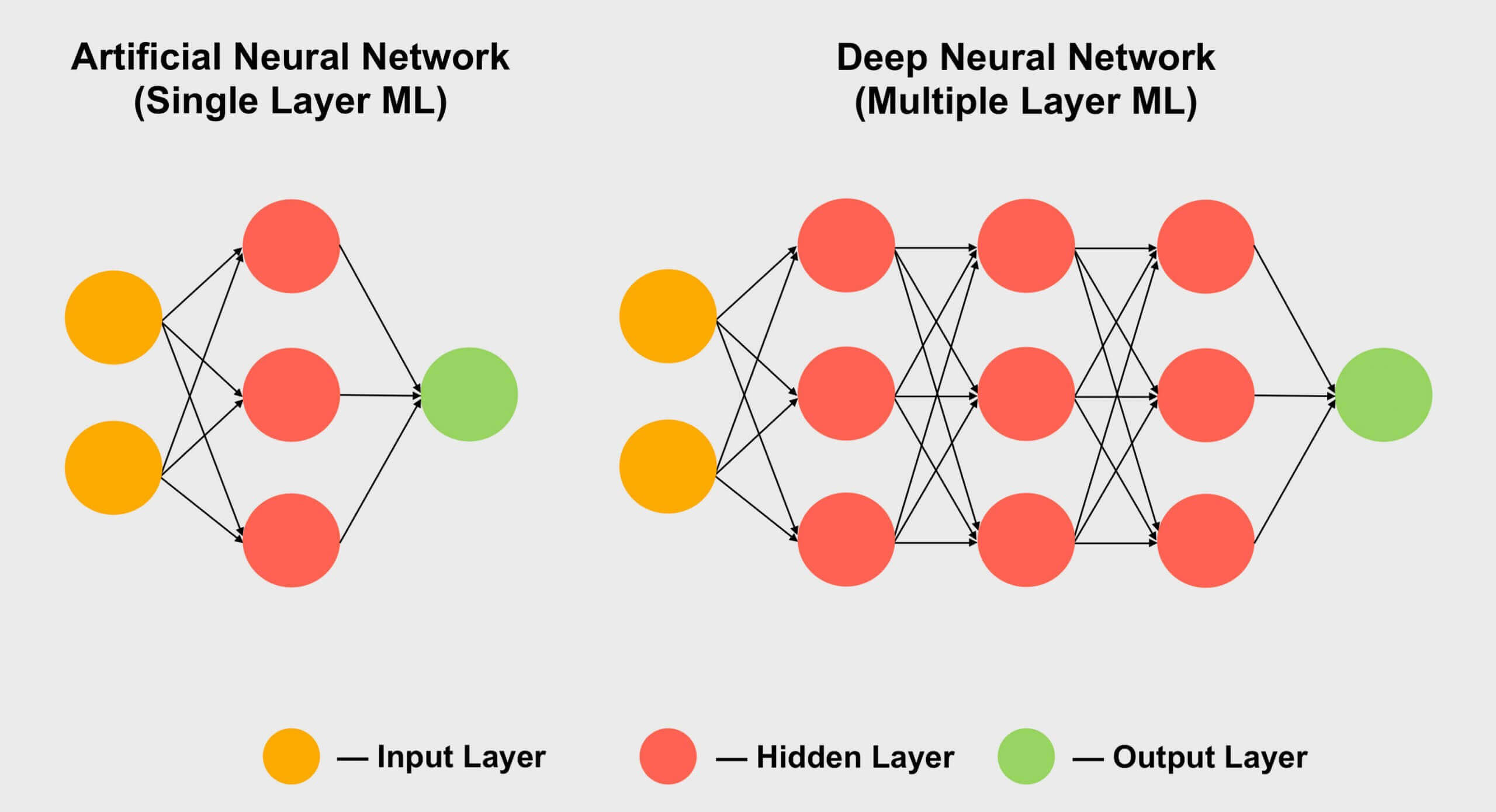
Ainsi, lorsque vous devez déterminer comment interagissent les centaines, voire les milliers, de connexions, vous devez multiplier chaque élément de données du réseau par tous les poids de connexion différents. En d'autres termes, multipliez deux matrices ensemble: les mathématiques tensorielles classiques!

C'est pourquoi tous les gros superordinateurs d'apprentissage en profondeur sont remplis de GPU et presque toujours de Nvidia. Cependant, certaines entreprises sont allées jusqu'à fabriquer leurs propres processeurs tenseur core. Google, par exemple, a annoncé son premier TPU (unité de traitement tenseur) en 2016 mais ces puces sont tellement spécialisées qu'elles ne peuvent rien faire d'autre que des opérations matricielles.
Tensor Core dans les GPU grand public (GeForce RTX)
Mais que se passe-t-il si vous avez une carte graphique Nvidia GeForce RTX et que vous n'êtes pas un astrophysicien résolvant des problèmes avec des variétés riemanniennes ou expérimentant les profondeurs des réseaux de neurones convolutifs …? À quoi servent les noyaux tensoriels pour vous?
Pour la plupart, ils ne sont pas utilisés pour le rendu normal, l'encodage ou le décodage de vidéos, ce qui peut donner l'impression que vous avez gaspillé votre argent sur une fonctionnalité inutile. Cependant, Nvidia a mis des cœurs de tenseur dans ses produits grand public en 2018 (Turing GeForce RTX) tout en introduisant DLSS – Super échantillonnage d'apprentissage en profondeur.

Le principe de base est simple: rendre une image à une résolution faible et, une fois terminé, augmenter la résolution du résultat final afin qu'il corresponde aux dimensions de l'écran natif du moniteur (par exemple, rendre à 1080p, puis le redimensionner à 1400p). De cette façon, vous obtenez l'avantage de traiter moins de pixels, tout en obtenant une belle image à l'écran.
Les consoles font quelque chose comme ça depuis des années, et de nombreux jeux PC actuels en offrent également la possibilité. Dans Assassin's Creed: Odyssey d'Ubisoft, vous pouvez modifier la résolution de rendu jusqu'à seulement 50% de celle du moniteur. Malheureusement, le résultat n'a pas l'air si chaud. Voici à quoi ressemble le jeu en 4K, avec les paramètres graphiques maximum appliqués (cliquez pour voir la version en pleine résolution):

Courir à des résolutions élevées signifie que les textures sont bien meilleures, car elles conservent des détails fins. Malheureusement, tous ces pixels nécessitent beaucoup de traitement pour les produire. Maintenant, regardez ce qui se passe lorsque le jeu est configuré pour un rendu à 1080p (25% de la quantité de pixels qu'avant), mais utilisez ensuite des shaders à la fin pour l'étendre à 4K.

La différence n'est peut-être pas immédiatement évidente, grâce à la compression jpeg et au redimensionnement des images sur notre site Web, mais l'armure du personnage et la formation rocheuse à distance sont quelque peu floues. Zoomons sur une section pour une inspection plus approfondie:

La section de gauche a été rendue nativement à 4K; sur la droite, c'est 1080p converti en 4K. La différence est beaucoup plus prononcée une fois que le mouvement est impliqué, car l'adoucissement de tous les détails devient rapidement une bouillie floue. Une partie de cela pourrait être récupérée en utilisant un effet de netteté dans les pilotes de la carte graphique, mais il serait préférable de ne pas avoir à le faire du tout.
C'est là que DLSS joue son rôle – dans la première itération de la technologie Nvidia, des jeux sélectionnés ont été analysés, les exécutant à basse résolution, haute résolution, avec et sans anti-aliasing. Tous ces modes ont généré une multitude d'images qui ont été introduites dans leurs propres supercalculateurs, qui ont utilisé un réseau de neurones pour déterminer la meilleure façon de transformer une image 1080p en une parfaite résolution supérieure.

Il faut dire que DLSS 1.0 n'était pas génial, avec des détails souvent perdus ou des miroitements étranges à certains endroits. Il n'a pas non plus utilisé les cœurs de tenseur de votre carte graphique (cela a été fait sur le réseau de Nvidia) et chaque jeu prenant en charge DLSS nécessitait son propre examen par Nvidia pour générer l'algorithme de mise à l'échelle.

Lorsque la version 2.0 est sortie début 2020, de grandes améliorations avaient été apportées. Le plus notable était que les supercalculateurs de Nvidia n'étaient utilisés que pour créer un algorithme général de mise à l'échelle – dans la nouvelle itération de DLSS, les données de l'image rendue seraient utilisées pour traiter les pixels (via les cœurs de tenseur de votre GPU) en utilisant le modèle neuronal. .

Nous restons impressionnés par ce que DLSS 2.0 peut accomplir, mais pour l'instant, très peu de jeux le prennent en charge – seulement 12 au total, au moment de la rédaction de cet article. De plus en plus de développeurs cherchent à l'implémenter dans leurs futures versions, cependant, et pour de bonnes raisons.
Il y a de gros gains de performances à trouver, en faisant tout type de mise à l'échelle, vous pouvez donc parier votre dernier dollar que le DLSS continuera d'évoluer.
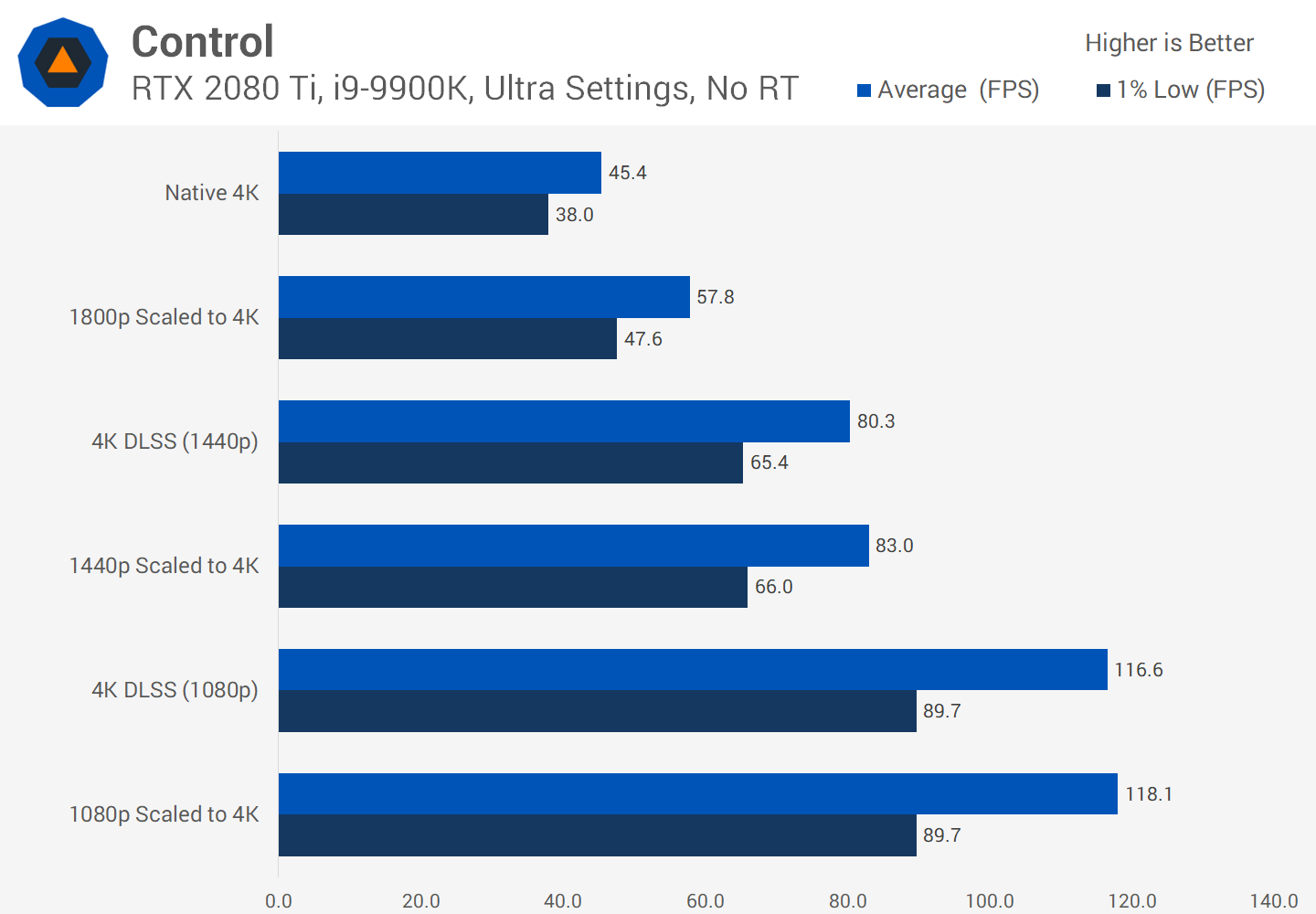
Bien que la sortie visuelle de DLSS ne soit pas toujours parfaite, en libérant les performances de rendu, les développeurs ont la possibilité d'inclure plus d'effets visuels ou d'offrir les mêmes graphiques sur une plus large gamme de plates-formes.
Par exemple, DLSS est souvent vu promu aux côtés du traçage de rayons dans les jeux «RTX enabled». Les GPU GeForce RTX contiennent des unités de calcul supplémentaires appelées cœurs RT: des unités logiques dédiées pour accélérer les calculs d'intersection rayon-triangle et de traversée de la hiérarchie des volumes englobants (BVH). Ces deux processus sont des routines chronophages pour déterminer où une lumière interagit avec le reste des objets dans une scène.
Comme nous l'avons découvert, le traçage de rayons est très intensif, donc pour offrir des performances jouables, les développeurs de jeux doivent limiter le nombre de rayons et de rebonds effectués dans une scène. Ce processus peut également donner des images granuleuses, donc un algorithme de débruitage doit être appliqué, ajoutant à la complexité du traitement. On s'attend à ce que les cœurs Tensor améliorent les performances ici en utilisant le débruitage basé sur l'IA, bien que cela ne se soit pas encore matérialisé avec la plupart des applications actuelles utilisant encore des cœurs CUDA pour cette tâche. Du côté positif, le DLSS 2.0 devenant une technique de mise à l'échelle viable, les cœurs de tenseur peuvent effectivement être utilisés pour augmenter les fréquences d'images après l'application du lancer de rayons à une scène.
Il existe également d'autres plans pour les cœurs de tenseur dans les cartes GeForce RTX, comme une meilleure animation des personnages ou une simulation de tissu. Mais comme DLSS 1.0 avant eux, il faudra un certain temps avant que des centaines de jeux utilisent régulièrement les calculatrices matricielles spécialisées dans les GPU.
Les premiers jours mais la promesse est là
Alors voilà – des cœurs de tenseurs, de petits morceaux de matériel astucieux, mais que l'on ne trouve que dans un petit nombre de cartes graphiques grand public. Cela changera-t-il à l'avenir? Étant donné que Nvidia a déjà considérablement amélioré les performances d'un seul noyau de tenseur dans sa dernière architecture Ampère, il y a de fortes chances que nous voyions davantage de modèles de milieu de gamme et de budget les arborant également.
Bien qu'AMD et Intel ne les aient pas dans leurs GPU, nous pourrions voir quelque chose de similaire mis en œuvre par eux à l'avenir. AMD propose un système pour affiner ou améliorer les détails des cadres terminés, pour un coût de performance minime, de sorte qu'ils peuvent bien s'en tenir à cela – d'autant plus qu'il n'a pas besoin d'être intégré par les développeurs; c'est juste une bascule dans les pilotes.
Il y a aussi l'argument selon lequel l'espace de la puce dans les puces graphiques pourrait être mieux dépensé pour simplement ajouter plus de cœurs de shader, ce que Nvidia a fait quand ils ont construit les versions économiques de leurs puces Turing. Les goûts de la GeForce GTX 1650 ont complètement abandonné les cœurs de tenseur et les ont remplacés par des shaders FP16 supplémentaires.
Mais pour l'instant, si vous voulez profiter d'un débit GEMM ultra rapide et de tous les avantages que cela peut apporter, vous avez deux choix: vous procurer un tas d'énormes processeurs multicœurs ou juste un GPU avec des cœurs tensoriels.
Plus de lectures techniques
Raccourcis d'achat:
- GeForce GTX 1660 Super sur Amazon
- GeForce RTX 2060 sur Amazon
- GeForce RTX 2070 Super sur Amazon
- GeForce RTX 2080 Super sur Amazon
- GeForce RTX 2080 Ti sur Amazon
- Radeon RX 5600 XT sur Amazon
- Radeon RX 5700 XT sur Amazon