
Le CPU est souvent appelé le cerveau d'un ordinateur et, tout comme le cerveau humain, il se compose de plusieurs parties qui travaillent ensemble pour traiter les informations. Il existe des parties qui contiennent des informations, des parties qui stockent des informations, des parties qui traitent des informations, des parties qui aident à la sortie d'informations, etc. Dans l'explicateur d'aujourd'hui, nous allons passer en revue les éléments clés qui composent un processeur et comment ils fonctionnent tous ensemble pour alimenter votre ordinateur.
Vous devez savoir, cet article fait partie de notre Série d'anatomie qui dissèque toute la technologie derrière les composants PC. Nous avons également une série dédiée à Conception du CPU qui va plus loin dans le processus de conception du CPU et comment les choses fonctionnent en interne. C'est une lecture technique hautement recommandée. Cet article d'anatomie revisitera certains des principes fondamentaux de la série CPU, mais à un niveau supérieur et avec un contenu supplémentaire.
Comparé aux articles précédents de notre série Anatomie, celui-ci sera forcément plus abstrait. Lorsque vous regardez à l'intérieur de quelque chose comme une alimentation, vous pouvez clairement voir les condensateurs, transformateurs et autres composants. Ce n'est tout simplement pas possible avec un processeur moderne car tout est si petit et parce qu'Intel et AMD ne divulguent pas publiquement leurs conceptions. La plupart des conceptions de CPU sont propriétaires, donc les sujets traités dans cet article représentent les fonctionnalités générales de tous les CPU.
 Série Anatomie du matériel informatique de
Série Anatomie du matériel informatique de
 Série Anatomie du matériel informatique de
Série Anatomie du matériel informatique de Vous pouvez avoir un ordinateur de bureau au travail, à l'école ou à la maison. Vous pouvez en utiliser un pour établir des déclarations de revenus ou jouer aux derniers jeux; vous pourriez même être en train de construire et de peaufiner des ordinateurs. Mais dans quelle mesure connaissez-vous les composants qui composent un PC?
Plongeons-nous donc. Chaque système numérique a besoin d'une forme d'unité centrale de traitement. Fondamentalement, un programmeur écrit du code pour faire quelle que soit sa tâche, puis un processeur exécute ce code pour produire le résultat souhaité. Le CPU est également connecté à d'autres parties d'un système comme la mémoire et les E / S pour l'aider à se nourrir des données pertinentes, mais nous ne couvrirons pas ces systèmes aujourd'hui.
Le plan directeur du processeur: un ISA
Lors de l'analyse d'un processeur, la première chose que vous rencontrerez est l'architecture du jeu d'instructions (ISA). Il s'agit du schéma figuratif du fonctionnement du CPU et de l'interaction entre tous les systèmes internes. Tout comme il existe de nombreuses races de chiens au sein d'une même espèce, il existe de nombreux types d'ISA différents sur lesquels un processeur peut être construit. Les deux types les plus courants sont x86 (que l'on trouve sur les ordinateurs de bureau et portables) et ARM (que l'on trouve sur les appareils intégrés et mobiles).
Il y en a d'autres comme MIPS, RISC-V et PowerPC qui ont plus d'applications de niche. Un ISA spécifiera quelles instructions le processeur peut traiter, comment il interagit avec la mémoire et les caches, comment le travail est divisé en plusieurs étapes de traitement, et plus encore.

Pour couvrir les principales parties d'un processeur, nous suivrons le chemin emprunté par une instruction lors de son exécution. Différents types d'instructions peuvent suivre des chemins différents et utiliser différentes parties d'un processeur, mais nous généraliserons ici pour couvrir les plus grandes parties. Nous commencerons par la conception la plus élémentaire d'un processeur simple cœur et ajouterons progressivement de la complexité à mesure que nous nous orienterons vers une conception plus moderne.
Unité de contrôle et chemin de données
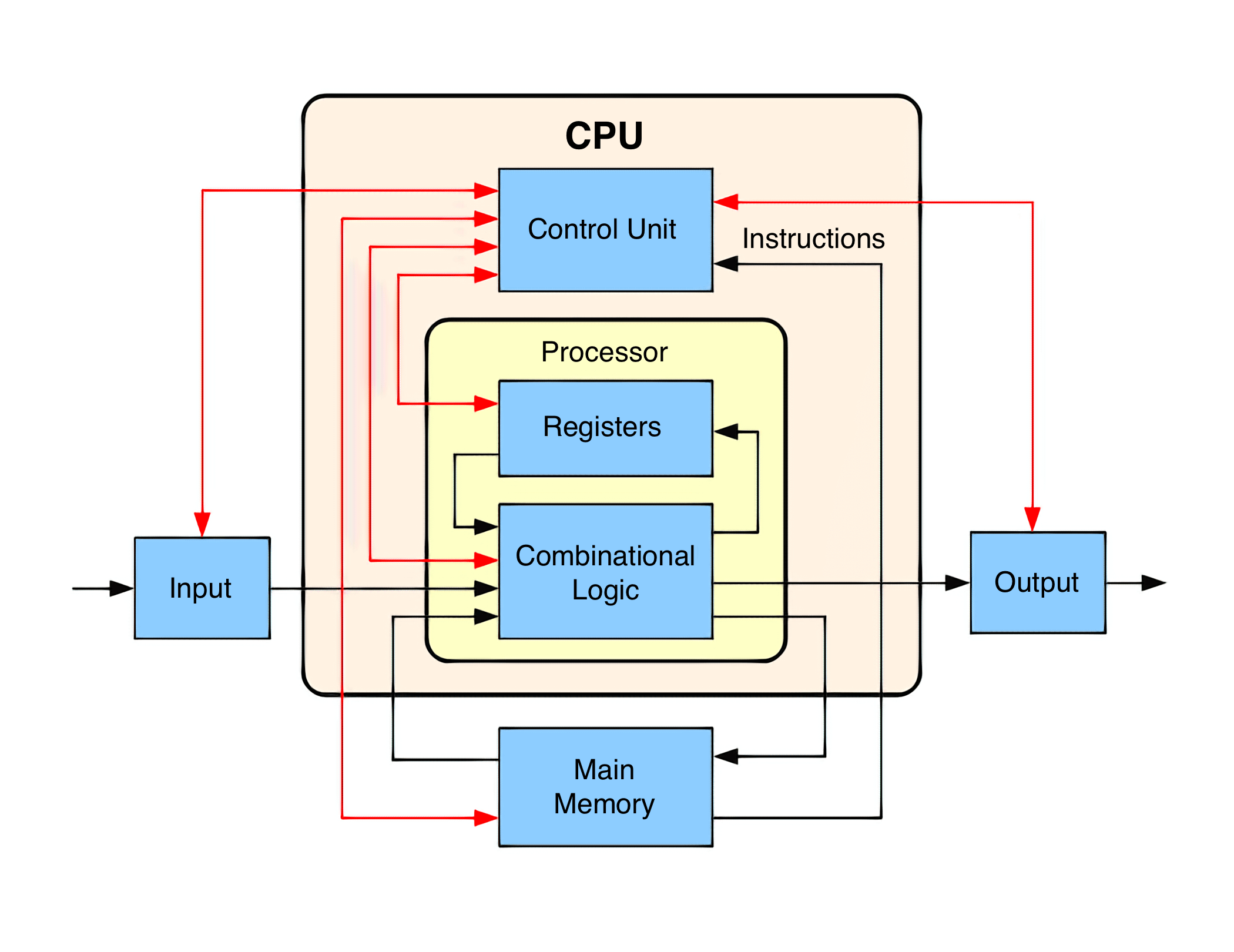
Les parties d'une CPU peuvent être divisées en deux: l'unité de contrôle et le chemin de données. Imaginez une voiture de train. Le moteur est ce qui déplace le train, mais le conducteur tire les leviers dans les coulisses et contrôle les différents aspects du moteur. Un CPU est la même manière.
Le chemin de données est comme le moteur et comme son nom l'indique, est le chemin où les données circulent au fur et à mesure qu'elles sont traitées. Le chemin de données reçoit les entrées, les traite et les envoie au bon endroit lorsqu'elles sont terminées. L'unité de contrôle indique au datapath comment fonctionner comme le conducteur du train. En fonction des instructions, le chemin de données achemine les signaux vers différents composants, active et désactive différentes parties du chemin de données et surveille l'état du processeur.
Le cycle d'instruction – Fetch
La première chose que notre CPU doit faire est de déterminer quelles instructions exécuter ensuite et de les transférer de la mémoire dans le CPU. Les instructions sont produites par un compilateur et sont spécifiques à l'ISA du CPU. Les ISA partageront les types d'instructions les plus courants comme charger, stocker, ajouter, soustraire, etc., mais il existe de nombreux types d'instructions spéciales supplémentaires propres à chaque ISA. L'unité de contrôle saura quels signaux doivent être acheminés pour chaque type d'instruction.
Lorsque vous exécutez un .exe sous Windows par exemple, le code de ce programme est déplacé en mémoire et le processeur est informé de l'adresse à laquelle la première instruction commence. La CPU maintient toujours un registre interne qui contient l'emplacement mémoire de la prochaine instruction à exécuter. C'est ce qu'on appelle le compteur de programmes (PC).
Une fois qu'il sait par où commencer, la première étape du cycle d'instruction consiste à obtenir cette instruction. Cela déplace l'instruction de la mémoire dans le registre d'instructions du CPU et est connue sous le nom de Récupérer étape. De manière réaliste, l'instruction est probablement déjà dans le cache du processeur, mais nous couvrirons ces détails un peu.
Le cycle d'instruction – décoder
Lorsque le CPU a une instruction, il doit déterminer précisément de quel type d'instruction il s'agit. C'est ce qu'on appelle le Décoder étape. Chaque instruction aura un certain ensemble de bits appelé Opcode qui indique au CPU comment l'interpréter. Cela est similaire à la façon dont différentes extensions de fichier sont utilisées pour indiquer à un ordinateur comment interpréter un fichier. Par exemple, .jpg et .png sont tous deux des fichiers image, mais ils organisent les données d'une manière différente, de sorte que l'ordinateur doit connaître le type afin de les interpréter correctement.
Selon la complexité de l'ISA, la partie de décodage d'instructions du CPU peut devenir complexe. Un ISA comme RISC-V ne peut avoir que quelques dizaines d'instructions alors que x86 en a des milliers. Sur un processeur Intel x86 typique, le processus de décodage est l'un des plus difficiles et prend beaucoup de place. Les types d'instructions les plus courants qu'un processeur décode sont les instructions de mémoire, d'arithmétique ou de branchement.
3 principaux types d'instructions
Une instruction de mémoire peut être quelque chose comme "lire la valeur de l'adresse de mémoire 1234 dans la valeur A" ou "écrire la valeur B dans l'adresse de mémoire 5678". Une instruction arithmétique pourrait être quelque chose comme "ajouter la valeur A à la valeur B et stocker le résultat dans la valeur C". Une instruction de branchement pourrait être quelque chose comme "exécuter ce code si la valeur C est positive ou exécuter ce code si la valeur C est négative". Un programme typique peut les enchaîner pour trouver quelque chose comme "ajouter la valeur à l'adresse mémoire 1234 à la valeur à l'adresse mémoire 5678 et la stocker dans l'adresse mémoire 4321 si le résultat est positif ou à l'adresse 8765 si le résultat est négatif" .
Avant de commencer à exécuter l'instruction que nous venons de décoder, nous devons faire une pause pendant un moment pour parler des registres.
Un processeur a quelques morceaux de mémoire très petits mais très rapides appelés registres. Sur un processeur 64 bits, ceux-ci contiendraient 64 bits chacun et il pourrait y en avoir quelques dizaines pour le cœur. Celles-ci sont utilisées pour stocker des valeurs actuellement utilisées et peuvent être considérées comme quelque chose comme un cache L0. Dans les exemples d'instructions ci-dessus, les valeurs A, B et C seraient toutes stockées dans des registres.
L'ALU
Revenons maintenant à l'étape d'exécution. Ce sera différent pour les 3 types d'instructions dont nous avons parlé ci-dessus, nous allons donc couvrir chacun séparément.
Commençons par des instructions arithmétiques car elles sont les plus faciles à comprendre. Ce type d'instructions est introduit dans une unité de journal arithmétique (ALU) pour le traitement. Une ALU est un circuit qui prend généralement deux entrées avec un signal de commande et produit un résultat.
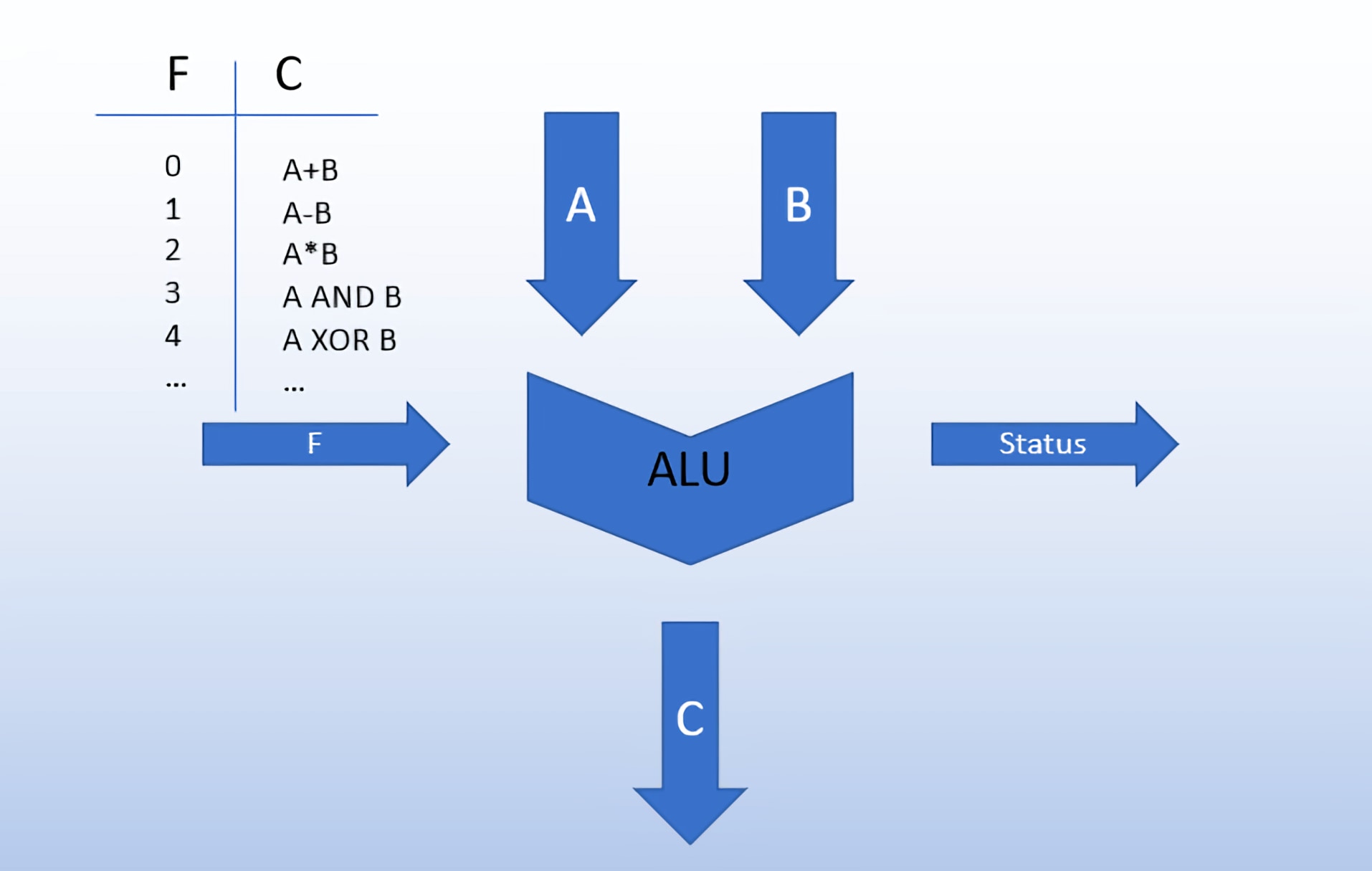
Imaginez une calculatrice de base que vous avez utilisée au collège. Pour effectuer une opération, vous saisissez les deux numéros d'entrée ainsi que le type d'opération que vous souhaitez effectuer. La calculatrice effectue le calcul et produit le résultat. Dans le cas de l'ALU de notre CPU, le type d'opération est déterminé par l'opcode de l'instruction et l'unité de contrôle enverra cela à l'ALU. En plus de l'arithmétique de base, les ALU peuvent également effectuer des opérations au niveau du bit comme AND, OR, NOT et XOR. L'ALU affichera également des informations d'état pour l'unité de contrôle sur le calcul qu'elle vient de terminer. Cela pourrait inclure des choses comme si le résultat était positif, négatif, nul ou avait un débordement.
Une ALU est la plus associée aux opérations arithmétiques, mais elle peut également être utilisée pour des instructions de mémoire ou de branchement. Par exemple, le CPU peut avoir besoin de calculer une adresse mémoire donnée comme résultat d'une opération arithmétique précédente. Il peut également être nécessaire de calculer le décalage à ajouter au compteur de programme requis par une instruction de branchement. Quelque chose comme "si le résultat précédent était négatif, passez à 20 instructions".
Instructions de mémoire et hiérarchie
Pour les instructions sur la mémoire, nous devons comprendre un concept appelé Hiérarchie de la mémoire. Cela représente la relation entre les caches, la RAM et le stockage principal. Lorsqu'un processeur reçoit une instruction de mémoire pour un élément de données qu'il n'a pas encore localement dans ses registres, il descend la hiérarchie de la mémoire jusqu'à ce qu'il le trouve. La plupart des processeurs modernes contiennent trois niveaux de cache: L1, L2 et L3. Le premier emplacement que le CPU vérifiera est le cache L1. C'est le plus petit et le plus rapide des trois niveaux de cache. Le cache L1 est généralement divisé en une partie pour les données et une partie pour les instructions. N'oubliez pas que les instructions doivent être extraites de la mémoire, tout comme les données.
Un cache L1 typique peut représenter quelques centaines de Ko. Si le CPU ne trouve pas ce qu'il recherche dans le cache L1, il vérifiera le cache L2. Cela peut être de l'ordre de quelques Mo. L'étape suivante est le cache L3 qui peut faire quelques dizaines de Mo. Si le CPU ne trouve pas les données dont il a besoin dans le cache L3, il ira à la RAM et enfin au stockage principal. Au fur et à mesure que nous descendons chaque étape, l'espace disponible augmente d'environ un ordre de grandeur, tout comme la latence.
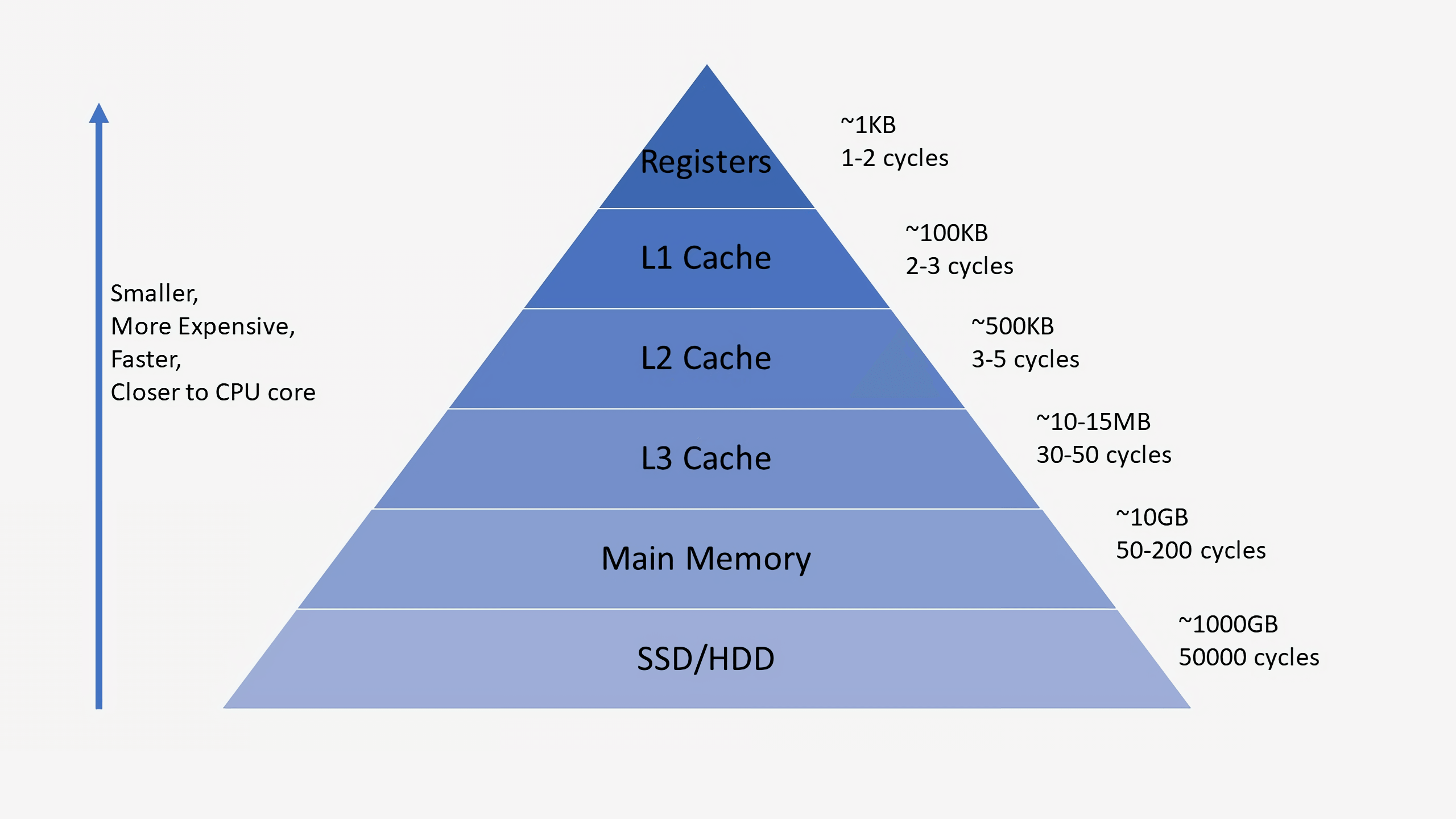
Une fois que le CPU a trouvé les données, il les affichera dans la hiérarchie afin que le CPU puisse y accéder rapidement si nécessaire à l'avenir. Il y a beaucoup d'étapes ici, mais cela garantit que le processeur a un accès rapide aux données dont il a besoin. Par exemple, le CPU peut lire à partir de ses registres internes en un ou deux cycles, L1 en une poignée de cycles, L2 en une dizaine de cycles et le L3 en quelques dizaines. S'il doit aller dans la mémoire ou dans le stockage principal, cela peut prendre des dizaines de milliers voire des millions de cycles. Selon le système, chaque cœur aura probablement son propre cache L1 privé, partagera un L2 avec un autre cœur et partagera un L3 entre les groupes de quatre cœurs ou plus. Nous parlerons plus en détail des processeurs multicœurs plus loin dans cet article.
Instructions de branchement et de saut
Le dernier des trois principaux types d'instructions est l'instruction de branchement. Les programmes modernes sautent tout le temps et un CPU exécutera rarement plus d'une douzaine d'instructions contiguës sans branche. Les instructions de branchement proviennent d'éléments de programmation tels que les instructions if, les boucles for et les instructions return. Ils sont tous utilisés pour interrompre l'exécution du programme et passer à une autre partie du code. Il existe également des instructions de saut qui sont des instructions de branchement qui sont toujours prises.
Les branches conditionnelles sont particulièrement délicates pour un processeur car il peut exécuter plusieurs instructions à la fois et ne peut déterminer le résultat d'une branche qu'après son démarrage sur les instructions suivantes.
Afin de bien comprendre pourquoi il s'agit d'un problème, nous devrons prendre un autre détournement et parler de pipelining. Chaque étape du cycle d'instruction peut prendre plusieurs cycles. Cela signifie que pendant qu'une instruction est récupérée, l'ALU serait sinon resté inactif. Pour maximiser l'efficacité d'un processeur, nous divisons chaque étape dans un processus appelé pipelining.
La façon classique de comprendre cela consiste à faire une analogie avec la lessive. Vous avez deux charges à faire et le lavage et le séchage prennent chacun une heure. Vous pouvez placer la première charge dans la laveuse puis la sécheuse une fois terminée, puis démarrer la deuxième charge. Cela prendrait quatre heures. Cependant, si vous divisez le travail et commencez le lavage de la deuxième charge pendant que la première charge sèche, vous pouvez effectuer les deux charges en trois heures. La réduction d'une heure varie en fonction du nombre de charges que vous avez et du nombre de laveuses et sécheuses. Il faut toujours deux heures pour effectuer une charge individuelle, mais le chevauchement augmente le débit total de 0,5 charge / heure à 0,75 charge / heure.
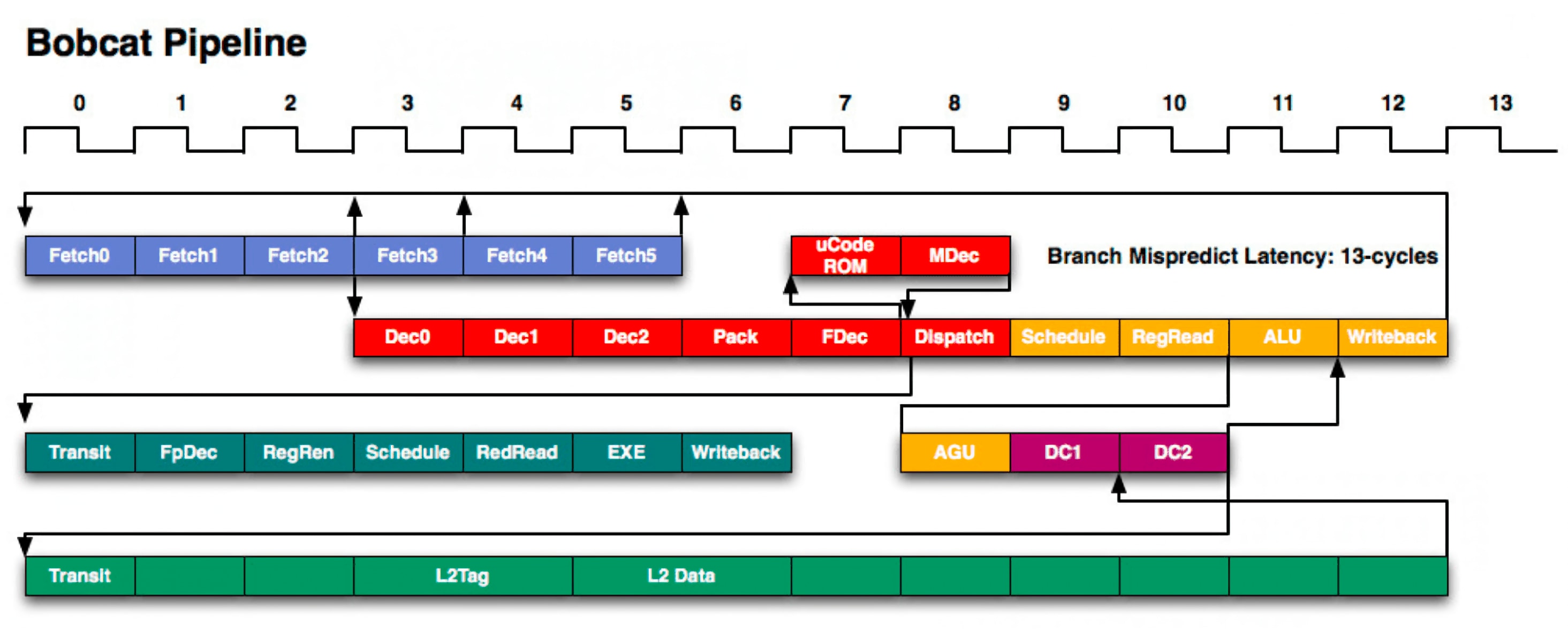
Les processeurs utilisent cette même méthode pour améliorer le débit des instructions. Un processeur ARM ou x86 moderne peut avoir plus de 20 étages de pipeline, ce qui signifie qu'à tout moment, ce cœur traite plus de 20 instructions différentes à la fois. Chaque conception est unique, mais une division d'échantillon peut être de 4 cycles pour l'extraction, 6 cycles pour le décodage, 3 cycles pour l'exécution et 7 cycles pour la mise à jour des résultats en mémoire.
Retour aux succursales, j'espère que vous pourrez commencer à voir le problème. Si nous ne savons pas qu'une instruction est une branche jusqu'au cycle 10, nous aurons déjà commencé à exécuter 9 nouvelles instructions qui peuvent être invalides si la branche est prise. Pour contourner ce problème, les processeurs ont des structures très complexes appelées prédicteurs de branche. Ils utilisent des concepts similaires issus du machine learning pour essayer de deviner si une branche sera prise ou non. Les subtilités des prédicteurs de branche sont bien au-delà de la portée de cet article, mais à un niveau de base, ils suivent le statut des branches précédentes pour savoir si une branche à venir est susceptible d'être prise ou non. Les prédicteurs de branche modernes peuvent avoir une précision de 95% ou plus.
Une fois que le résultat de la branche est connu avec certitude (il a terminé cette étape du pipeline), le compteur de programme sera mis à jour et la CPU continuera d'exécuter l'instruction suivante. Si la branche a été mal prédite, le CPU jettera toutes les instructions après la branche qu'il a commencé par erreur à exécuter et redémarrera à partir du bon endroit.
Exécution dans le désordre
Maintenant que nous savons comment exécuter les trois types d'instructions les plus courants, examinons certaines des fonctionnalités les plus avancées d'un CPU. Pratiquement tous les processeurs modernes n'exécutent pas réellement les instructions dans l'ordre dans lequel elles sont reçues. Un paradigme appelé exécution dans le désordre est utilisé pour minimiser les temps d'arrêt en attendant la fin des autres instructions.
Si un CPU sait qu'une instruction à venir nécessite des données qui ne seront pas prêtes à temps, il peut changer l'ordre des instructions et apporter une instruction indépendante plus tard dans le programme pendant qu'il attend. Cette réorganisation des instructions est un outil extrêmement puissant, mais elle est loin d'être la seule astuce que les CPU utilisent.
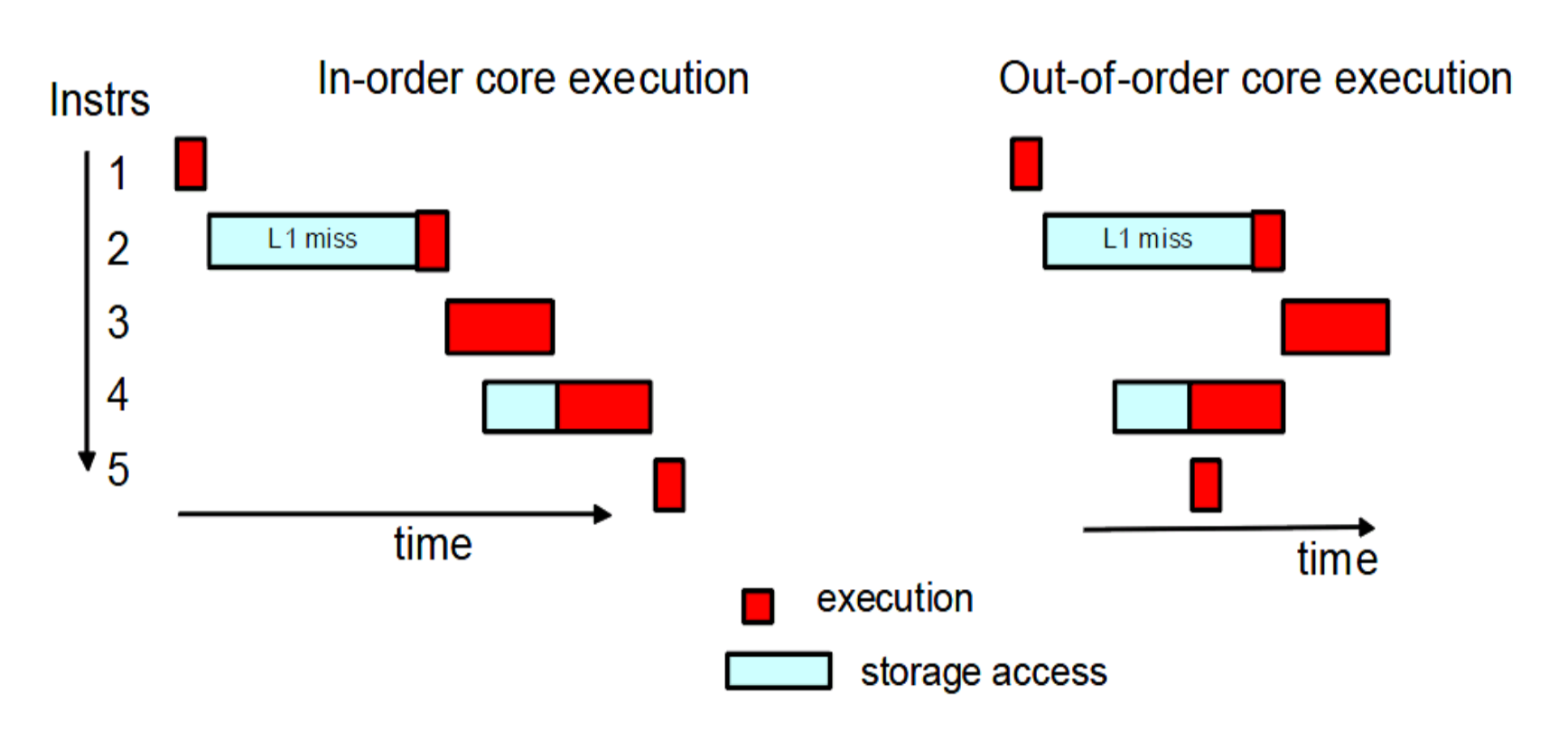
Une autre fonctionnalité améliorant les performances est appelée prélecture. Si vous deviez chronométrer le temps qu'il faut pour qu'une instruction aléatoire se termine du début à la fin, vous constateriez que l'accès à la mémoire prend la plupart du temps. Un préfiltre est une unité de la CPU qui essaie de voir les futures instructions et les données dont elles auront besoin. S'il en voit un qui nécessite des données que le CPU n'a pas mises en cache, il va atteindre la RAM et récupérer ces données dans le cache. D'où le nom de pré-extraction.
Accélérateurs et avenir
Les accélérateurs spécifiques aux tâches commencent à être inclus dans les CPU. Ce sont des circuits dont tout le travail consiste à effectuer une petite tâche aussi rapidement que possible. Cela peut inclure le chiffrement, l'encodage multimédia ou l'apprentissage automatique.
Le CPU peut faire ces choses tout seul, mais il est beaucoup plus efficace d'avoir une unité qui leur est dédiée. Un bon exemple de cela est la carte graphique intégrée par rapport à un GPU dédié. Certes, le CPU peut effectuer les calculs nécessaires au traitement graphique, mais le fait d'avoir une unité dédiée pour eux offre de meilleures performances. Avec la montée en puissance des accélérateurs, le cœur même d'un CPU ne peut occuper qu'une petite fraction de la puce.
L'image ci-dessous montre un processeur Intel datant de plusieurs années. La majeure partie de l'espace est occupée par les cœurs et le cache. La deuxième image ci-dessous est pour une puce AMD beaucoup plus récente. La majeure partie de l'espace est occupée par des composants autres que les noyaux.
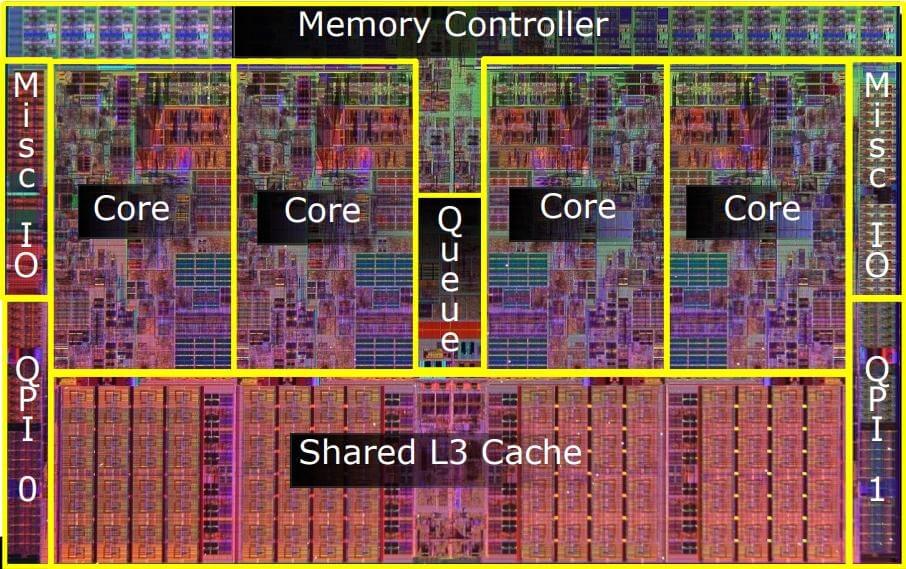
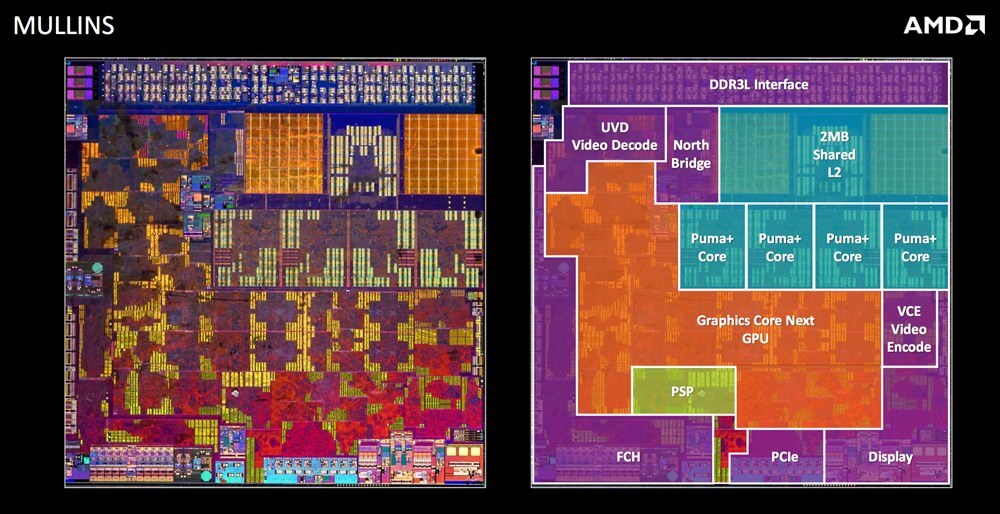
Going Multicore
La dernière caractéristique majeure à couvrir est de savoir comment nous pouvons connecter un ensemble de processeurs individuels ensemble pour former un processeur multicœur. Ce n'est pas aussi simple que de simplement mettre plusieurs copies de la conception monocœur dont nous avons parlé plus tôt. Tout comme il n'y a pas de moyen facile de transformer un programme à un seul thread en un programme à plusieurs threads, le même concept s'applique au matériel. Les problèmes proviennent de la dépendance entre les cœurs.
Par exemple, pour une conception à 4 cœurs, le processeur doit pouvoir émettre des instructions 4 fois plus rapidement. Il a également besoin de quatre interfaces distinctes pour la mémoire. Avec plusieurs entités opérant sur potentiellement les mêmes données, des problèmes tels que la cohérence et la cohérence doivent être résolus. Si deux cœurs étaient tous les deux des instructions de traitement utilisant les mêmes données, comment savent-ils qui a la bonne valeur? Et si un noyau modifiait les données mais qu'il n'atteignait pas l'autre noyau à temps pour qu'il s'exécute? Puisqu'ils ont des caches séparés qui peuvent stocker des données qui se chevauchent, des algorithmes et des contrôleurs complexes doivent être utilisés pour supprimer ces conflits.
Une bonne prédiction de branche est également extrêmement importante car le nombre de cœurs dans un processeur augmente. Plus les cœurs exécutent des instructions simultanément, plus la probabilité que l'un d'eux traite une instruction de branchement est élevée. Cela signifie que le flux d'instructions peut changer à tout moment.
En règle générale, des cœurs séparés traitent les flux d'instructions de différents threads. Cela permet de réduire la dépendance entre les cœurs. C'est pourquoi si vous vérifiez le Gestionnaire des tâches, vous verrez souvent un cœur travailler dur et les autres fonctionner à peine. De nombreux programmes ne sont pas conçus pour le multithreading. Il peut également y avoir certains cas où il est plus efficace de confier le travail à un seul noyau plutôt que de payer les frais généraux pour essayer de diviser le travail.
Conception physique
La plupart de cet article s'est concentré sur la conception architecturale d'un processeur, car c'est là que se situe la majeure partie de la complexité. Cependant, tout cela doit être créé dans le monde réel et cela ajoute un autre niveau de complexité.
Afin de synchroniser tous les composants à travers le processeur, un signal d'horloge est utilisé. Les processeurs modernes fonctionnent généralement entre 3,0 GHz et 5,0 GHz et cela n'a pas semblé changer au cours de la dernière décennie. À chacun de ces cycles, les milliards de transistors à l'intérieur d'une puce se mettent sous et hors tension.
Les horloges sont essentielles pour garantir qu'à chaque étape du pipeline, toutes les valeurs s'affichent au bon moment. L'horloge détermine le nombre d'instructions qu'un processeur peut traiter par seconde. L'augmentation de sa fréquence grâce à l'overclocking accélérera la puce, mais augmentera également la consommation d'énergie et la production de chaleur.

La chaleur est le pire ennemi d'un processeur. À mesure que l'électronique numérique chauffe, les transistors microscopiques peuvent commencer à se dégrader. Cela peut endommager une puce si la chaleur n'est pas éliminée. C'est pourquoi tous les CPU sont livrés avec des dissipateurs de chaleur. La puce de silicium réelle d'un CPU ne peut occuper que 20% de la surface d'un périphérique physique. L'augmentation de l'empreinte permet de répartir la chaleur plus uniformément sur un dissipateur thermique. Il permet également plus de broches pour l'interfaçage avec des composants externes.
Les processeurs modernes peuvent avoir un millier ou plus de broches d'entrée et de sortie à l'arrière. Une puce mobile ne peut avoir que quelques centaines de broches, car la plupart des composants informatiques se trouvent dans la puce. Quelle que soit la conception, environ la moitié d'entre eux sont consacrés à la fourniture d'énergie et le reste est utilisé pour la communication de données. Cela inclut la communication avec la RAM, le chipset, le stockage, les périphériques PCIe, etc. Avec des processeurs hautes performances consommant une centaine d'ampères ou plus à pleine charge, ils ont besoin de centaines de broches pour répartir uniformément le courant. Les broches sont généralement plaquées or pour améliorer la conductivité électrique. Différents fabricants utilisent différentes dispositions de broches dans leurs nombreuses gammes de produits.
Assembler le tout avec un exemple
Pour conclure, nous allons jeter un coup d'œil à la conception d'un processeur Intel Core 2. Cela remonte à 2006, donc certaines pièces peuvent être obsolètes, mais les détails sur les nouveaux modèles ne sont pas disponibles.
En commençant par le haut, nous avons le cache d'instructions et ITLB. Le Translation Lookaside Buffer (TLB) est utilisé pour aider le CPU à savoir où en mémoire aller pour trouver les instructions dont il a besoin. Ces instructions sont stockées dans un cache d'instructions L1 et sont ensuite envoyées dans un pré-décodeur. L'architecture x86 est extrêmement complexe et dense, il y a donc de nombreuses étapes de décodage. Pendant ce temps, le prédicteur de branche et le préfiltre recherchent tous deux des problèmes potentiels causés par les instructions entrantes.
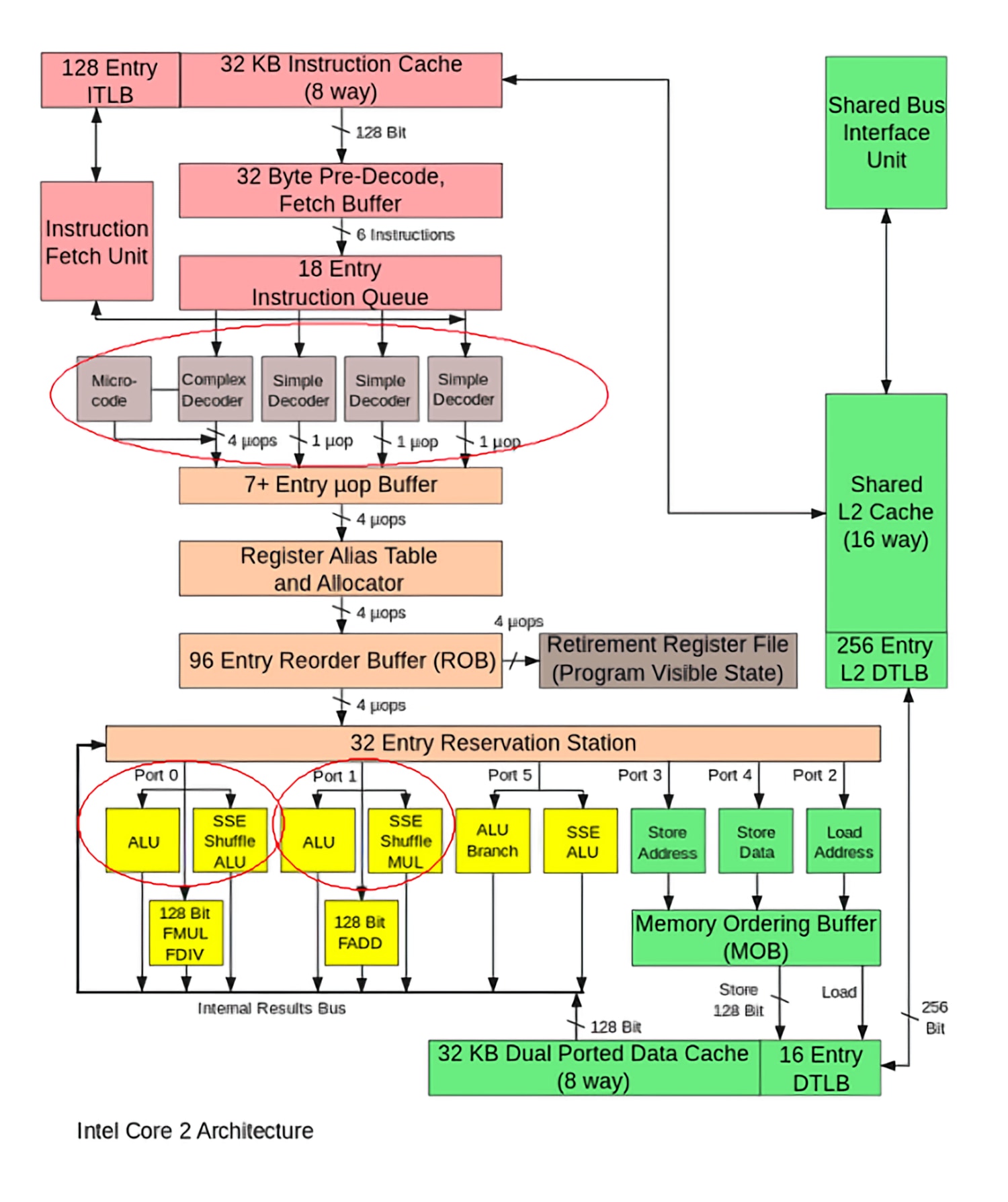
De là, les instructions sont envoyées dans une file d'attente d'instructions. Rappelez-vous comment la conception hors service permet à une CPU d'exécuter des instructions et de choisir la plus opportune à exécuter. Cette file d'attente contient les instructions actuelles qu'un processeur envisage. Une fois que la CPU sait quelle instruction serait la meilleure à exécuter, elle est ensuite décodée en micro-opérations. Alors qu'une instruction peut contenir une tâche complexe pour le CPU, les micro-opérations sont des tâches granulaires qui sont plus facilement interprétées par le CPU.
Ces instructions vont ensuite dans la table des alias de registre, le ROB et la station de réservation. La fonction exacte de ces trois composantes est un peu complexe (pensez aux cours universitaires de deuxième cycle), mais elles sont utilisées dans le processus hors service pour aider à gérer les dépendances entre les instructions.
Un seul «cœur» aura en fait de nombreux ALU et ports mémoire. Les opérations entrantes sont placées dans la station de réservation jusqu'à ce qu'un ALU ou un port mémoire soit disponible pour utilisation. Une fois le composant requis disponible, l'instruction sera traitée avec l'aide du cache de données L1. Les résultats de sortie seront stockés et le CPU est maintenant prêt à démarrer sur l'instruction suivante. C'est à peu près ça!
Bien que cet article ne soit pas censé être un guide définitif sur le fonctionnement exact de chaque processeur, il devrait vous donner une bonne idée de leur fonctionnement interne et de leur complexité. Franchement, personne en dehors d'AMD et d'Intel ne sait réellement comment fonctionnent leurs processeurs. Chaque section de cet article représente un domaine entier de recherche et développement, donc les informations présentées ici ne font qu'effleurer la surface.
Continue de lire
Si vous souhaitez en savoir plus sur la conception des différents composants abordés dans cet article, consultez la partie 2 de notre série de conception de CPU. Si vous êtes plus intéressé à apprendre comment un processeur est physiquement réduit au niveau du transistor et du silicium, consultez la partie 3.